
مسیریابی مستقل با استفاده از یادگیری عمیق
خوش اومدین!!!اگه بخش ۴ رو خونده باشین تا الان دیگه باید یه ماشین خودران داشته باشد که به راحتی در مسیر حرکت میکنه,توی این بخش از یادگیری عمیق استفاده میکنیم تا همون کار رو انجام بده و ماشینمون رو به یک ماشین خودران یادگیری عمیق تبدیل کنیم.این مثل همون روشی هستش که ما خودمون رانندگی رو با مشاهده یاد گرفتیم.

مدل Nvidia:
توی مراتب بالا این مدل تصاویر ویدیو فریم را به عنوان ورودی دریافت میکند و زاویه هدایت رو به عنوان خروجی بر میگردونه .در اصل این مدل به زور ویدیو فریم ها رو میگیره و سعی میکنه که زاویه هدایت رو پیش بینی کنه.این مدل یک برنامه یادگیری ماشین تحت نظارت هست که که تصاویر ویدیو(بهشون میگیم ویژگی) و زوایای هدایت(بهشون میگیم لیبل) در یادگیری استفاده میشن.چون که این زوایای هدایت عدد هستن مساله به جای دسته بندی از نوع رگرسیون هست.
در مرکز این مدل یک شبکه عصبی کانولوشن(CNN) وجود داره که عموما برای تشخیص تصویر استفاده میشن. CNN برای استخراج ویژگی ها از لایه های مختلف تصاویر بسیار کاربردیه مثلا توی لایه های اولیه ویژگی های ابتدایی رو مثل خطوط و زوایا شناسایی میکنه.توی لایه های میانی ویژگی های پیچیده تری ماننند چشم ها,بینی و گوش ها شناسایی میشن . و در لایه آخر پیچیده ترین ویژگی ها شناسایی میشن.
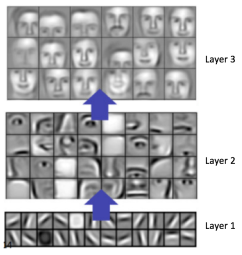
لایه ها توی مدل Nvidia مثل همین تصویر بالا هستن,هر چقدر که توی لایه های اولیه خطوط و زوایا رو تشخیص میده توی لایه های بعدی ویژگی ها سخت تر میشن.لایه های کاملا متصل(fully connected layers)میتونن به عنوان کنترل گر هدایت استفاده شن.
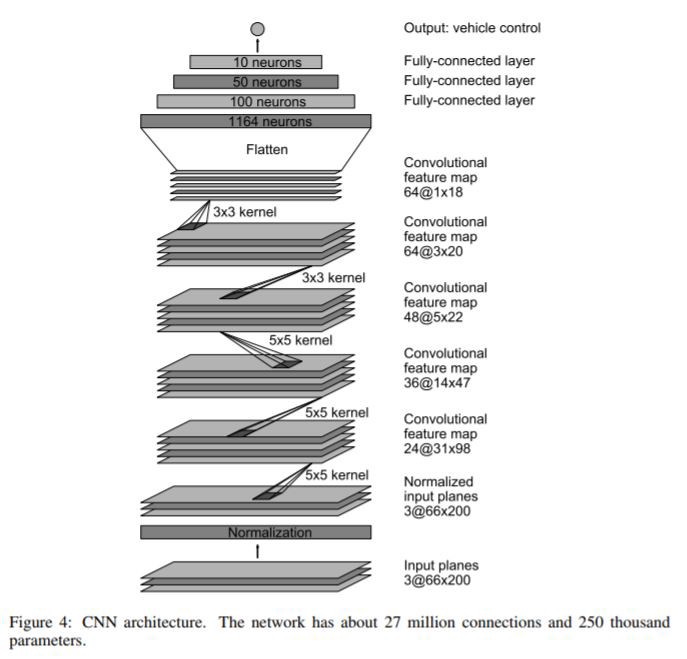
توی عکسی که این بالا میبینید تقریبا ۳۰ تا لایه داره که در مقایسه با استاندارد های امروزی خیلی عمیق محسوب نمیشه.تصویر ورودی مدل(پایین دیاگرام) یک تصویر ۶۶×۲۰۰ پیکسل هست که که خیلی کیفیتش پایینه.در ابتدا تصویر را normalize میکنیم بعد از ۵ دسته لایه کانولوشن میگذرونیمش و در نهایت از ۴ تا لایه کاملا متصل میگذرونیم و به یک خروجی میرسیم که مدل پیش بینی زاویه مسیر یابی ماشین هستش.
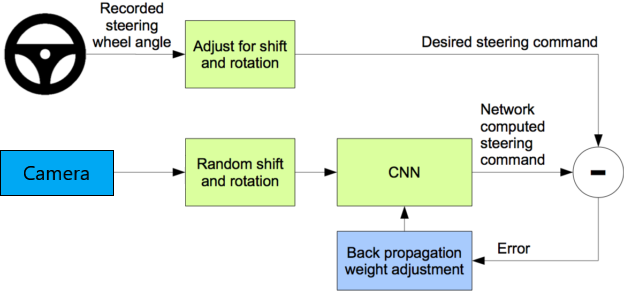
این مدل پیش بینی زاویه سپس با زاویه مسیر یابی مقایسه میشود و خطا به پروسه یادگیری CNN توسط backpropagation برگردانده میشه.همونجور ه توی دیاگرام بالا دیده میشه این پروسه تا وقتی که خطا به اندازه کافی کم بشه تکرار میشه.که به این معنیه که مدل یاد گرفته که به خوبی هدایت کنه.
سازگار کردن مدل Nvidia با ماشین خودران:
به جز سایز ماشین خودران ما بسیار به ماشینی که Nvidia استفاده میکنه شبیهه.مثلا استفاده از دوربینی که میتونه توسط مشخص کردن یه زاویه هدایت خاص کنترل کنه.Nvidia ورودیش رو از راننده اش که حدود ۷۰ ساعت ترکیبی از اتوبان های موجود در مکان ها و ماشین های مختلف به دست میاره.بنابراین ما باید یه سری ویدیو از ماشین خودرانمون جمع کنیم و برای هر تصویر از ویدیو زاویه صحیح هدایت رو ذخیره کنیم.


استفاده از اطلاعات:
راه های مختلفی برای جمع آوری اطلاعات یادگیری وجود داره.یک راه نوشتن برنامه کنترل از راه دور هست که میتونیم ماشین خودران رو از راه دور راهنمایی کنیم , علاوه بر ذخیره زاویه هدایت هر ویدیو فریم اون ویدیو فریم ها رو هم ذخیره میکنه.این از اونجای که شرایط دنیای واقعی رو شبییه سازی میکنه بهترین حالت هست اما احتیاج داره که یه برنامه کنترل از راه دور بنویسیم.یه راه دیگه ساده تر اینه که از چیزی که توی بخش قبل با open cv نوشتیم استفاده کنیم.از اونجایی که به خوبی کار میکنه میتونیم از اون پیاده سازی به عنوان مدل driver استفاده کنیم.تنها کاری که باید بکنیم اینه که مدل قبلیمون رو چند بار اجرا کنیم و فایل های ویدیویی و زوایای هدایت مربوط بهشون رو ذخیره کنیم.بعدش از این اطلاعات میتونیم استفاده کنیم تا مدل Nvidia مون رو آموزش بدیم.در بخش قبلی deep_pi_car.py یک فایل ویدیویی با فرمت AVI بعد از هر بار اجرا کردن برنامه ذخیره میکنه.
در زیر قطعه کدی رو میبینید که یک فایل ویدیویی رو دریافت میکنه و فریم های ویدیو رو برای آموزش ذخیره میکنه.برای ساده سازی زاویه هدایت رو به عنوان بخشی از نام تصویر ذخیره میکنیم تا به نگاشت بین نام فایل و زوایای هدایت نیاز نداشته باشیم.
import cv2
import sys
from hand_coded_lane_follower import HandCodedLaneFollower
def save_image_and_steering_angle(video_file):
lane_follower = HandCodedLaneFollower()
cap = cv2.VideoCapture(video_file + '.avi')
try:
i = 0
while cap.isOpened():
_, frame = cap.read()
lane_follower.follow_lane(frame)
cv2.imwrite("%s_%03d_%03d.png" % (video_file, i, lane_follower.curr_steering_angle), frame)
i += 1
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
save_image_and_steering_angle(sys.argv[1])
فرض کنین که یک ویدیو فیلم برداری شده به نام video01.avi از بخش قبل داریم توی این ویدیو میتونید یه نمونش رو ببینید.
با استفاده از قطعه کد پایین میتونید تصاویر ساکن رو دخیره کنید و با زاویه هدایشتون تگ گذاریشون کنید.
pi@raspberrypi:~/DeepPiCar/driver/code $ python3 save_training_data.py ~/DeepPiCar/models/lane_navigation/data/images/video01
این ها فایل های تصویری تولید شده هستند.دقت کنید که ۳ تا رقم قبل از هر پسوند .png نوشته شده که نشون دهنده زاویه هدایت هست.مثلا این زیر میتونیم بگیم که ماشین به چپ پیچیده اگه زاویه کمتر از ۹۰ هست.
pi@raspberrypi:~/DeepPiCar/driver/code $ ls ~/DeepPiCar/models/lane_navigation/data/images |more
video01_000_085.png
video01_001_080.png
video01_002_077.png
video01_003_075.png
video01_004_072.png
video01_005_073.png
video01_006_069.png
آموزش/یادگیری عمیق:
حالا که ویژگی ها و لیبل هامون رو داریم وقتشه که یادگیری عمیق رو انجام بدیم.درسته که تو دنیای امروزی همه چیز درباره یادگیری عمیق هستش واقعیت اینه که فقط بخش کوچیکی از پروژه های مهندسی رو در برمیگیره و بخش زیادی از پروژه ها صرف مهندسی سخت افزار-نرم افزار-جمع آوری و تمیز کردن اطلاعات میشه .و در نهایت پیش بینی های مدل های یادگیری عمیق انجام میشه.
برای اینکه مدل یادگیری عمیقمون رو آموزش(train) بدیم نمیتونیم از Raspberry Pi’s CPU استفاده کنیم و به یه سری GPU احتیاج داریم.با این حال بودجه کمی داریم و نمیخوایم ماشینی رو تهیه کنیم که آخرین مدلGPU رو داشه باشه و یا اینکه GPU ابری(cloud)اجاره کنیم.خوشبختانه google یک سری GPU و حتی TPU به طور رایگان توی سایت Google Colab به ما ارائه میده.آفرین به گوگل که به ما هایی که به یادگیری ماشین علاقه داریم چنین پلتفرم خوبی رو میده تا یاد بگیریم.

کولب یک سری jupiter notebook مبتنی بر رایانش ابری هستند که بهتون اجازه میده تا مدل های یادگیری عمیق رو به زبان پایتون بنویسید و آموزششون بدید.کتابخانه های محبوب پایتون که پشتیبانی میشن عبارت اند از pandas,tensorflow,keras,OpenCVو …چیز جالبی که هست اینه که tensorflow به طور پیش فرض روی GPU نصب شده و نیازی نیست که ساعتای زیادی رو صرف این کنید که بخواین با pip و یا cuda اون رو نصب کنید.
پس بدون هیچ مقدمه بریم که کار با دفترچه رو شروع کنیم فرض ما بر این هست که شما با پایتون و کتابخونه keras آَشنایی دارید.
استفاده از کتابخانه ها:
در ابتدا باید کتابخانه های پایتونی رو که برای آموزش مدل ازشون قراره استفاده کنیم,ایمپورت کنیم.
# python standard libraries
import os
import random
import fnmatch
import datetime
import pickle
# data processing
import numpy as np
np.set_printoptions(formatter={'float_kind':lambda x: "%.4f" % x})
import pandas as pd
pd.set_option('display.width', 300)
pd.set_option('display.float_format', '{:,.4f}'.format)
pd.set_option('display.max_colwidth', 200)
# tensorflow
import tensorflow as tf
import keras
from keras.models import Sequential # V2 is tensorflow.keras.xxxx, V1 is keras.xxx
from keras.layers import Conv2D, MaxPool2D, Dropout, Flatten, Dense
from keras.optimizers import Adam
from keras.models import load_model
print( f'tf.__version__: {tf.__version__}' )
print( f'keras.__version__: {keras.__version__}' )
# sklearn
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
# imaging
import cv2
from imgaug import augmenters as img_aug
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
%matplotlib inline
from PIL import Image
بارگذاری اطلاعات آموزش(Training data):
توی لینکی که توی بخش قبل گذاشتیم این اطلاعات آورده شده.یادتون باشه که فایل های تصویری به فرمت videoXX_FFF_SSS.png ذخیره شدند که videoXXX نام ویدیو و FFF شماره فریم در ویدیو و SSS زاویه هدایت هستند.برایند اطلاعات آموزش در متغیر های image_paths و steerin_ angles خونده میشه.برای مثال video01_054_110.png یعنی تصویر از فایل ویدیویی video01.avi میاد که ۵۴ امین فریم و زاویه هدایتش ۱۱۰ درجه است.(گردش به راست)
# import images
!cd /content
!git clone https://github.com/dctian/DeepPiCar
!ls
data_dir = '/content/DeepPiCar/models/lane_navigation/data/images'
file_list = os.listdir(data_dir)
image_paths = []
steering_angles = []
pattern = "*.png"
for filename in file_list:
if fnmatch.fnmatch(filename, pattern):
image_paths.append(os.path.join(data_dir,filename))
angle = int(filename[-7:-4]) # 092 part of video01_143_092.png is the angle. 90 is go straight
steering_angles.append(angle)
تقسیم دیتا به مجموعه یادگیری/تست(train/test):
ما اطلاعات رو دو دسته یادگیری و تست با نسبت ۸۰/۲۰ تقسیم بندی میکنیم.این کار با استفاده از متد train_test_split از کتابخانه sklearn قابل پیاده سازیه.
X_train, X_valid, y_train, y_valid = train_test_split( image_paths, steering_angles, test_size=0.2)
print("Training data: %d\nValidation data: %d" % (len(X_train), len(X_valid)))
افزایش تصاویر:
مجموعه آموزش نمونه فقط ۲۰۰ تا عکس داره و مشخصه که چنین مقداری برای آموزش مدل عمیقمون کافی نیست.هر چند که میتونیم از یک تکنیک ساده به نام Image Augmentation استفاده کنیم.برخی از این تکنیک ها شامل زوم کردن-panning-محو کردن و چرخوندن عکس هست.اگر این تکنیک ها رو روی مجموعه تصاویرمون پیاده کنیم تعداد عکس ها خیلی زیاد تر میشن.ما فعلا فقط از زوم و چرخوندن عکس استفاده میکنیم.
زوم کردن:
در زیر قطعه کدی رو میبینید که برای زوم کردن رندوم بین ۱۰۰% و ۱۳۰%و تصویر برآیند استفاده میشه:
def zoom(image):
zoom = img_aug.Affine(scale=(1, 1.3)) # zoom from 100% (no zoom) to 130%
image = zoom.augment_image(image)
return image

چرخاندن:
در زیر قطعه کد چرخاندن رندوم رو میبینید.یادتون باشه که چرخاندن عکس با بقیه تکنیک های افزایش تصویر فرق داره و علتش اینه که موقع چرخاندن عکس باید زاویه هدایت تصویر رو هم تغییر بدیم.مثلا وقتی که عکس چپ یک خط داره که به سمت چپ خم میشه زاویه اش ۸۵ درجه است.اما موقع چرخاندن عکس دیگه به سمت راست اشاره میکنه و زاویه جدیدش ۹۵ درجه است(۱۸۰-۸۵)
def random_flip(image, steering_angle):
is_flip = random.randint(0, 1)
if is_flip == 1:
# randomly flip horizon
image = cv2.flip(image,1)
steering_angle = 180 - steering_angle
return image, steering_angle

یه تابعی رو داریم که میتونه تمامی عملیات افزایشی رو با هم تلفیق کنه پس تمامی عملیات میتونه روی تصویر اجرا بشه:
def random_augment(image, steering_angle):
if np.random.rand() < 0.5:
image = pan(image)
if np.random.rand() < 0.5:
image = zoom(image)
if np.random.rand() < 0.5:
image = blur(image)
if np.random.rand() < 0.5:
image = adjust_brightness(image)
image, steering_angle = random_flip(image, steering_angle)
return image, steering_angle
پردازش تصویر:
علاوه بر این ما باید تصایرمون رو به فضای رنگی و ابعادی تغییر بدیم که برای مدل Nvidia قابل قبول باشه.اولا با توجه به مقاله پژوهش Nvidia مدل به تصاویر ورودی با کیفیت ۲۰۰×۶۶ نیاز داره.همانند کاری که توی بخش ۴ کردیم نیمه بالایی تصویر به پیش بینی زاویه هدایت کمکی نمیکنه پس اون رو از تصویر حذف میکنیم.ثانیا تصاویر باید در فضای رنگی YUV باشند.مشابها از cv2.cvtcolor استفاده میکنیم.در نهایت عکس رو نرمالیزه میکنیم.
def img_preprocess(image):
height, _, _ = image.shape
image = image[int(height/2):,:,:] # remove top half of the image, as it is not relevant for lane following
image = cv2.cvtColor(image, cv2.COLOR_RGB2YUV) # Nvidia model said it is best to use YUV color space
image = cv2.GaussianBlur(image, (3,3), 0)
image = cv2.resize(image, (200,66)) # input image size (200,66) Nvidia model
image = image / 255 # normalizing
return image
مدل Nvidia:
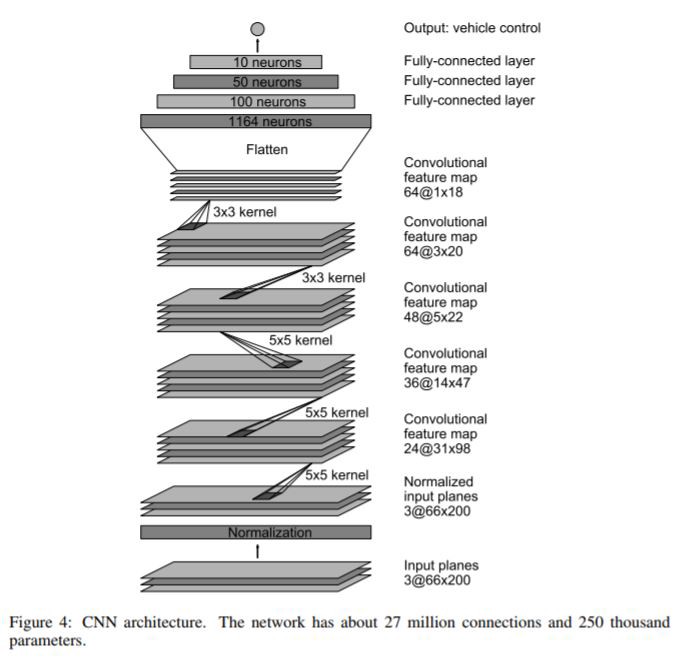
در اینجا دوباره به معماری مدل Nvidia اشاره میکنیم تا بتونیم به سادگی با مدلمون توی کد مقایسه اش کنیم.
def nvidia_model():
model = Sequential(name='Nvidia_Model')
# elu=Expenential Linear Unit, similar to leaky Relu
# skipping 1st hiddel layer (nomralization layer), as we have normalized the data
# Convolution Layers
model.add(Conv2D(24, (5, 5), strides=(2, 2), input_shape=(66, 200, 3), activation='elu'))
model.add(Conv2D(36, (5, 5), strides=(2, 2), activation='elu'))
model.add(Conv2D(48, (5, 5), strides=(2, 2), activation='elu'))
model.add(Conv2D(64, (3, 3), activation='elu'))
model.add(Dropout(0.2)) # not in original model. added for more robustness
model.add(Conv2D(64, (3, 3), activation='elu'))
# Fully Connected Layers
model.add(Flatten())
model.add(Dropout(0.2)) # not in original model. added for more robustness
model.add(Dense(100, activation='elu'))
model.add(Dense(50, activation='elu'))
model.add(Dense(10, activation='elu'))
# output layer: turn angle (from 45-135, 90 is straight, <90 turn left, >90 turn right)
model.add(Dense(1))
# since this is a regression problem not classification problem,
# we use MSE (Mean Squared Error) as loss function
optimizer = Adam(lr=1e-3) # lr is learning rate
model.compile(loss='mse', optimizer=optimizer)
return model
model = nvidia_model()
print(model.summary())
توجه کنید که ما تقریبا به طور خوبی مدل معماری Nvidia رو پیاده کردیم,به جز اینکه لایه های نرمال سازی رو حذف کردیم,همونطوری که خارج از مدل ممکنه انجام بدیم,یه سری لایه dropout اضافه کردیم,تا بتونیم مدل رو قوی تر کنیم.تابع loss استفاده شده در اینجا خطای میانگین مجذور(mean squared error) است چون مدل ما عملیات رگرسیون رو انجا میده.علاوه بر این ما از تابع فعالسازی واحد نمایی خطی(ELU-Exponential Linear Unit)به جای تابع فعالسازی واحد خطی اصلاح شده (Rectified Linear Unit-ReLU) استفاده کردیم چون در هنگام منفی شدن x مشکل “dying RELU” را ندارد.
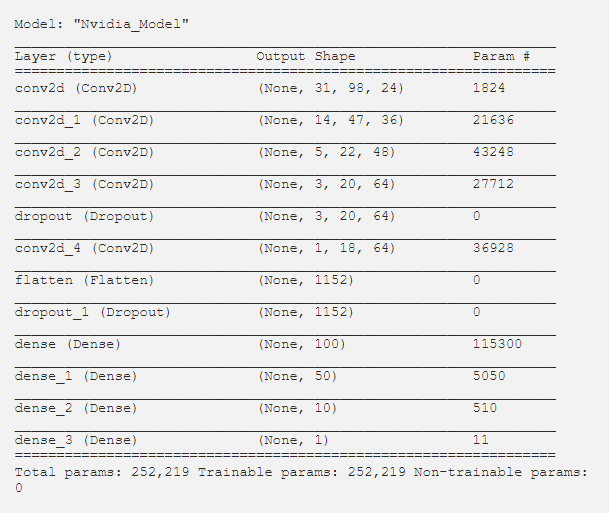
وقتی مدل را می سازیم و لیست پارامتر های آن را پرینت میکنیم میبینیم شامل ۲۵۰۰۰۰ پارامتر است.این یعنی که هر لایه مدل به شکلی ساخته شده که انتطار داشتیم.
آموزش(training):
حالا که هم مدل و هم اطلاعات آماده هستند عملیات آموزش(training) را شروع میکنیم.
# saves the model weights after each epoch if the validation loss decreased
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(filepath=os.path.join(model_output_dir,'lane_navigation_check.h5'), verbose=1, save_best_only=True)
history = model.fit_generator(image_data_generator( X_train, y_train, batch_size=100, is_training=True),
steps_per_epoch=300,
epochs=10,
validation_data = image_data_generator( X_valid, y_valid, batch_size=100, is_training=False),
validation_steps=200,
verbose=1,
shuffle=1,
callbacks=[checkpoint_callback])
# always save model output as soon as model finishes training
model.save(os.path.join(model_output_dir,'lane_navigation_final.h5'))
برای اونایی که تا keras کار کردن میدونن که ما از دستور ()model.fit استفاده میکنیم.اما توجه کنین که ما الان از دستور ()model.fit_generator استفاده کردیم.این به خاطر اینه که ما از یک محموعه اطلاعات ایستا استفاده نمیکنیم, اطلاعات ما به طور پویا از ۲۰۰ تا تصویر اصلیمون توسط عملیات افزایشی که قبل توضیح دادیم تولید شده.برای این کار به یک تابع کمکی احتیاج داریم که عملیات افزایش رو انجام بده و بعدش یه دسته اطلاعات جدید رو توی هر تکرار به ()model.fit_generator برگردونه.
در زیر قطعه کد مربوط به تابع کمکی رو میبینید:
def image_data_generator(image_paths, steering_angles, batch_size, is_training):
while True:
batch_images = []
batch_steering_angles = []
for i in range(batch_size):
random_index = random.randint(0, len(image_paths) - 1)
image_path = image_paths[random_index]
image = my_imread(image_paths[random_index])
steering_angle = steering_angles[random_index]
if is_training:
# training: augment image
image, steering_angle = random_augment(image, steering_angle)
image = img_preprocess(image)
batch_images.append(image)
batch_steering_angles.append(steering_angle)
yield( np.asarray(batch_images), np.asarray(batch_steering_angles))
ارزیابی مدل آموزش داده شده:
بعد از حدود ۳۰ دقیقه یادگیری مدل ۱۰ دور را طی میکنه.حالا وقتشه که ببینیم آموزش چه جوری پیش رفته.اولین چیز اینه که تابع loss جفت مجموعه های یادگیری و آزمایش رو نمایشه بدیم.خبر خوب اینه که میبینیم که هر دو تا با هم افت میکنند و بعد از ۵ تا دور(epoch) کم باقی میمونند.به نظر نمیرسه که مشکل overfitting وحود داشته باشه چون که تابع loss جفتشون همونجوری کم باقی موندن.
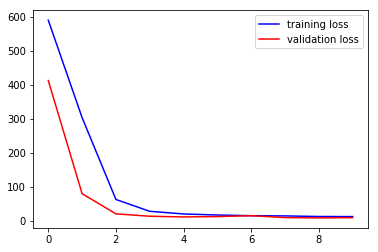
مقیاس دیگه ای که به ماکمک میکنه تا ببینبیم که آیا مدلمون خوب کار کرده یا نه مقیاس R² است.مقدار R² نزدیک به ۱۰۰% نشان دهنده اینه که مدل ما به خوبی کار میکنه.همونجوری که در زیر میبینید مدل ما حتی با ۲۰۰ تصویر R² با مقدار ۹۳% دارا که نشون دهنده خوب بودن مدله که علتش هم استفاده از تکنیک های افزایشی است.
from sklearn.metrics import mean_squared_error, r2_score
def summarize_prediction(Y_true, Y_pred):
mse = mean_squared_error(Y_true, Y_pred)
r_squared = r2_score(Y_true, Y_pred)
print(f'mse = {mse:.2}')
print(f'r_squared = {r_squared:.2%}')
def predict_and_summarize(X, Y):
model = load_model(f'{model_output_dir}/lane_navigation_check.h5')
Y_pred = model.predict(X)
summarize_prediction(Y, Y_pred)
return Y_pred
n_tests = 100
X_test, y_test = next(image_data_generator(X_valid, y_valid, n_tests, False))
y_pred = predict_and_summarize(X_test, y_test)
mse = 9.9
r_squared = 93.54%
در مسیر:
حتی اگه یک مدل خیلی هم خوب باشه باز هم نیاز داره که وقتی به جاده میرسه تست بشه.در زیر هسته منطق ماشین خودران عمیق رو میبینید.در مقایسه با پیاده سازی مسیریابی دست نویس خودمون تمامی مراحل (۲۰۰ خط کد) برای تشخیص خطوط آبی,شناسایی مسیر,محاسبه زوایای هدایت و بقیه چیزا حذف شدند.به جای اون ها دستور های ساده load_model , model_predict وجود دارند.مشخصا به خاطر اینه که تمامی تنظیمات توی مرحله یادگیری صورت گرفتند و فایل مدل آموزش داده شده ۳ بایتی به فرمت HDFS شامل ۲۵۰۰۰۰ تا!!پارامتره.
model = load_model('lane_navigation_model.h5')
def compute_steering_angle(self, frame):
preprocessed = img_preprocess(frame)
X = np.asarray([preprocessed])
steering_angle = model.predict(X)[0]
return steering_angle
در اینجا کد کامل مسیر یابی با استفاده از یادگیری عمیق رو میتونید ببینید.توجه کنید که در این کد یک سری تابع کمکی و تست کننده برای کمک به نمایش و تست وجود داره.
الان دیگه واقعا لایقشه که بهش بگیم ماشین خودران عمیق.اگه رفتار ماشین رو مشاهده کنیم می فهمیم که در کل تو بیشتر مسیر به جز آخر به خوبی عمل میکنه.چون که این مدل از یادگیری عمیق استفاده میکنه برای بهبود مدل میتونیم ویدیو های بیشتری از رفتار راننده(چه از راه دور با استفاده از یک کد دست نویس و چه با استفاده از راننده پشت فرمان) به دست بیاریم و به مدل بدیم تا اونها رو یاد بگیره.اگر میخوایم که ماشین رو در مسیر سفید/زرد راهنمایی کنیم میتونیم به مدل ویدیو هایی با مسیر های مشخص شده سفید/زرد وزوایای هدایت رو بدیم و مدل میتونه حتی بدون مشخص کردن رنگ ها (کاری که توی بخش قبل کردیم)عملکرد خوبی داشته باشه.واقعا چه قدر جالب!!!
پایان پارت پنجم!!!
در بخش های بعدی هم ما رو همراهی کنید عزیزان!!!
بخش های منتشر شده:
چگونه یک خودرو خودران و هوشمند بسازیم؟ (پارت اول)
چگونه یک خودرو خودران و هوشمند بسازیم؟ (پارت دوم)
چگونه یک خودرو خودران و هوشمند بسازیم؟ (پارت سوم)
چگونه یک خودرو خودران و هوشمند بسازیم؟ (پارت چهارم)