
شناسایی علائم راهنمایی و رانندگی و عابر پیاده و بررسی آن ها:
در بخش های ۴ و ۵ شناسایی خطوط و هدایت ماشین رو بررسی کردیم.یک ماشین خودمختار واقعی همیشه باید از چیزایی که دور و برش هستند باخبر باشه.توی این بخش یک مطلب بسیار مهم دیگه یعنی شناسایی علائم و عابرین پیاده و اداره کردن آنهاست رو بررسی میکنیم.این ویژگی توی هیچ کدوم از ماشین های سال ۲۰۱۹ وجود نداره,به جز تسلا شاید.ما توی این بخش به ماشین خودران عمیق آموزش میدیم که اون علائم رو در زمان حقیقی شناسایی و بهشون واکنش نشون بده .علاوه بر این ما از شتاب دهنده Google Edge TPU که در اوایل ۲۰۱۹ بیرون اومده استفاده میکنیم.
قابل توجه اونایی که سخت افزاری رو تهیه نکردن:برای نیمه اول با یک کامپیوتر میتونید کار ها رو انجام بدید چون که مدلمون رو در cloud آموزش میدیم.
درک: شناسایی علائم راهنمایی رانندگی و عابر پیاده
شناسایی اشیا در بینایی کامپیوتر و یادگیری عمیق مساله بسیار مهمی هستش.دو تا جز در مدل تشخیص شی به نام های شبکه عصبی پایه و شبکه عصبی شناسایی وجود دارند.
در ابتدا شبکه های عصبی پایه شبکه های کانولوشنی هستند که ویژگی هایی رو(از ویژگی های سطح پایین گرفته تا سطح بالا) مانند خطوط,زوایا,صورت,انسان,چراغ راهنمایی , … را از تصاویر استخراج میکنند. LeNet, InceptionNet(شناخته شده به عنوان. GoogleNet), ResNet, VGG-Net, AlexNet, and MobileNet شبکه های پایه معروف هستند.اگر دوست دارید که درباره تفاوت های بین این شبکه ها اطلاعات بیشتری داشته باشید روی لینک کلیک کنید!
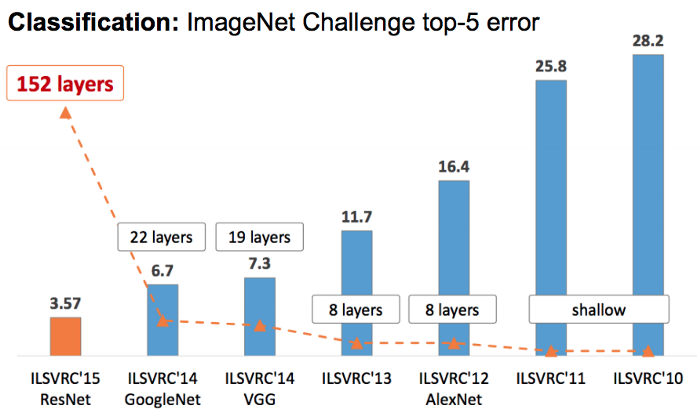
سپس شبکه های عصبی شناسایی به انتهایی یک شبکه عصبی پایه میچسبند و برای شناسایی فوری اشیا چندگانه از یک عکس تکی با کمک ویژگی های استخراج شده استفاده میشوند.بعضی از شبکه های شناسایی محبوب عبارت اند از SSD,R-CNN(ناحیه با ویژگی های شبکه عصبی کانولوشن),Faster R-CNN,YOLO.اگر میخواین درباره این ها بیشتر بدونید روی لینک کلیک کنید:)


یک مدل تشخیص شی معمولا به عنوان ترکیبی از انواع شبکه عصبی پایه و شناسایی اش نام گذاری میشه.برای مثال مدل های “MobileNet SSD” – “Inception SSD”-“ResNet Faster R-CNN”.
در نهایت برای مدل های شناسایی از پیش آمورش داده شده,نام مدل شامل نوع مجموعه تصاویری که با آن آموزش داده شده هم هست.از جمله مجموعه های معروف استفاده شده در آموزش دسته بندی و شناسایی تصاویر میشه به COCO dataset(شامل ۱۰۰ تا خانواده معمول اشیا)- Open Images dataset(۲۰۰۰۰ تا شی) و iNaturalist dataset(شامل ۲۰۰۰۰ نوع از گونه های حیوانات و موجودات) اشاره کرد.برای مثال مدل ssd_mobilenet_v2_coco از دومین ورژن MobileNet برای استخراج ویژگی ها,از SSD برای شناسایی اشیا و از پیش آموزش داده شده روی مجموعه COCO استفاده میکنه.
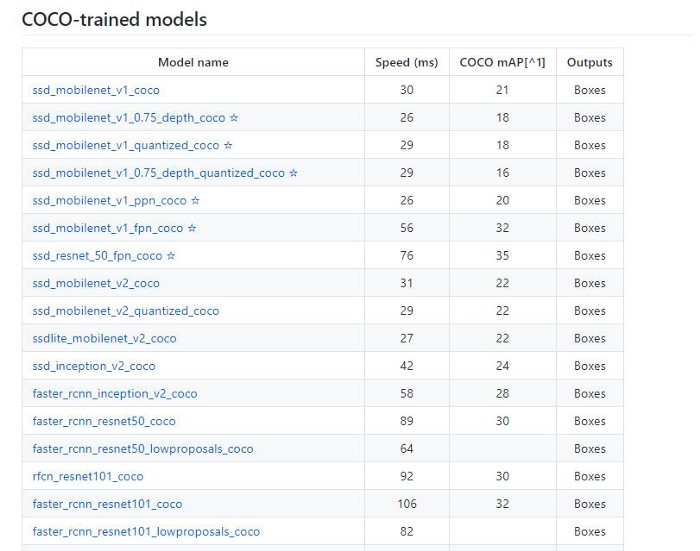
پیگیری کردن تمامی ترکیب های این مدل ها واقعا کار ساده ای نیست.اما گوگل یک لیست از مدل های از پیش آموزش داده شده با tensorflow منتشر کرده و شما میتونید با توجه به نیاز هاتون اونی که به دردتون میخوره رو دانلود کنید و به طور مستقیم در پروژه هاتون برای شناسایی استفاده کنید.

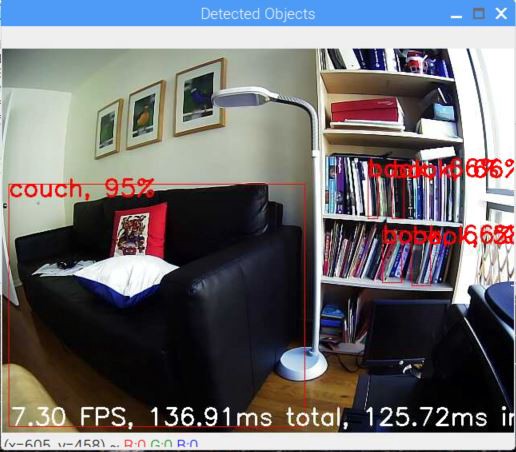
اگه یادتون باشه توی بخش سوم ما از مدل از پیش آموزش داده شده MobileNet SSD روی مجموعه داده COCO استفاده کردیم که کتاب های داخل کتاب خانه و مبل داخل پذیرایی رو شناسایی میکرد.
یادگیری انتقال(transfer learning):
هر چند که این آموزش درباره شناسایی علائم راهنمایی و رانندگی و عابران پیاده کوچک هستش و نه کتاب ها و مبل.اما نمیخوایم وقتمون رو صرف جمع کردن هزارتا عکس هفته ها و ماه ها باری ساختن و آموزش مدل از اول بکنیم.کاری که میتونیم بکنیم استفاده از یادگیری انتقال هست که با پارامتر های یک مدل از پیش آموزش داده شده شروع میشه و حدود ۵۰-۱۰۰ عکس و لیبل بهش میدیم و فقط چند ساعت برای یادگیری قسمت های شبکه عصبی شناسایی صرف میکنه.فکر پشتش اینه که در یک مدل از پیش آموزش داده شده لایه های پایه CNN از اونجایی که روی تعداد زیادی از انواع تصاویر آموزش داده شدن توی شناسایی ویژگی های تصویر به خوبی میتونن عمل کنن.تفاوتش اینه که الان به جای ۱۰۰-۱۰۰۰ تا نوع داده فقط حدود ۶ نوع داده داریم.


آموزش دادن مدل:
چندین گام در آموزش مدل وجود دارند:
۱.جمع آوری تصاویر و لیبل ها(min20–۳۰)
۲.انتخاب مدل
۳.یادگیری انتقال/آموزش مدل(۳–۴ hours)
۵.ذخیره خروجی مدل در فرمت Edge TPU (5-min)
۶.اجرای نتایج مدل روی Raspberry Pi
جمع آوری تصاویر و لیبل ها

۶ نوع داده به نام های چراغ سبز-چراغ قرمز-علامت توقف-محدودیت سرعت ۴۰ Mph-محدودیت سرعت ۲۵ Mph و چند تا لگو که نشون دهنده عابران پیاده هستد.۵۰ تا عکس مشابه به این تصویر میگیریم و در هر تصویر به طور رندوم جای اشیا رو تغییر میدیم.
بعدش هر عکس رو با چهرضلعی مرز بندی لیبل گذاری میکنیم(شکل پایین) .به نظر میرسه که حدود چندین ساعت طول میکشه اما یک ابزار رایگان برای این کار به اسم labelImg وجود داره که این کار طاقت فرسا رو به شدت راحت میکنه.تنها کاری که باید بکنیم اینه که لیبل گذاری رو برای تصاویر training در جایی که ذخیرشون کردیم انجام بدیم.برای هر تصویر یک چهار ضلعی برای هر یک از اشیا مشخص میکنیم و نوع شی رو انتخاب میکنیم(اگر نوعش جدید باشه به سادگی میتونیم اون نوع رو بسازیم).اگر از shortcut های کیبورد استفاده میکنید حدود ۲۰-۳۰ ثانیه صرف هر عکس میشه و برای هر ۵۰ تا عکس تقریبا ۲۰ دقیقه فقط طول میکشه.
بعدش به طور رندوم عکس ها(با لیبل فایل xml شون) را برای قرار گرفتن در مجموعه یادگیری و یا تست جدا میکنیم.

انتخاب مدل:
ازاونجایی که در Raspberry Pi قدرت محاسبه کمی داریم باید مدلی رو انتخاب کنیم که به نسبت هم سریع باشه و هم با دقت.بعد از آزمون و خطای چند تا مدل به این نتیجه رسیدیم که مدل MobileNet v2 SSD COCO به طور بهینه هم سرعت و هم دقت خوبی داره.علاوه بر این برای اینکه مدلمون بتونه در شتاب دهنده Edge TPU کار کنه باید از مدل MobileNet v2 SSD COCO Quantized استفاده کنیم.Quantization یک روش برای سریع تر کردن اجرای نتایج مدل توسط ذخیره پارامتر های مدل نه به طور مقادیر double بلکه به صورت مقادیر integral هستش(با مقدار کمی کاهش در مقدار دقت).سخت افزار Edge TPU بهینه سازی شده و فقط مدل های quantized روی اون اجرا میشوند.این مقاله خیلی عمیق Edge TPU رو بررسی میکنه و کسایی که علاقه مندند خوبه که مطالعش کنند.
یادگیری انتقال/آموزش مدل/تست کردن:
در این مرحله دوباره از google colab استفاده میکنیم.این بخش برپایه آموزش فوق العاده Chengwei’s در مبحث “How to train an object detection model easy for free”است.
فرق مال ما اینه که ما باید با شتاب دهنده Edge TPU اون رو روی Raspberry Pi اجرا کنیم.چون که دفترچه jupiter و خروجیش بسیار طولانی هستش سعی میکنیم یه سری از بخش های اصلی و مهم رو در زیر بیاریم.کد کامل توی این لینک وجود داره که شامل توضیحات کامل هستش.
ایجاد محیط آموزش:
# If you forked the repository, you can replace the link.
repo_url = 'https://github.com/dctian/DeepPiCar'
# Number of training steps.
num_steps = 1000 # 200000
# Number of evaluation steps.
num_eval_steps = 50
# model configs are from Model Zoo github:
MODELS_CONFIG = {
#http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_quantized_300x300_coco14_sync_2018_07_18.tar.gz
'ssd_mobilenet_v1_quantized': {
'model_name': 'ssd_mobilenet_v1_quantized_300x300_coco14_sync_2018_07_18',
'pipeline_file': 'ssd_mobilenet_v1_quantized_300x300_coco14_sync.config',
'batch_size': 12
},
#http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v2_quantized_300x300_coco_2019_01_03.tar.gz
'ssd_mobilenet_v2_quantized': {
'model_name': 'ssd_mobilenet_v2_quantized_300x300_coco_2019_01_03',
'pipeline_file': 'ssd_mobilenet_v2_quantized_300x300_coco.config',
'batch_size': 12
},
}
# Pick the model you want to use
selected_model = 'ssd_mobilenet_v2_quantized'
# Name of the object detection model to use.
MODEL = MODELS_CONFIG[selected_model]['model_name']
# Name of the pipline file in tensorflow object detection API.
pipeline_file = MODELS_CONFIG[selected_model]['pipeline_file']
# Training batch size fits in Colabe's Tesla K80 GPU memory for selected model.
batch_size = MODELS_CONFIG[selected_model]['batch_size']
!git clone https://github.com/dctian/DeepPiCar
%cd /content
!git clone --quiet https://github.com/tensorflow/models.git
!apt-get install -qq protobuf-compiler python-pil python-lxml python-tk
!pip install -q Cython contextlib2 pillow lxml matplotlib
!pip install -q pycocotools
%cd /content/models/research
!protoc object_detection/protos/*.proto --python_out=.
import os
os.environ['PYTHONPATH'] += ':/content/models/research/:/content/models/research/slim/
کد بالا مدل MobileNet v2 SSD COCO Quantized رو انتخاب میکنه و مدل های آموزش داده شده را از TensorFlow GitHub دریافت میکنه.این بخش برای این طراحی شده که در صورت انتخاب یک مدل شناسایی دیگه انعطاف پذیر باشه.
آماده کردن اطلاعات آموزش:
repo_dir_path = '/content/DeepPiCar'
%cd {repo_dir_path}/models/object_detection
# Convert train folder annotation xml files to a single csv file,
# generate the `label_map.pbtxt` file to `data/` directory as well.
!python code/xml_to_csv.py -i data/images/train -o data/annotations/train_labels.csv -l data/annotations
# Convert test folder annotation xml files to a single csv.
!python code/xml_to_csv.py -i data/images/test -o data/annotations/test_labels.csv
# Generate `train.record`
!python code/generate_tfrecord.py --csv_input=data/annotations/train_labels.csv --output_path=data/annotations/train.record --img_path=data/images/train --label_map data/annotations/label_map.pbtxt
# Generate `test.record`
!python code/generate_tfrecord.py --csv_input=data/annotations/test_labels.csv --output_path=data/annotations/test.record --img_path=data/images/test --label_map data/annotations/label_map.pbtxt
کد بالا فایل های دارای لیبل xml تولید شده توسط LabelImg را به فرمت باینری (.record) تبدیل میکنند تا Tensorflow بتواند سریع تر پردازش کند.
دانلود مدل پیش آموزش داده شده:
MODEL_FILE = MODEL + '.tar.gz'
DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
DEST_DIR = '/content/models/research/pretrained_model'
if not (os.path.exists(MODEL_FILE)):
urllib.request.urlretrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
tar = tarfile.open(MODEL_FILE)
tar.extractall()
tar.close()
os.remove(MODEL_FILE)
if (os.path.exists(DEST_DIR)):
shutil.rmtree(DEST_DIR)
os.rename(MODEL, DEST_DIR)
fine_tune_checkpoint = os.path.join(DEST_DIR, "model.ckpt")
print(fine_tune_checkpoint)
'/content/models/research/pretrained_model/model.ckpt'
کد بالا فایل های مدل از پیش آموزش داده شده برای مدل ssd_mobilenet_v2_quantized_300x300_coco_2019_01_03 را دانلود میکند و ما فقط از فایل model.ckpt که مدل یادگیری انتقال رو به اون ارجاع میدیم استفاده میکنیم.
آموزش مدل:
num_steps = 2000
num_eval_steps = 50
model_dir = '/content/gdrive/My Drive/Colab Notebooks/TransferLearning/Training'
pipeline_file = 'ssd_mobilenet_v2_quantized_300x300_coco.config'
!python /content/models/research/object_detection/model_main.py \
--pipeline_config_path={pipeline_fname} \
--model_dir='{model_dir}' \
--alsologtostderr \
--num_train_steps={num_steps} \
--num_eval_steps={num_eval_steps}
این مرحله تقریبا ۳-۴ ساعت طول میکشه و بستگی به تعداد گام هایی(epoch) که برای آموزش طی میکند دارد.بعد از اینکه آموزش تمام شد یک سری فایل در model_dir میبینیم.ما به دنبال جدید ترین فایل model.ckpt-xxxx.meta هستیم.در اینجا ما ۲۰۰۰ تا epoch رو اجرا کردیم پس ما از فایل model.ckpt-2000.meta در model_dir استفاده میکنیم.
در طول آموزش میتونیم شاهد پیشرفت مقادیر loss و precision با TensorBoard باشیم.میتونیم ببینیم که برای مجموعه تست در طول آموزش مقدار loss در حال کاهش و precision در حال افزایش است که نشون دهنده ی اینه که مدل ما داره همونجوری که انتظارشو داشتیم عمل میکنه.
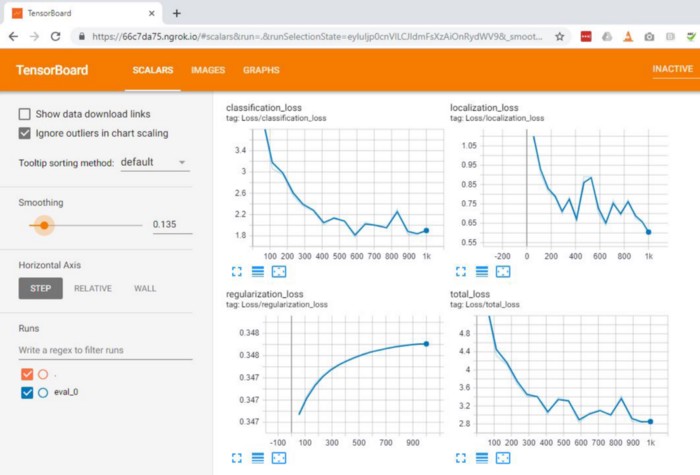
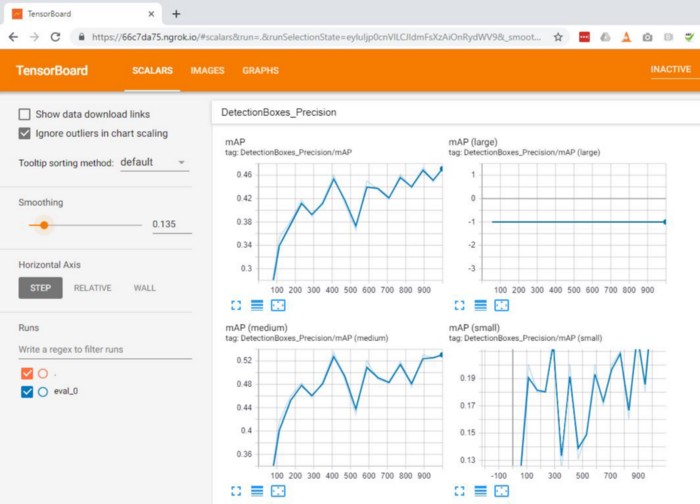
تست مدل آموزش داده شده:
بعد از آموزش یک سری تصاویر رو از مجموعه تست اجرا میکنیم.همونطوری که انتظارشو داشتیم تقریبا تمامی اشیا شناسایی شدند اما خب یک سری تصویر هم بودند که اشیادر اونها کمی دور بود و شناسایی نشدند.این برای ما قابل قبوله چون فقط میخواستیم اشیا نزدیک رو شناسایی کنیم تا بتونیم به اونها واکنش نشون بدیم.اون اشیا دور تر هنگامی که بهشون نزدیک بشیم بزرگتر و قابل شناسایی میشوند.

ذخیره فایل در فرمت Edge TPU :
وقتی که مدل آموزش داده شد باید مدل فایل meta رو در گراف نتیجه به فرمت Google ProtoBuf و سپس به فرمتی که شتاب دهنده Edge TPU بتواند آنها را بفهمد و پردازش کند export کنیم.کار به نسبت راحتی به نظر میاد اما در هنگام نوشتن, منابع آنلاین(شامل خود سایت Edge TPU)انقدر کمبود داشند که ساعات زیادی رو صرف تحقیق درباره پارامترها و دستورات صحیح برای تبدیل به فرمتی که Edge TPU بتونه ازشون استفاده کنه کردیم.
در نهایت به دستور های زیر رسیدیم:
# creates the frozen inference graph in fine_tune_model
# there is an "Incomplete shape" message. but we can safely ignore that.
!python /content/models/research/object_detection/export_inference_graph.py \
--input_type=image_tensor \
--pipeline_config_path={pipeline_fname} \
--output_directory='{output_directory}' \
--trained_checkpoint_prefix='{last_model_path}'
# create the tensorflow lite graph
!python /content/models/research/object_detection/export_tflite_ssd_graph.py \
--pipeline_config_path={pipeline_fname} \
--trained_checkpoint_prefix='{last_model_path}' \
--output_directory='{output_directory}' \
--add_postprocessing_op=true
# CONVERTING frozen graph to quantized TF Lite file...
!tflite_convert \
--output_file='{output_directory}/road_signs_quantized.tflite' \
--graph_def_file='{output_directory}/tflite_graph.pb' \
--inference_type=QUANTIZED_UINT8 \
--input_arrays='normalized_input_image_tensor' \
--output_arrays='TFLite_Detection_PostProcess,TFLite_Detection_PostProcess:1,TFLite_Detection_PostProcess:2,TFLite_Detection_PostProcess:3' \
--mean_values=128 \
--std_dev_values=128 \
--input_shapes=1,300,300,3 \
--change_concat_input_ranges=false \
--allow_nudging_weights_to_use_fast_gemm_kernel=true \
--allow_custom_ops
در نهایت یک فایل road_signs_quantized.tflite که برای موبایل و Raspberry Pi CPU مناسب هست که بتونن نتایج مدل رو اجرا کنند اما هنوز برای شتاب دهنده Edge TPU مناسب نیست.

ّبرای شتاب دهنده Edge TPU باید یک مرحله دیگه رو هم اجرا کنیم و اون هم اجرا کردن road_signs_quantized.tflite توسط Edge TPU Model Web Compiler.

بعد از اینکه road_signs_quantized.tflite را در کامپایلر اینترنتی آپلود کردیم میتوانیم فایل tfile دیگری را دانلود کنیم و به عنوان road_signs_quantized_edgetpu.tflite ذخیره اش کنیم و بعدش دیگه کاری نداریم!یه سری اخطار ممکنه داشه باشیم اما میتونن نادیده گرفته بشن.دقت کنین که ۹۹% مدل روی Edge TPU اجرا میشه که عالیهه.

تفاوت بین فایل _edgetpu.tflite و فایل عادی .tflite در این هست که با _edgetpu.tflite در ۹۹% مواقع نتایج و استنباطات مدل روی Edge TPU اجرا میشود.برای اهداف کاربردی در هر ثانیه ۲۰ تا عکس با کیفیت ۳۲۰×۲۴۰ رو میتونه با Edge TPU پردازش کنه(اما با CPU فقط در حدود یک عکس(۱ FPS)).20 FPS یعنی مقداری نزدیک زمان واقعی ماشین خودران و ارزش ۷۵$(هزینه Raspberry Pi — CPU +مدار) خرج شده رو داره.
برنامه ریزی و کنترل حرکت:
الان که ماشین خودران میتونه اشیا مقابلش رو شناسایی کنه باید بهش بگیم که باهاشون چی کار کنه.دو تا راه برای کنترل حرکت وجود داره بر قانون محور(rule-based) و end-to-end. قانون محور یعنی اینکه به ماشین باید دقیقا بگیم که وقتی که با شی روبرو شد چه کاری رو انجام بده.مثلا به ماشین بگیم که وقتی چراغ قرمز و یا عابر پیاده رو دید بایسته و یا وقتی که علامت محدودیت سرعت رو دید سرعتش رو کم کنه.
این با همون کاری که توی بخش چهار انجام دادیم یکسانه جایی که توسط چند خط کد به ماشین گفتیم چجوری مسیر یابی کنه.
روش end to end یک سری تصویر از ویدیو رانندگی راننده های خوب به ماشین میده و با استفاده از یادگیری عمیق به مرور یاد می گیره که چه جوری در مقابل چراغ قرمز و عابران پیاده بایسته و یا موقع دیدن تابلو محدودیت سرعت به مرور سرعتش کم کنه.این مشابه کاریه که توی بخش ۵ انجام دادیم.
در این بخش روش قانون محور را انتخاب کردیم چون اولا ما انسان ها خودمون به همین شکل رانندگی رو با یاد گرفتن قوانین مسیر یاد می گیریم و ثانیا پیاده سازیش راحت تره.
۶ نوع شی داریم (چراغ قرمز-چراغ سبز-محدودیت سرعت ۴۰mph-محدودیت سرعت ۲۵mph-علامت توقف-عابر پیاده) و چندتاشون رو توضیح میدیم که چه جوری میتونیم کنترلشون کنیم و میتونید پیاده سازی کامل رو در لینک های traffic_objects.py و object_on_road_processor.py ببینید.
قوانین خیلی ساده هستند:اگر شی ای شناسایی نشده در بالاترین سرعت مجاز حرکت کن.اگر شی ای شناسایی شده اون شی سرعت و محدودیت سرعت ماشین رو مشخص میکنه.برای مثال وقتی که چراغ قرمز رو میبینی که به نسبت نزدیک هستش توقف کن و وقتی که چراغ قرمزی نمیبینی به حرکت ادامه بده.
در ابتدا یک کلاس پایه TrafficObject داریم که نشان دهنده علائم رانندگی و یا عابران پیاده است.این کلاس شامل متد set_car_state(car_state) است.دیکشنری car_state دو تا متغیر به نام های speed و speed_limit داره که با متد تغییر میکنند.علاوه بر این ها یک متد کمکی به نام ()is_close_by دارد که چک میکند که آیا شی شناسایی شده به اندازه کافی نزدیک هست یا نه .(از اونجایی که دوربین تکی ما نمیتونه فاصله رو مشخص کنه با توجه به ارتفاع شی فاصله رو تقریب میزنیم.برای اینکه فاصله رو به صورت دقیق مشخص کنیم به Lidar یا سنسور اولتراسونیک و یا یک سیستم مانند دوربین به کار رفته در ماشین tesla احتیاج داریم )
class TrafficObject(object):
def set_car_state(self, car_state):
pass
@staticmethod
def is_close_by(obj, frame_height, min_height_pct=0.05):
# default: if a sign is 10% of the height of frame
obj_height = obj.bounding_box[1][1]-obj.bounding_box[0][1]
return obj_height / frame_height > min_height_pct
پیاده سازی چراغ قرمز و عابر پیاده هم که بدیهی هستند و سرعت ماشین رو ۰ میکنند.
class RedTrafficLight(TrafficObject):
def set_car_state(self, car_state):
logging.debug('red light: stopping car')
car_state['speed'] = 0
class Pedestrian(TrafficObject):
def set_car_state(self, car_state):
logging.debug('pedestrian: stopping car')
car_state['speed'] = 0
جفت محدودیت سرعت های ۲۵ mph و ۴۰ mph میتونند از کلاس SpeedLimit استفاده کنند.این کلاس speed_limit را به عنوان پارامتر مقداردهی اولیه اش در نظر میگیره.وقتی که علامت شناسایی شد محدوده سرعت ماشین رو با توجه به اون محدودیت شناسایی شده تنطیم میکنیم.
class SpeedLimit(TrafficObject):
def __init__(self, speed_limit):
self.speed_limit = speed_limit
def set_car_state(self, car_state):
logging.debug('speed limit: set limit to %d' % self.speed_limit)
car_state['speed_limit'] = self.speed_limit
پیاده سازی سازی چراغ سبز از این هم راحت تره چرا که کاری جز پرینت کردن چراغ سبز(کدش آورده نشده) موقع شناسایی انجام نمیده.شناسایی علامت توقف یکم سخت تره چون اولا باید حواسش به حالت ها باشه,یعنی باید یادش باشه برای چند ثانیه در مقابل علامت توقف کرده و ثانیا حتی اگه وقتی که از علامت گذشت و تصویر ویدیو شامل یک علامت خیلی بزرگ بود به حرکتش ادامه بده.اگر جزییات بیشتری میخواید این لینک traffic_objects.py میتونه بهتون کمک کنه.
وقتی که واکنش مربوط به هر علامت رومشخص کردیم به یک کلاس نیاز داریم مثل ObjectsOnRoadProcessor تا بتونیم اون ها رو به هم مرتبط کنیم.این کلاس در ابتدا مدل آموزش داده شده برای Edge TPU را لود میکند و سپس اشیا رو در ویدیو به کمک مدل شناسایی میکنه و در نهایت هر شی را call میکند تا سرعت و محدوده آن را تغییر دهد.
در قطعه کد زیر قسمت های مهم objects_on_road_processor.py رو میتونید ببینید.
class ObjectsOnRoadProcessor(object):
"""
This class 1) detects what objects (namely traffic signs and people) are on the road
and 2) controls the car navigation (speed/steering) accordingly
"""
def __init__(self,
car=None,
speed_limit=40,
model='/home/pi/DeepPiCar/models/object_detection/data/model_result/road_signs_quantized_edgetpu.tflite',
label='/home/pi/DeepPiCar/models/object_detection/data/model_result/road_sign_labels.txt',
width=640,
height=480):
# model: This MUST be a tflite model that was specifically compiled for Edge TPU.
# https://coral.withgoogle.com/web-compiler/
logging.info('Creating a ObjectsOnRoadProcessor...')
self.width = width
self.height = height
# initialize car
self.car = car
self.speed_limit = speed_limit
self.speed = speed_limit
# initialize TensorFlow models
with open(label, 'r') as f:
pairs = (l.strip().split(maxsplit=1) for l in f.readlines())
self.labels = dict((int(k), v) for k, v in pairs)
# initial edge TPU engine
logging.info('Initialize Edge TPU with model %s...' % model)
self.engine = edgetpu.detection.engine.DetectionEngine(model)
self.min_confidence = 0.30
self.num_of_objects = 3
logging.info('Initialize Edge TPU with model done.')
self.traffic_objects = {0: GreenTrafficLight(),
۱: Person(),
۲: RedTrafficLight(),
۳: SpeedLimit(25),
۴: SpeedLimit(40),
۵: StopSign()}
def process_objects_on_road(self, frame):
# Main entry point of the Road Object Handler
objects, final_frame = self.detect_objects(frame)
self.control_car(objects)
return final_frame
def control_car(self, objects):
logging.debug('Control car...')
car_state = {"speed": self.speed_limit, "speed_limit": self.speed_limit}
if len(objects) == 0:
logging.debug('No objects detected, drive at speed limit of %s.' % self.speed_limit)
contain_stop_sign = False
for obj in objects:
obj_label = self.labels[obj.label_id]
processor = self.traffic_objects[obj.label_id]
if processor.is_close_by(obj, self.height):
processor.set_car_state(car_state)
else:
logging.debug("[%s] object detected, but it is too far, ignoring. " % obj_label)
if obj_label == 'Stop':
contain_stop_sign = True
if not contain_stop_sign:
self.traffic_objects[5].clear()
self.resume_driving(car_state)
def resume_driving(self, car_state):
old_speed = self.speed
self.speed_limit = car_state['speed_limit']
self.speed = car_state['speed']
if self.speed == 0:
self.set_speed(0)
else:
self.set_speed(self.speed_limit)
logging.debug('Current Speed = %d, New Speed = %d' % (old_speed, self.speed))
if self.speed == 0:
logging.debug('full stop for 1 seconds')
time.sleep(1)
def set_speed(self, speed):
# Use this setter, so we can test this class without a car attached
self.speed = speed
if self.car is not None:
logging.debug("Actually setting car speed to %d" % speed)
self.car.back_wheels.speed = speed
توجه کنید که TrafficObject فقط speed و speed_limit را در آبجکت car_stat تغییر میدهد و سرعت ماشین رو تغییر نمیده.ObjectsOnRoadProcessor سرعت ماشین رو بعد از تشخیص دادن تمامی علائم راهنمایی رانندگی و عابران پیاده تغییر میده.
جمع بندی:
در زیر نتیجه نهایی این پروژه رو میتونید ببینید.توجه کنید که ماشین خودران عمیق در مقابل همه چراغ های قرمز ایستاد,برای هیچ عابر پیاده ای توقف نکرد و به مسیرش ادامه داد.به علاوه موقع رسیدن به تابلو محدودیت سرعت ۲۵ mph سرعتش رو کم و سپس موقع رسیدن به تابلو محدودیت سرعت ۴۰ mph سرعتش رو افزایش داد.
توی لینک های زیر میتونید کد کامل رو ببینید:
- Colab Jupyter Notebook برای شناسایی شی و یادگیری انتقال (trasfer learning)
- Planning and Motion Control منطق در پایتون
- main driver program
پایان بخش ششم!!!
بخش های منتشر شده:
چگونه یک خودرو خودران و هوشمند بسازیم؟ (پارت اول)
چگونه یک خودرو خودران و هوشمند بسازیم؟ (پارت دوم)
چگونه یک خودرو خودران و هوشمند بسازیم؟ (پارت سوم)
چگونه یک خودرو خودران و هوشمند بسازیم؟ (پارت چهارم)