
در این بخش میخوایم یک روش مرسوم بینایی کامپیوتر رو برای نوشتن یک نرم افزار pipeline که ماشین ها رو در مقابل دوربین ماشین تشخیص میده به کار ببریم.
در این روش سنتی تقریبا همه پارامتر ها به طور دستی تنظیم میشن که به ما یک بینش در باره چگونگی و علت کار کرد میده.
گام های زیر پیاده سازی شده اند:
- استخراج ویژگی های هیستوگرام شیب های جهت دار(HOG) در یک مجموعه تصاویر که همشون لیبل گذاری شدند,آموزش یک طبقه بندی کننده خطی SVM
- انتقال رنگ و ویژگی های رنگ binned,هیستوگرام رنگ,متصل شده به بردار ویژگی HOG.
- نرمال سازی ویژگی ها و انتخاب تصادفی برای مجموعه های آموزش و تست.
- روش Sliding-window با طبقه بندی کننده آموزش داده شده جهت جست و جوی ماشین ها در تصاویر.
- اجرای pipeline روی یک ویدیو استریم و اجرای یک نقشه حرارتی(heat map)از شناسایی مکرر فریم به فریم برای رد کردن داده های خارج از محدوده و دنبال کردن ماشینهای شناسایی شده.
- تقریب زدن جعبه های مرزی(bounding boxes) برای ماشین های شناسایی شده.
انگیزه و چالش:
شناسایی اشیا در تصویر عصاره بینایی کامپبوتر است.وقتی که به چشم هامون به اطرافمون نگاه میکنیم دائماً در حال شناسایی و طبقه بندی اشیا با مغزمون هستیم و درک ما از دنیای اطراف نقش مهمی در سیستم ماشین خودران داره.
چالش های بسیاری در پردازش تصاویر وجود داره:ما نمیدونیم که شی در کجای تصویر ظاهر میشه و یا به چه شکل و اندازه ای خواهد بود و یا نمیدونیم به چه رنگی خواهد بود و یا چند تا شی به طور همزمان ظاهر میشن. و برای ماشین خودران به علائم راهنمایی رانندگی-عابر پیاده و تمام چیزهایی که در مسیر ظاهر میشن این ها صدق میکنه.
برای شناسایی ماشین مهمه که که موقعیت اون رو در مسیر شناسایی و پیش بینی کنیم و ببینیم که فاصله اونها از ماشین خودران چقدره,در چه جهت و با چه سرعتی در حال حرکت اند.همونطوری که خودمون در هنگام رانندگی با چشم های خودمون این کار ها رو انجام میدیم.
یک سری از ویژگی های به درد بخور درر شناسایی تصویر عبارت اند از:
- رنگ
- موقعیت در تصویر
- شکل
- سایز آشکار
مجموعه آموزش:
در اینجا لینک های مجموعه های لیبل گذاری شده برای ماشین و غیر ماشین رو میتونید ببینید.این یک دیتاست کوچک با ۸۷۹۲ تصویر ماشین و ۸۹۶۸ تصویر غیر ماشین با سایز ۶۴×۶۴ pixels هستش.تصاویر تلفیقی از GTI vehicle image database و KITTI vision benchmark suite و مثال های استخراج شده از ویدیو خود پروژه میباشند.
بررسی اطلاعات:

روش شناسی:
در ابتدا ما ویژگی های تصویر را شناسایی و استخراج میکنیم و بعدش از اون استفاده میکنیم تا بتونیم طبقه بندی کننده(classifier)را آموزش بدیم.بعدش یک window searchروی تصویر را روی هر فریم ویدیو اجرا میکنیم تا بتوانیم ماشین ها را شناسایی و طبقه بندی کنیم.در نهایت باید با مثبت های کاذب(false positive) سر و کار داشته باشیم و یک جعبه مرزی(bounding box) برای ماشین های شناسایی شده تخمین بزنیم.
همه ی این ها به شدت و شیب های پیکسل های خام تصویر و اینکه چگونه این ویژگی ها رنگ و شکل شی را میگیرد,برمیگردد.ویژگی های استخراج و تلفیق شده برای این پروژه عبارت اند از:
- هیستوگرام شدت پیکسل ها:بیان کننده رنگ ماشین ها
- شیب شدت پیکسل ها:نشان دهنده شکل ماشین ها
استخراج ویژگی ها:
۱.چگونه هیستوگرام شیب های جهت دار(HOG) محاسبه میشوند:
شیب ها در یک جهت خاص با توجه به مرکز شی تصویری به ما یک نشانه از شکل شی میدهد.در اینجا با استفاده از روش هیستوگرام شیب های جهت دار پیاده سازی شده که در اینجا توضیح داده شده. برای اجرا از ()skimag.hog موجود در scikit-image استفاده کردیم.این تابع یک کانال تک رنگ و یا تصویر grayscaled را به عنوان ورودی میگیرد.



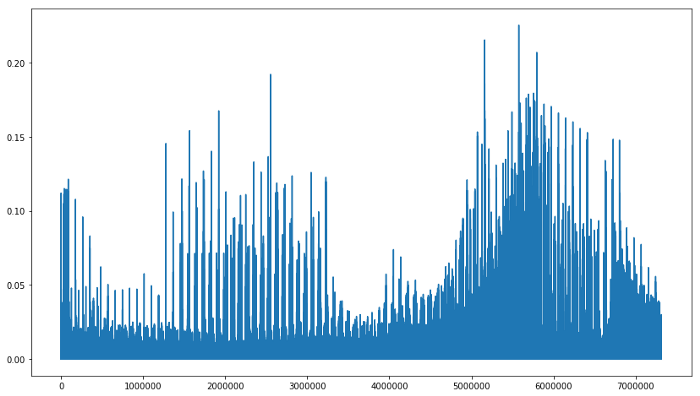
اگر درباره فواید این شیوه بیشتر میخواید بدونید مقاله advanced lane line detection project میتونه بهتون کمک کنه.
اشیا در تصویر ممکنه به یک کلاس تعلق داشته باشند اما در رنگ های مختلفی ظاهر شوند این به عنوان مساله non-variance شناخته میشه.برای مواجهه با این مساله باید ارزیابی کنیم که چگونه اطلاعات رنگ اشیایی که در یک کلاس قرار میگیرند رو خوشه بندی(clustering)کنیم.ما به فضا های رنگی متفاوت نگاه میکنیم و توجه میکنیم که چه طوری اشیایی که بهشون نگاه میکنیم در پس زمینه قرار میگیرند.فضا های رنگی زیادی مثل HLV, HSV, LUV, YUV, YCrCb و … وجود دارند.ما از فضای YCrCb استفاده میکنیم چون در خوشه بندی در صفحه y به خوبی عمل میکنه.
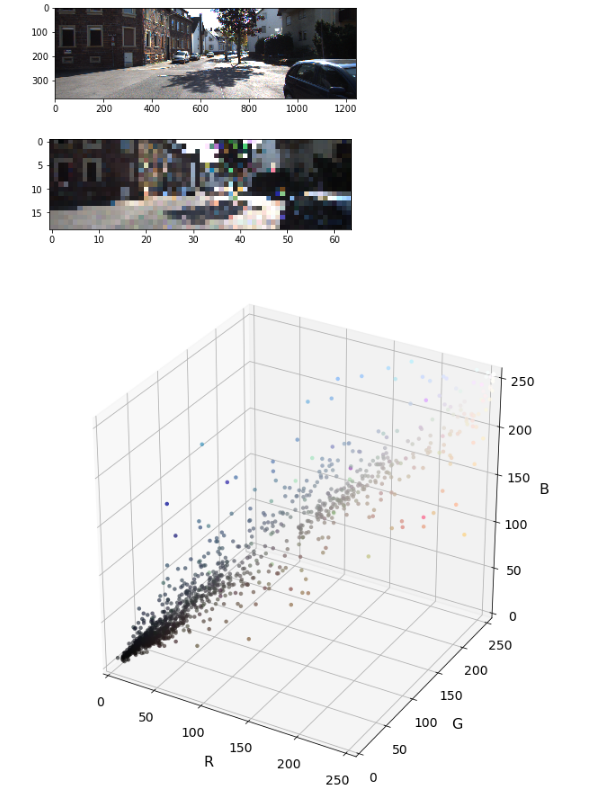
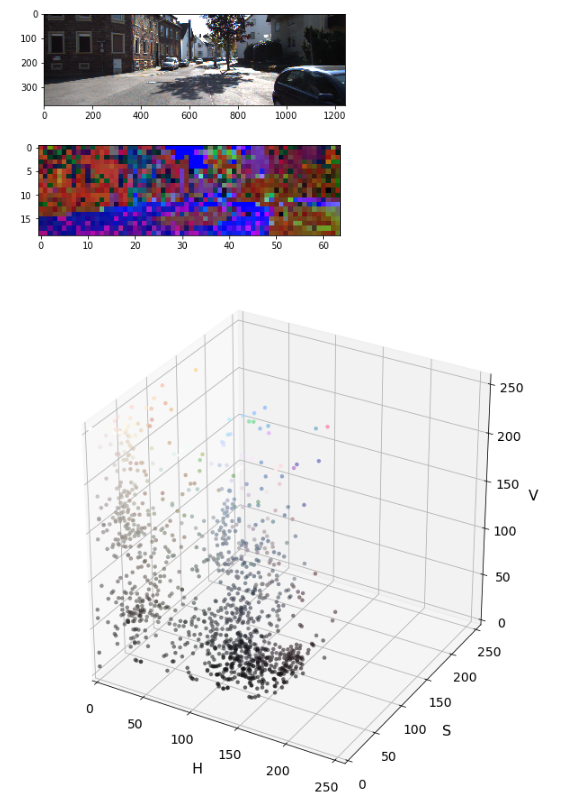
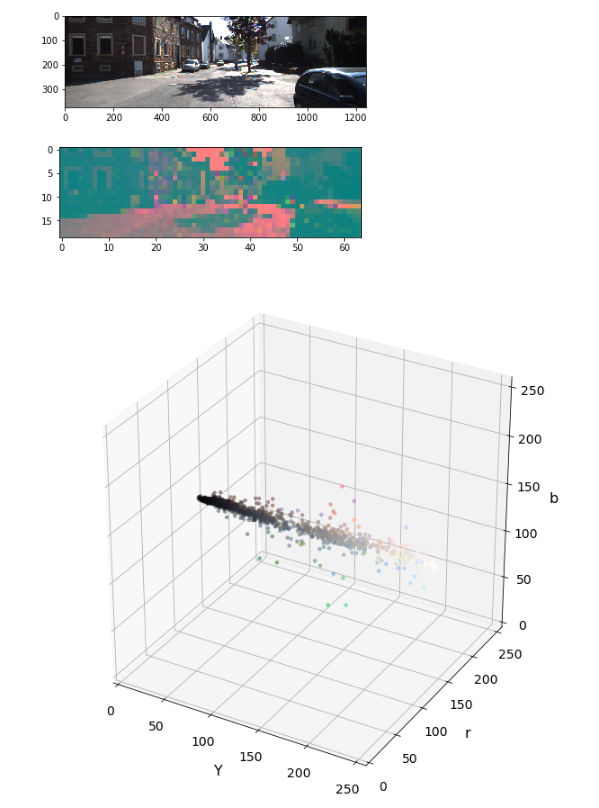
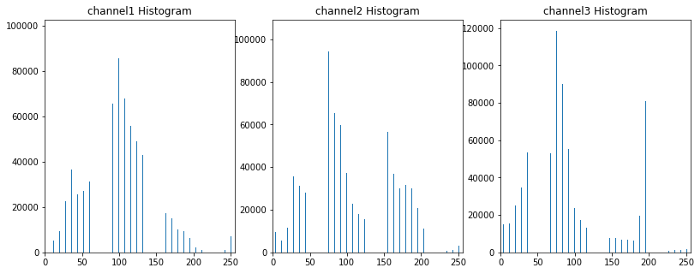
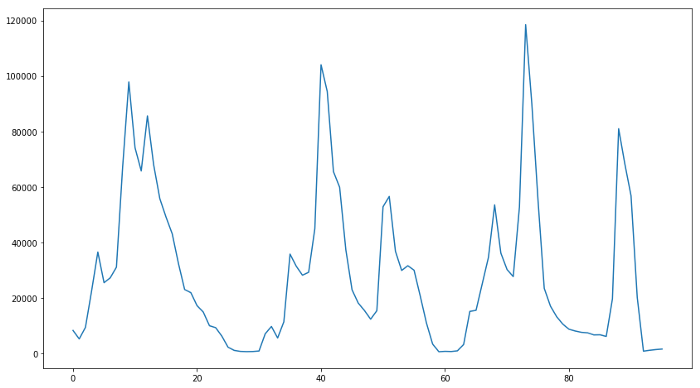
۲.چگونه هیستوگرام های شدت پیکسل(ویژگی های عکس) محاسبه میشوند:
ایده اصلی در اینجا استخراج signature رنگ از تصویر برای آموزش classifier و جست و جوی اون signature در فریم های ویدیو است.به طور پایه مکان هایی که توزیع یکسان دارند به چیز های نزدیکی اشاره میکنند.این تکنیک به ما مقداری آزادی چارچوب میده چون به نحوه چیدمان پیکسل ها حساس نیست. دیدگاه ها و یا گرایش هایی که یکم با هم متفاوت هستند به ما یک چیز یکسانی میدهند.گوناگونی ها در سایز توسط نرمال سایزی هیستوگرام هاایجاد میشوند.
در زیر یک راهکار پایه رو برای محاسبه این هیستوگرام ها میبینید:

مثال visualization:

۳.binning فضایی رنگ:
در اینجا ما پیکسل های تصاویر رو به عنوان یک بردار ویژگی در نظر میگیریم.ممکنه که در برگرفتن ۳ تا صفحه رنگ تصویری که دارای کیفیت بالایی داره کار بیهوده باشه بنابراین یک متد به اسم spatial binning را روی تصویر در جایی که پیکسل های تصویر در کنار هم قسمت کم کیفیتی رو به وجود آورده اند اجرا میکنیم.در حین آموزش تنظیم میکنیم که چه قدر میتونیم پایین تر بریم تا حدی که باز هم بتونیم اطلاعات کافی رو برای شناسایی ماشین ها به دست بیاریم.
چگونه این بردار رو میسازیم؟سایز تصویر رو تغییر میدیم و اون رو به یک بردار یک بعدی تبدیل میکنیم:
# Resize and convert to 1D
small_img = cv2.resize(image, (32, 32))
feature_vec = small_img.ravel()


آموزش طبقه بندی کننده SVM خطی:
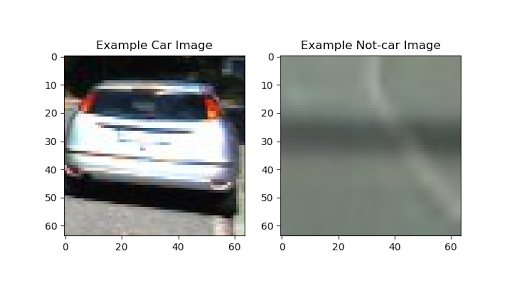
با خواندن تمام تصاویر موجود در vehicle و non-vehicle کار راشروع میکنیم.در زیر مثالی رو برای کلاس های vehicle و non-vehicle میبینید.
سپس یک تابع برای استخراج binning فضایی,هیستوگرام رنگ و HOG برای لیستی از تصاویر میسازیم.بردارهای نهایی برآیند ۳ قسمت هستند:binning فضایی,رنگ و HOG.بعدش از این تابع برای استخراج ویژگی های کل مجموعه داده ها استفاده میکنیم.استفاده از یک generator ممکنه برای رویارویی با مشکلات حافظه کامپیوتر گزینه خوبی باشه اما چون ما با با یک مجموعه به نسبت کوچک سروکار داریم از اون استفاده نکردیم.
بعدش بردار های ویژگی ها برای سر و کار داشتن با مختصات مختلف ویژگی های بهم پیوسته نرمال سازی میشوند.تعداد نامیزان ویژگی های بین binning فضایی,هیستوگرام رنگ ها و HOG با استفاده از صرف نظر کردن از آنهایی که کمکی به ما نمیکردند مینیمم میشود.این کار با استفاده از متد StandardScaler() پکیج sklearn صورت میگیرد:
# Fit a per-column scaler
X_scaler = StandardScaler().fit(X)
# Apply the scaler to X
scaled_X = X_scaler.transform(X)
سپس فضاهای رنگی مختلف و پارامتر های ()skimage.hog مختلف (cells_per_block,pixels_per_cell,orientations) را برای رسیدن به مقادیر تنظیم شده نهایی امتحان میکنیم.مثل زیر:
# Parameter tunning
color_space = ‘YCrCb’ # Can be RGB, HSV, LUV, HLS, YUV, YCrCb
orient = 9 # HOG orientations
pix_per_cell = (8,8) # HOG pixels per cell
cell_per_block = (2,2) # HOG cells per block
hog_channel = 0 # Can be 0, 1, 2, or “ALL”
spatial_size = (32, 32) # Spatial binning dimensions
hist_bins = 32 # Number of histogram bins
spatial_feat = True # Spatial features on or off
hist_feat = True # Histogram features on or off
hog_feat = True # HOG features on or off
y_start_stop = [None, None] # Min and max in y to search in slide_window()
سپس از Linear SVM classifier استفاده میکنیم.کلاس های میزان شده,تصادفی سازی,تقسیم بندی به مجموعه تست و آموزش از جمله کار هایی هستن که باید قبل از آموزش مدل روی اطلاعات انجام بشن.در این پروژه اطلاعات به صورت رندوم مخلوط شدند,به مجموعه های تست و آموزش تقسیم بندی شدند و نرمال سازی شده اند:
# Split up data into randomized training and test sets
rand_state = np.random.randint(0, 100)
X_train, X_test, y_train, y_test = train_test_split(
scaled_X, y, test_size=0.2, random_state=rand_state)
# Use a linear SVC
svc = LinearSVC()
# Train
svc.fit(X_train, y_train)
# Accuracy
svc.score(X_test, y_test)
با این مدل موفق میشیم که به دقت ۹۸.۹% برای مجموعه اطلاعات کوچک برسیم .مدل SVM این کار را در ۲۱.۰۵ ثانیه انجام داد.
جستو جوی Window scale:
الان که دیگه classifier رو آموزش دادیم باید روشی رو پیاده سازی کنیم تا اشیا را در تصویر جست و جو کنیم.تصاویر رو در زیر مجموعه هایی تقسیم بندی میکنیم تا بتونیم ویژگی هایی که در بالا گفتیم (binning, color histogram, HOG)رو استخراج کنیم و اون ها رو به classifier برای پیش بینی بینی بدیم.
به طور ایده آل ما باید زیر مجموعه تصویر را نزدیک خطوط شی برش بدیم تا ‘signature’به سادگی توسط classifier قابل تشخیص باشد.اما سایز شی ای که در تصویر ظاهر میشه رو نمیدونیم پس باید اون ها رو در window scale جست و جو کنیم.در اینجا باید مراقب باشیم چون به راحتی میتونه به تعدا زیادی پنجره برای جست وجو منجر بشه که باعث میشه pipeline ناکارآمد بشه و به آرامی عمل کنه.
اولین نکته اینه که ما نیمه بالایی عکس رو نادیده میگیریم چون انتظار نداریم وسیله ای در اونجا ظاهر بشه.بعدش از یک سری ویدیو گرفته شده از جاده استفاده کردیم برای اینکه بتونیم یه درکی از سایز اشیا با توجه عمق perspective بگیریم و اینکه سایز پنجره ها و نواحی که بهشون نیاز داریم رو بهتر بتونیم تعیین کنیم.
در نهایت تصمیم گرفتیم که از ۴ تا سایز پنجره با همپوشانی ۷۵% استفاده کنیم تا باهاشون نواحی خاصی از تصویر رو بگردیم.با آزمون و خطای بیشتر میتونه بهبود پیدا کنه اما در کل از ۱۳+۳۶+۵۸+۱۱۸=۲۲۵ پنجره برای جست و جوی هر فریم استفاده میکنیم.
# Window 1
window = (320,240)
cells_per_step = (2,2)
pix_per_cell=(40,30)
ystart = 400
ystop = 700
# Window 2
window = (240,160)
cells_per_step = (2,2)
pix_per_cell=(30,20)
ystart = 380
ystop = 620
# Window 3
window = (160,104)
cells_per_step = (2,2)
pix_per_cell=(20,13)
ystart = 380
ystop = 536
# Window 4
window = (80,72)
cells_per_step = (2,2)
pix_per_cell=(10,9)
ystart = 400
ystop = 490





در زیر یک سری جست و جوی sliding window میبینید.اما در این مرحله pipeline دارای چندین پنجره هم پوشانی در اشیا شناسایی شده است.توی مرحله بعدی تکنیکی رو با استفاده از نقشه حرارتی برای تخمین جعبه مرزی اعمال میکنیم.




نقشه حرارتی جعبه های مرزی و مثبت کاذب:
در این مرحله pipeline چندین پنجره روی خودرو های شناسایی شده قرار دارد و هم چنین مثبت کاذب را نشان می دهد.موارد مثبت کاذب که الان به طور درستی فیلتر شدند میتونند ماشین خودران رو مجبور به انجام اقداماتی بکنند که اجباری نیست و به طور بالقوه باعث تصادف ماشین بشن.به خاطر همین ما باید چند تا شناسایی روی یک شی رو به هم ربط بدیم و با استفاده از نقشه حرارتی از مثبت های کاذب خلاص شیم.
برای ایجاد نقشه حرارتیheat” (+=1)” را برای تمامی پیکسل های پنجره که classifier اون ها رو مثبت گزارش میده اضافه میکنیم.
heatmap = np.zeros_like(image[:,:,0])
# Add += 1 for all pixels inside each bbox
# Assuming each “box” takes the form ((x1, y1), (x2, y2))
heatmap[box[0][1]:box[1][1], box[0][0]:box[1][0]] += 1
برای خلاص شدن از منفی های کاذب یک آستانه روی نقشه حرارتی اعمال میکنیم.
# Zero out pixels below the threshold
heatmap[heatmap <= threshold] = 0
در اینجا یک سری مثال رو میبینید:



