
با توجه به شرایط اقتصادی سخت امروز جهان، تکنیکها و شاخصهای سنتی می تونن عملکرد ضعیف و حداقلی را از خود نشون بدهند.
ما در این مقاله قصد داریم که اخبار جهانی مربوط به ارزهای دیجیتال را به دادههای عددی تبدیل کنیم و با استفاده از یادگیری ماشین به مدل آموزش دهیم که سقوط و رشد هر ارز دیجیتال را پیشبینی کنه. پیادهسازی ما با استفاده از زبان برنامهنویسی پایتون انجام میشه.
” توجه داشته باشید که برای انجام این پروژه از ابزار OpenBlender استفاده شده و بعد از طی چند مرحله از پیادهسازی برای بهرهمندی از واحدهای پردازشی بیشتر و ادامه کار، باید حساب کاربری خودتون رو ارتقا دهید.”
پیشنیازها
- نصب پایتون ۳.۱ به بالا
- نصب pandas، sklearn و openblender
برای نصب این پکیجها میتونید از دستور زیر استفاده کنید:
pip install pandas OpenBlender scikit-learn
مرحله ۱. دریافت دیتاست
برای پیادهسازی این تسک میتونید از دیتاست مربوط به هر ارز دیجیتال استفاده کنید. ما دیتاست بیتکوین رو برای این پروژه انتخاب کردیم.
برای دسترسی به دیتاست بیتکوین میتونید روی این لینک کلیک کنید. با کلیک روی این لینک با صفحه زیر مواجه میشید.
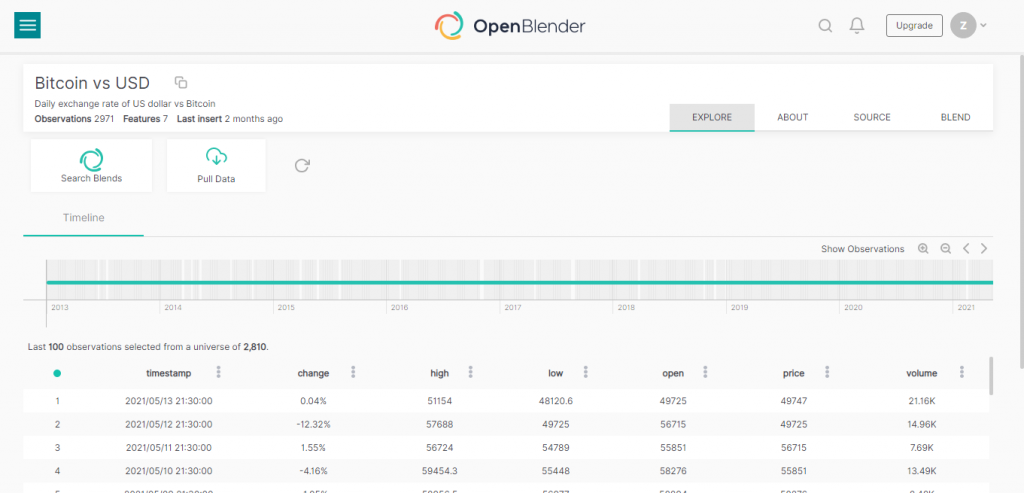
برای اینکه بتونید توکن مخصوص خودتون رو داشته باشید، اول باید در سایت OpenBlender حساب کاربری ایجاد کنید. بعد با کلیک روی pull data موجود در صفحه دیتاست بیتکوین میتونید به قطعه کد مربوط به API دسترسی پیدا کنید.
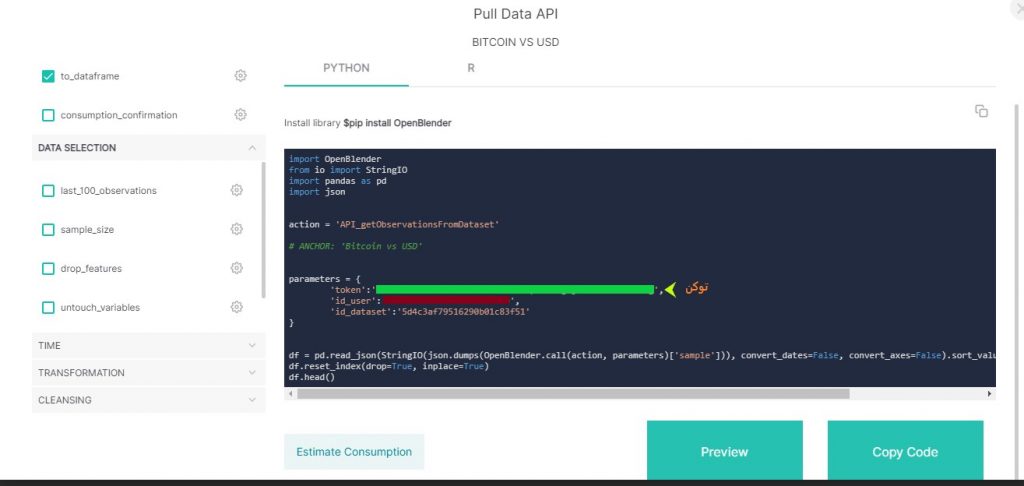
قصد ما اینه که داده های مربوط به اوایل تا اواسط سال ۲۰۲۰ استخراج کنیم:
import pandas as pd
import numpy as np
import OpenBlender
import json
token = 'YOUR_TOKEN_HERE'
action = 'API_getObservationsFromDataset'
# ANCHOR: 'Bitcoin vs USD'
parameters = {
'token' : token,
'id_dataset' : '5d4c3af79516290b01c83f51',
'date_filter':{"start_date" : "2020-01-01",
"end_date" : "2020-08-29"}
}
df = pd.read_json(json.dumps(OpenBlender.call(action, parameters)['sample']), convert_dates=False, convert_axes=False).sort_values('timestamp', ascending=False)
df.reset_index(drop=True, inplace=True)
df['date'] = [OpenBlender.unixToDate(ts, timezone = 'GMT') for ts in df.timestamp]
df = df.drop('timestamp', axis = 1)
در کد بالا بعد از این که دیتاست رو بر اساس پارامترهای مربوط به آی دی دیتاست و فیلتر تاریخ استخراج کردیم. با استفاده از sort_values دادهها رو بر اساس ستون timestamp بهصورت نزولی مرتب میکنیم.
حالا در کنار timestamp یه ستون دیگ تحت عنوان date ایجاد میکنیم و با استفاده از unixToDate، timestamp رو به تاریخ و ساعت خوانا تبدیل میکنیم و در این ستون قرار میدیم.
بعدازاین تبدیل، با استفاده از drop ستون timestamp رو از دیتا فریم حذف میکنیم.
بیایید یه نگاهی بندازیم به ساختار دادههای دیتاست:
print(df.shape)
df.head()
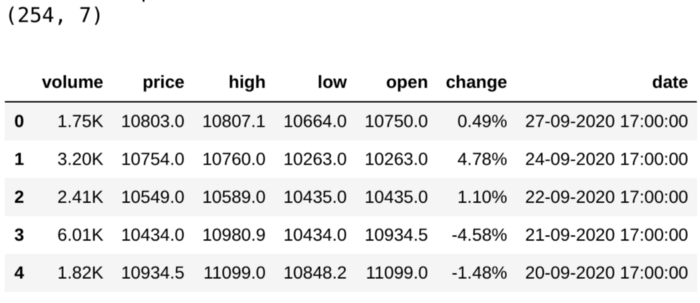
توجه داشته باشید که این مراحلی که برای پروژه پیشبینی تغییر قیمت بیتکوین در نظر گرفتیم با فاصله زمانی ۲۴ ساعت انجام میشه و شما میتونید این پیادهسازی رو برای هر دیتاست با هر فاصله زمانی (حتی هر ثانیه) انجام بدید.
مرحله ۲. تعریف ستون target
price و open ستونهایی هستن که ما در این تسک، زیاد با اونها سروکار داریم. منظور از open قیمت بیتکوین در شروع روز و price قیمت نهایی بیتکوین هست که تحت عنوان قیمت روز شناخته میشه. برای اینکه بتونیم نرخ تغییر قیمت مربوط به هر روز رو مشخص کنیم از تفاضل لگاریتمی price و open استفاده میکنیم.
حالا چرا به جای خود تفاضل از تفاضل لگاریتمی استفاده میکنیم؟
دلیلش اینه که وقتی تفاضل دو عدد زیاد نیست و پیوستگی بین اونها زیاده، بهتره از لگاریتم برای تبدیل تفاضل مطلق به تفاضل نسبی (درصد) استفاده کنیم.
df['log_diff'] = np.log(df['price']) - np.log(df['open'])
df
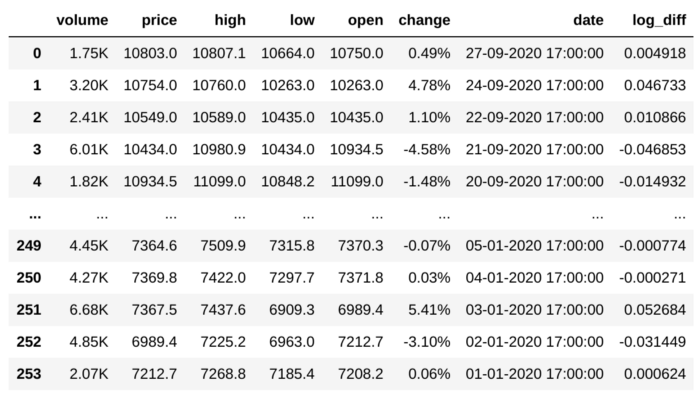
‘log_diff’ ستونیه که برای قرار دادن نتیجه تفاضل این دو ستون درنظرگرفتیم. وابستگی بین این ستون و ستون change خیلی زیاد هست و به همین خاطر عملاً معادل همدیگه هستند.
حالا بهتره به شکلهای زیر هم یه نگاهی بندازیم تا رابطه تغییرات هر کدوم رو بهتر درک کنیم:
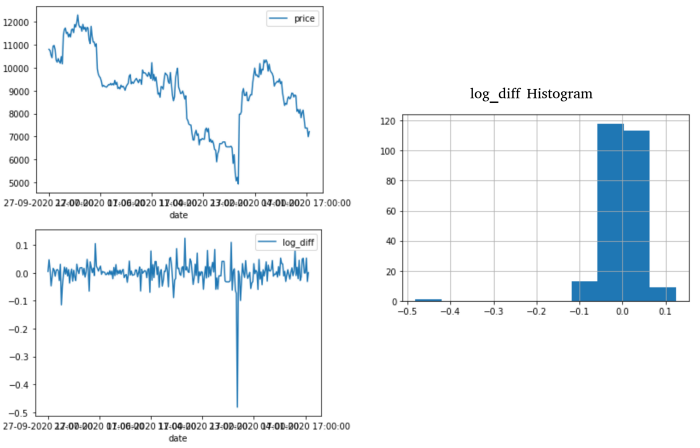
نمودار هیستوگرام نشون میده که مقادیر ستون log_diff در طول کل سال یه رفتار نزولی از خودشون نشون داده و تغییری که برای بازه -۱.۰ تا ۱.۰ وجود داره یه انحراف خیلی شدید هست.
حالا نوبت اینه که یه ستون target ایجاد کنیم:
df['target'] = [1 if log_diff > 0 else 0 for log_diff in df['log_diff']]
df
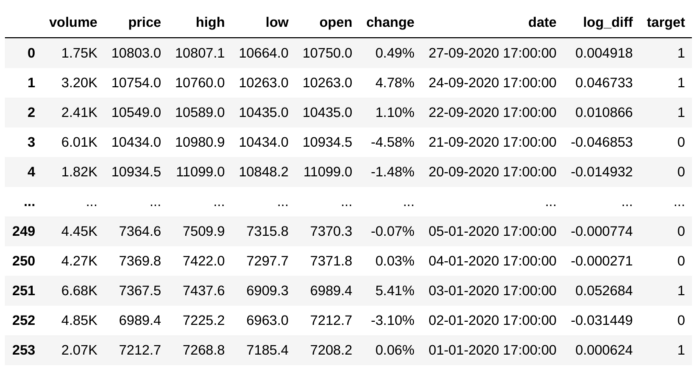
با استفاده از این کد، مقادیر log_diff رو به باینری تبدیل میکنیم در target نظیرش قرار میدیم. به این صورت که اگر log_diff رکورد موردنظر کوچکتر از صفر باشه، مقدار target برابر صفر و اگر بزرگتر از یک باشه، مقدار target برابر یک میشه.
ایجاد ستون target باعث شد که بهراحتی تشخیص بدیم تغییرات قیمت بیتکوین در روزهای مختلف مثبت (۱) بوده یا منفی (۰) -> (با استفاده از این متغیر میشه بهراحتی یه تصمیم تجاری گرفت.)
مرحله ۳. دریافت دیتاست اخبار برای ترکیب با دیتاست بیتکوین
حالا میخوایم از یه دیتاست اخبار دیگه استفاده کنیم که ستون timestamp این دو تا دیتاست باهم اشتراک داشته باشند و با جوین کردن این دو دیتاست از طریق ستون timestamp به دادههای متنی و اخبار مربوط به هر یک از تاریخها دسترسی پیدا کنیم.
ما بهراحتی میتونیم این کار رو از طریق API سایت OpenBlender انجام بدیم ولی اول باید یه متغیر Unix Timestamp ایجاد کنیم.
Unix Timestamp تعداد ثانیهها از سال ۱۹۷۰ در UTC هست و یه قالب بسیار مناسبی برای این کار محسوب میشه چون در همه منطقههای زمانی دنیا یکی هست.
ستون date که قبلاً ایجاد کردیم با فرمت مشخص آماده این هست که با استفاده از dateToUnix به timestamp تبدیل بشه و در یک ستون جدید قرار بگیره.
بعد نوبت اینه که فقط ستونهای مهم و کلیدی دیتا فریم (‘date’، ‘timestamp’، ‘price’ و ‘target’) رو نگه داریم و در ادامه از دادههای مربوط به اون استفاده کنیم.
format = '%d-%m-%Y %H:%M:%S'
timezone = 'GMT'
df['u_timestamp'] = OpenBlender.dateToUnix(df['date'],
date_format = format,
timezone = timezone)
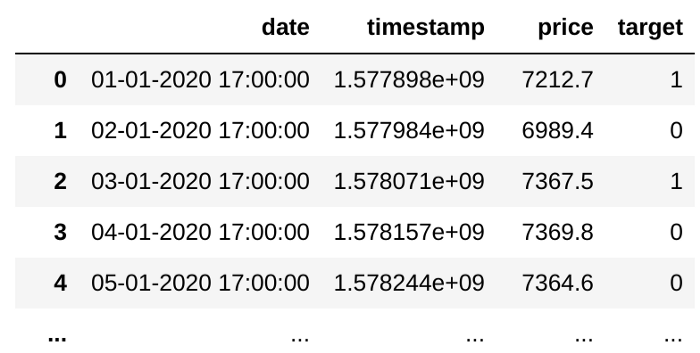
df = df[['date', 'timestamp', 'price', 'target']]
df.head()
خب بیایید دیتاست های مناسبی رو پیدا کنیم که با این دیتاست اشتراک زمانی دارند.
search_keyword = 'bitcoin'
df = df.sort_values('timestamp').reset_index(drop = True)
print('From : ' + OpenBlender.unixToDate(min(df.timestamp)))
print('Until: ' + OpenBlender.unixToDate(max(df.timestamp)))
OpenBlender.searchTimeBlends(token,
df.timestamp,
search_keyword)
بعد از مشخص کردن کلمه کلیدی جستجو، دادههای دیتا فرم رو بر اساس ستون timestamp مرتب میکنیم.
توجه داشته باشید که اگر reset_index(drop = True) رو قرار ندید، دو تا ستون برای ایندکس لحاظ میشه. یکی از اونا برای ایندکس رکوردها بعد از مرتبسازی هست که الآن حالت نامرتب دارند چون بر اساس ‘timestamp’ مرتب شدن نه ایندکس. ستون دیگه هم ایندکس جدیده که ترتیب منظم و صعودی داره و بعد از مرتبسازی لحاظ شده. استفاده از این قطعه کد باعث حذف ستون ایندکس قدیمی میشه.
بهاینترتیب بر اساس کلمه کلیدی، لیست دیتاست هایی که ‘timestamp’ اونها با ‘timestamp’ دیتاست بیتکوین اشتراک دارند، در خروجی ظاهر میشه.
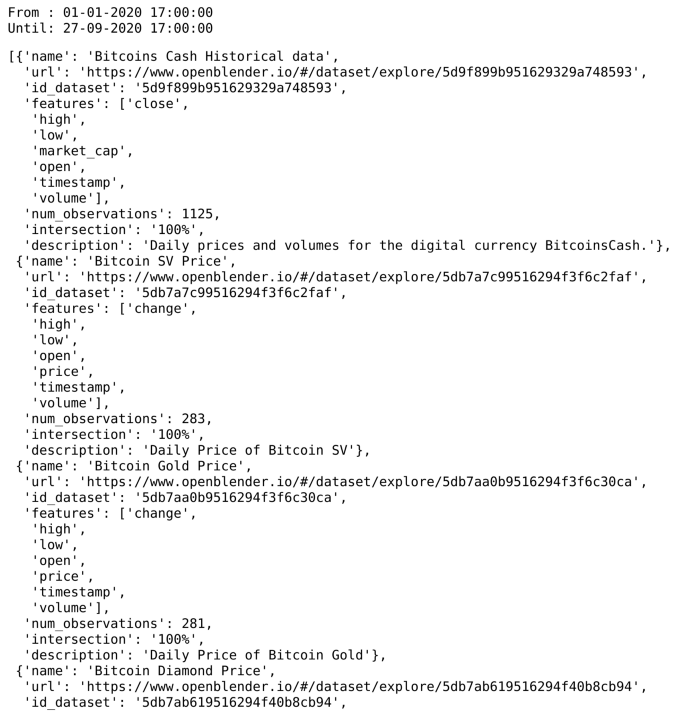
همه اطلاعات مربوط به دیتاست مثل اسم، توصیف، url و ویژگیها در داخل این لیست قرار داره ولی مهم میزان اشتراک زمانی اونها با دیتاست اصلی ما هست.
بهترین دیتاستی که میتونیم برای ادامه کار انتخاب کنیم، دیتاست اخبار بیت کوین هست که میتونه اطلاعات جالبی رو در اختیارمون قرار بده.
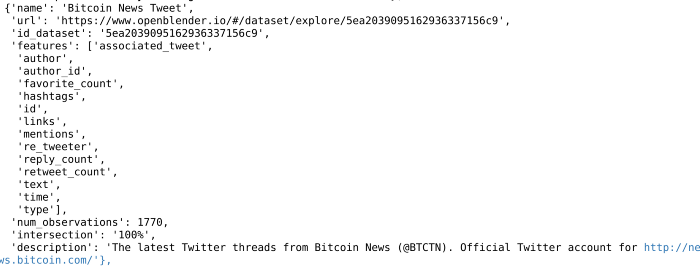
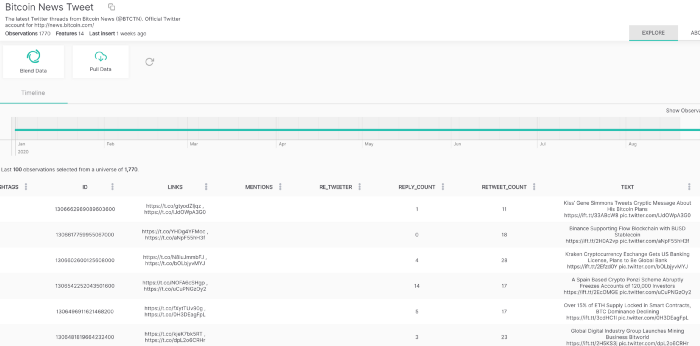
حالا تو این دیتاست اخبار فقط ستون text هست که جالبه و اخبار مربوط به بیتکوین رو در روزهای مختلف شامل میشه. تو این بخش، از طریق جوین دو دیتاست، ویژگی اخبار بیتکوین ۲۴ ساعت پیش رو به دیتا فریم قبلی اضافه میکنیم.
# We need to add the 'id_dataset' and the 'feature' name we want.
blend_source = {
'id_dataset':'5ea2039095162936337156c9',
'feature' : 'text'
}
# Now, let's 'timeBlend' it to our dataset
df_blend = OpenBlender.timeBlend( token = token,
anchor_ts = df.timestamp,
blend_source = blend_source,
blend_type = 'agg_in_intervals',
interval_size = 60 * 60 * 24,
direction = 'time_prior',
interval_output = 'list',
missing_values = 'raw')
df_anchor = pd.concat([df, df_blend.loc[:, df_blend.columns != 'timestamp']], axis = 1)
df.head()
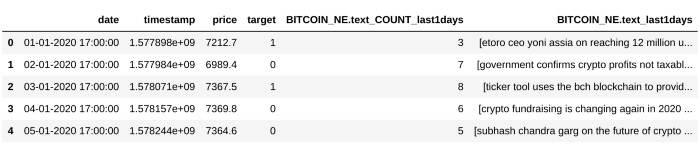
بعدازاینکه آی دی دیتاست رو از لینک برداشیم، ویژگی موردنظر ((text رو هم مشخص میکنیم. بعد نوبت به این میرسه که این دیتاست رو توسط ستون مشترک timestamp با دیتا فریم اصلی جوین بدیم و متناسب با پارامترهایی که مقداردهی شد، با استفاده از concat دیتا فریم خروجی رو با دیتا فریم اصلی ترکیب کنیم.
حالا بهتره که یکم راجع به پارامترهای timeBlend صحبت کنیم:
token -> همون توکنی هست که وقتی حساب کاربری ایجاد کردید، تو قیمتpull data بهعنوان توکن مخصوص شما قرار گرفته بود.
anchor_ts -> آرایهای از Unix timestamp ها هست که قراره دیتاست ها از طریق اون با هم ترکیب بشن چون دادههای اصلی فقط قراره از طریق ستون timestamp با دادههای خارجی ترکیب بشن.
blend_source -> یه شی از نوع JSON هست که اطلاعات مربوط به دیتاست خارجی رو شامل میشه. ویژگیها و آی دی دیتاستی که ما نیاز داریم در داخل این متغیر تعریف شده.
blend_type -> نوع ترکیبی هست که برای جمعآوری دادهها تعیین میشه. در این بخش از ‘agg_in_intervals’ استفاده شده چون میخوایم دادههای مربوط به بازه ۲۴ ساعته رو جمعآوری کنیم.
direction -> اگر نوع ترکیب رو ‘agg_in_intervals’ مشخص کرده باشیم، باید direction رو هم مشخص کنیم ولی در غیر این صورت نیازی به مقداردهی این پارامتر نیست. ”time_prior باعث میشه که بهمحض برخورد با یه timestamp یکسان، دادهها رو از قسمت text مربوط به اون تاریخ جمعآوری کنه.
inverval_size -> با استفاده از این پارامتر، اندازه فاصله زمانی رو با واحد ثانیه مشخص میکنیم. (۶۰ * ۶۰ * ۲۴ ثانیه همون ۲۴ ساعته)
interval_output -> دادههایی که جمعآوری میشن، تحت قالب نوع این پارامتر در کنار هم قرار میگیرن که تو این بخش نوعش رو list تعیین کردیم.
missing_values -> این پارامتر مشخص میکنه که وقتی با رکوردی مواجه شدیم که مقدارشو از دست داده، چیکار کنیم. حالا که مقدارشو ‘raw’ قرار دادیم اینجوری عمل میکنه که به جای اون مقادیر ازدسترفته، NAN برمیگردنه.
حالا پارامترهای دیگه ای هم هستن که متناسب با نوع کاربرد میتونین ازشون استفاده کنین.
در آخر کار با استفاده از concat دیتا فریم جدید رو به دیتا فریم قبلی اضافه میکنیم. فقط چون نیازی نیست که ویژگی مشترک (timestamp) دو بار تکرار بشه. همه ستونها (axis = 1) به غیر از اونو به دیتا فریم قبلی اضافه میکنیم.
حالا به دیتاست قبلی ما ۲ تا ستون دیگه هم اضافه شده که یکیش لیست مربوط به متنهای اخبار با فاصلههای زمانی ۲۴ ساعته (روزهای قبل) و اون یکی تعداد اخبار یا همون طول لیست هست.
حالا بیایید یکم دقیقتر باشیم و سعی کنیم اخبار مثبت و منفی رو از همدیگه جدا کنیم. این کار رو با اضافه کردن فیلتر انجام میدیم.
# We add the ngrams to match on a 'positive' feature.
positive_filter = {'name' : 'positive',
'match_ngrams': ['positive', 'buy',
'bull', 'boost']}
blend_source = {
'id_dataset':'5ea2039095162936337156c9',
'feature' : 'text',
'filter_text' : positive_filter
}
df_blend = OpenBlender.timeBlend( token = token,
anchor_ts = df.timestamp,
blend_source = blend_source,
blend_type = 'agg_in_intervals',
interval_size = 60 * 60 * 24,
direction = 'time_prior',
interval_output = 'list',
missing_values = 'raw')
df = pd.concat([df, df_blend.loc[:, df_blend.columns != 'timestamp']], axis = 1)
# And now the negatives
negative_filter = {'name' : 'negative',
'match_ngrams': ['negative', 'loss', 'drop', 'plummet', 'sell', 'fundraising']}
blend_source = {
'id_dataset':'5ea2039095162936337156c9',
'feature' : 'text',
'filter_text' : negative_filter
}
df_blend = OpenBlender.timeBlend( token = token,
anchor_ts = df.timestamp,
blend_source = blend_source,
blend_type = 'agg_in_intervals', #closest_observation
interval_size = 60 * 60 * 24,
direction = 'time_prior',
interval_output = 'list',
missing_values = 'raw')
df = pd.concat([df, df_blend.loc[:, df_blend.columns != 'timestamp']], axis = 1)
timeBlend درست مثل کد قبل انجام میشه با این تفاوت که اینجا برای blend_source یه ویژگی جدید اضافه شده و اونم دیکشنری مربوط به فیلتر مثبت و منفی هست که بهصورت جدا برای هر کدوم تعریف شده. وجود هر کدوم از مقادیر match_ngrams باعث میشه که خبر موردنظر در دسته مثبت یا منفی قرار بگیره.
بعد این ترکیب، حالا ۴ تا ستون دیگر هم داریم که شامل لیست اخبار مثبت، تعداد اخبار مثبت، لیست اخبار منفی و تعداد اخبار منفی میشه.

حالا وقتشه که با استفاده از ماتریس همبستگی، میزان همبستگی تعداد اخبار مثبت و منفی رو با target بررسی کنیم.
ماتریس همبستگی برای دادههای عددی تعریف میشه و مقدار مربوط به هر خانه آن میزان همبستگی سطر و ستون نظیر رو نشون میده. هر چه قدر مقدار یه خانه از ماتریس بیشتر باشه نشون میده که این دو سطر و ستون نظیر همبستگی بیشتری به هم دارن، اگر یکی بیشتر باشه اونیکی هم بیشتر میشه.
حالا اگر مقدار یه خانه کمتر باشه (حتی منفی) نشون میده که همبستگی بین سطر و ستون موردنظر کمه و تقریباً با همدیگه رابطه معکوس دارند.
features = ['target', 'BITCOIN_NE.text_COUNT_last1days:positive', 'BITCOIN_NE.text_COUNT_last1days:negative']
df_anchor[features].corr()['target']

ماتریس همبستگی بین target و سایر دادههای عددی نشون میده که همبستگی بین target و تعداد اخبار مثبت، زیاد و همبستگی بین target با تعداد اخبار منفی کمه. این کاملاً مشخصه که هرچقدر مقدار target زیاد باشه (۱)، تعداد اخبار مثبت زیاد میشه چون قیمت بیتکوین رشد داشته و در مقابل، تعداد اخبار منفی هم کمتر میشه و برعکس.
حالا ممکنه این سؤال پیش بیاد که چرا این خروجی حالت ماتریس نداره؟ چون تو این قطعه کد، df_anchor[features].corr()[‘target’] مشخص شدن target بعد corr باعث شده که فقط ستون target رو درنظربگیره.
خب دیگ وقت این رسیده که با استفاده از TextVectorizer دادههای متنی رو به دادههای عددی تبدیل کنیم و ویژگیهای توکن شده زیادی رو به دست بیاریم.
تو این پروژه از TextVectorizer مربوط به OpenBlender روی ویژگی ‘text’ دیتاست اخبار بیتکوین استفاده میکنیم.
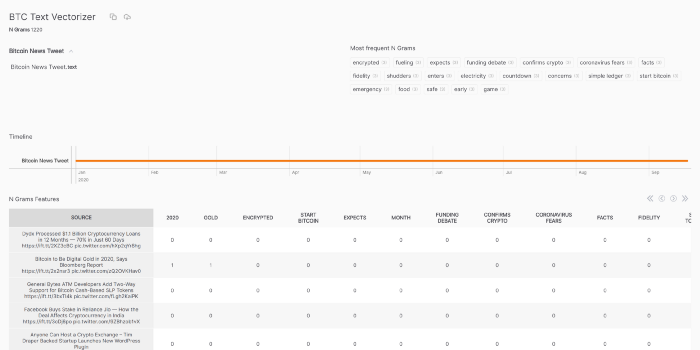
حالا بیایید این دادهها رو با دیتا فریم خودمون ترکیب کنیم. برای ترکیب از همون کد استفاده میکنیم فقط با این تفاوت که blend_source رو با id_textVectorizer مقداردهی میکنیم.
# BTC Text Vectorizer
blend_source = {
'id_textVectorizer':'5f739fe7951629649472e167'
}
df_blend = OpenBlender.timeBlend( token = token,
anchor_ts = df_anchor.timestamp,
blend_source = blend_source,
blend_type = 'agg_in_intervals',
interval_size = 60 * 60 * 24,
direction = 'time_prior',
interval_output = 'list',
missing_values = 'raw') .add_prefix('VEC.')
df_anchor = pd.concat([df_anchor, df_blend.loc[:, df_blend.columns != 'timestamp']], axis = 1)
df_anchor.head()
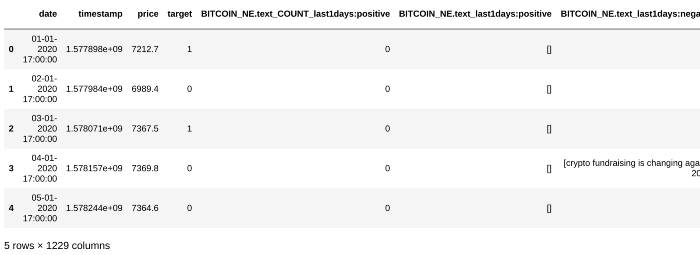
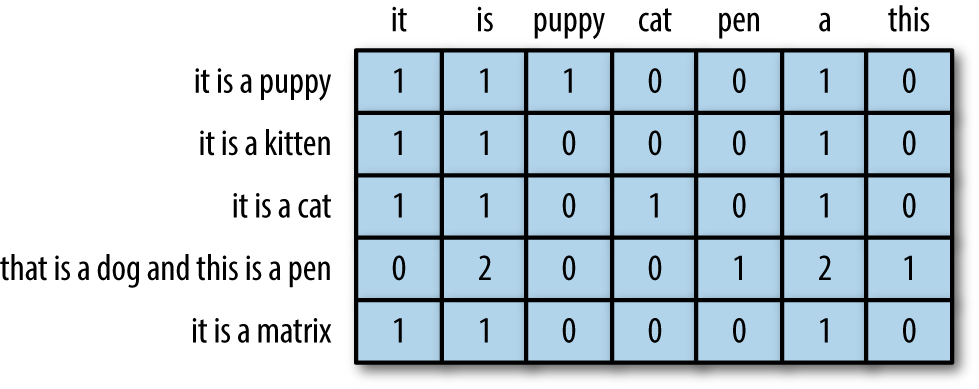
بهتره یکم راجع به طرز کار TextVectorizer حرف بزنیم. کلماتی که برای این TextVectorizer در نظر گرفته شدن در این لینک مشخص شدند. این کلمات یه حالت برداری دارند. مثل تصویر زیر:
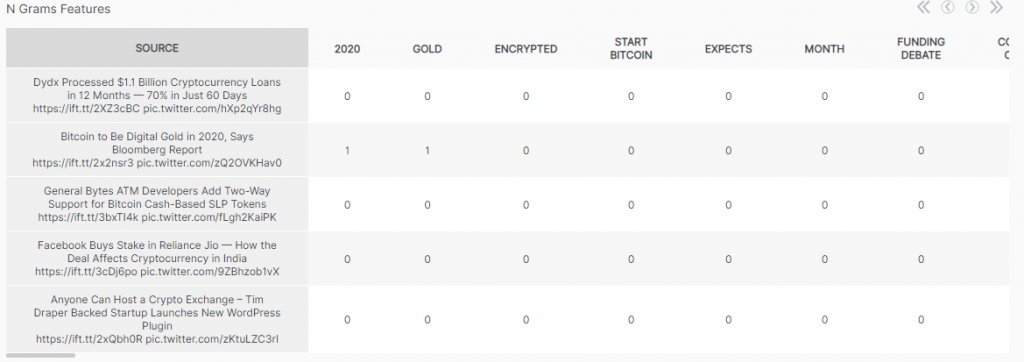
حالا این شکل رو برای اخبار بیتکوین درنظر میگیریم. بردار مربوط به هر خبر با این کلماتی که از قبل مشخص شدن، مقداردهی میشن. اگر کلمه موردنظر (تک کلمهای یا بیشتر) در خبر وجود داشته باشه که خانه مربوط به اون یک میشه اگر نباشه، ۰ میشه. در شکل زیر بردار مربوط به ۴ خبر مقداردهی شده.
حالا نوبت ترکیب بردارهای عددی مربوط به لیست اخبار با دیتافریم اصلی هست:
# BTC Text Vectorizer
blend_source = {
'id_textVectorizer':'5f739fe7951629649472e167'
}
df_blend = OpenBlender.timeBlend( token = token,
anchor_ts = df_anchor.timestamp,
blend_source = blend_source,
blend_type = 'agg_in_intervals',
interval_size = 60 * 60 * 24,
direction = 'time_prior',
interval_output = 'list',
missing_values = 'raw') .add_prefix('VEC.')
df_anchor = pd.concat([df_anchor, df_blend.loc[:, df_blend.columns != 'timestamp']], axis = 1)
df_anchor.head()
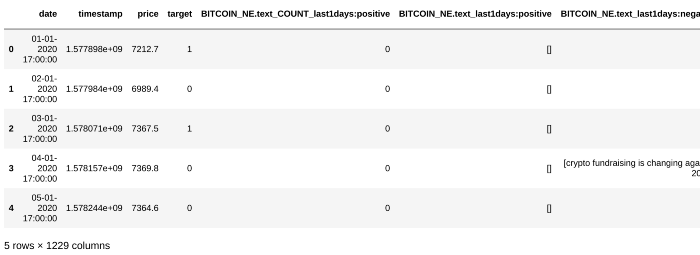
بعدازاین ترکیب ۱۲۲۰ ستون دیگه به دیتا فرم ما اضافه میشه که دارای مقدار باینری هستند (کلمات موردنظر در لیست اخبار وجود دارند یا نه).
مرحله ۴. اعمال ML و مشاهده نتایج
تو این قسمت دیگ وارد بخش نهایی و اصلی میشیم. به این صورت که مدل رو ایجاد میکنیم و آموزش میدیم.
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
# We drop correlated features because with so many binary
# ngram variables there's a lot of noise
corr_matrix = df_anchor.corr().abs()
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))
df_anchor.drop([column for column in upper.columns if any(upper[column] > 0.5)], axis=1, inplace=True)
# Now we separate in train/test sets
X = df_.loc[:, df_.columns != 'target'].select_dtypes(include=[np.number]).drop(drop_cols, axis = 1).values
y = df_.loc[:,['target']].values
div = int(round(len(X) * 0.2))
X_train = X[:div]
y_train = y[:div]
X_test = X[div:]
y_test = y[div:]
# Finally, we perform ML and see results
rf = RandomForestRegressor(n_estimators = 1000, random_state=0)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
df_res = pd.DataFrame({'y_test':y_test[:, 0], 'y_pred':y_pred})
threshold = 0.5
preds = [1 if val > threshold else 0 for val in df_res['y_pred']]
print(metrics.confusion_matrix(preds, df_res['y_test']))
print('Accuracy Score:')
print(accuracy_score(preds, df_res['y_test']))
print('Precision Score:')
print(precision_score(preds, df_res['y_test']))
در بخش اول کد، ماتریس همبستگی بین ویژگیهای عددی رو ایجاد میکنیم. بعد اون بخشی که داخل where قرار داره، حکم شرط رو داره. با توجه به اینکه این ماتریس، همبستگی بین ویژگیها رو بهصورت دو به دو بررسی میکنه پس عملاً به همه خونه هاش نیاز نداریم. چون ویژگیهای نظیر به نظیر دو بار مقداردهی میشن یه بار در مثلث بالای محور ماتریس یه بار هم در مثلث پایین محور ماتریس. خود محور هم که نیاز نیست چون همه ویژگیها با خودشون همبستگی کامل دارند پس k=1 میشه.
بعد با استفاده از drop همه اون ستونهایی که همبستگیشون بالای ۰.۵ هست رو حذف میکنیم چون وجود ستونهای باینری زیاد باعث نویز بیشتر میشه.
حالا نوبت اینه که دیتاست رو به مجموعه آموزش و تست تقسیم کنیم. x میشه همه دادههای عددی به جز مقادیر ستون target و y هم میشه مقادیر ستون target. تقسیمبندی به این صورت انجام میشه که ۸۰ درصد دیتاست رو بهعنوان مجموعه آموزش و ۲۰ درصد بقیه رو بهعنوان مجموعه تست در نظرمیگیریم.
بعد از این تقسیمبندی دیتاست، نوبت به تکمیل مدل و مشاهده نتایج میرسه. ما در این تسک از RandomForestRegressor استفاده میکنیم. random forest یه تخمینگر (estimator) متا هست که چند تا درخت تصمیم طبقهبندی رو روی دیتاست فیت میکنه و از میانگینگیری برای بهبود دقت پیشبینی و کنترل over-fitting استفاده میکنه. تعداد درخت تصمیم مربوط به این پیادهسازی ۱۰۰۰ هست.
بعدازاینکه آموزش و فیت انجام شد، نتایج واقعی و نتایج پیشبینیشده رو در دیتا فریم df_res ذخیره میکنیم.
حالا برای بررسی معیارها، یه ترشولد رو برای مقادیر پیشبینیشده برای target تعریف میکنیم و مقدار ۰.۵ رو براش قرار میدیم.
بعد یه آرایه تعریف میکنیم:
- اگر مقدار پیشبینیشده (df_res[‘y_pred’])، بزرگ تر از ۰.۵ باشه، ۱ رو در این آرایه قرار میدیم.
- اگر مقدار پیشبینیشده کمتر از ۰.۵ باشه، ۰ رو در آرایه قرار میدیم.
خروجی مربوط به نمره معیارهای دقت Accuracy و Precision بهصورت زیر است:

تصویر زیر جزئیات دقیقتری در مورد نتیجه رو شامل میشه:
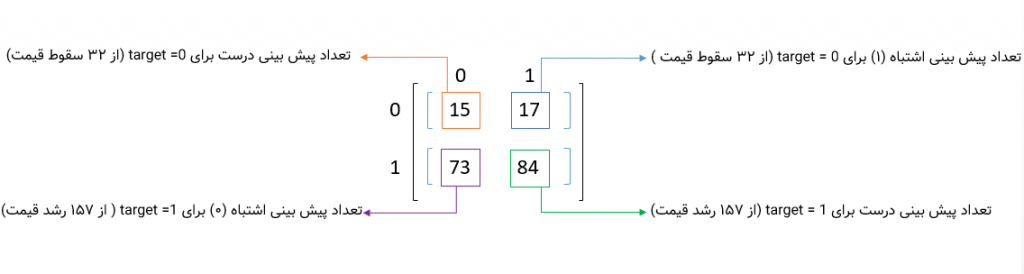
بااینکه نمره Accuracy زیاد خوب نیست ولی ما بیشتر به نمره Precision علاقه داریم چون هدف ما اینه که تشخیص بدیم در روزهای آینده شاهد رشد قیمت بیتکوین میشیم یا سقوط قیمت.
ماتریس درهمریختگی حاوی اطلاعات زیر هست:
- مدل ما ۱۰۲ بار، رشد (۱) رو پیشبینی کرده که از این تعداد، ۸۴ مورد رشد واقعی بوده و ۱۷ مورد دیگه بهاشتباه، رشد پیشبینیشده و درواقع سقوط قیمت (۰) بوده.
- در کل، ۱۵۷ رشد قیمت وجود داره. مدل ما ۸۴ تاشو درست پیشبینی کرده و ۷۳ مورد دیگرو بهاشتباه سقوط تشخیص داده.
- در کل، ۳۲ سقوط قیمت وجود داره که از این ۳۲ تا ۱۵ مورد بهدرستی پیشبینی شدن و ۱۷ مورد هم بهاشتباه، رشد قیمت پیشبینیشده.
- بهعبارتدیگر، اگر اولویت ما شناسایی سقوط قیمت و جلوگیری از ضرر هست (حتی اگر چند رشد قیمت رو از دست بدیم)، این مدل در این دوره میتونه عملکرد خوبی از خودش نشون بده.
- اگر اولویت ما جلوگیری از دست رفتن رشد قیمتها باشه (حتی در صورت وقوع چند سقوط)، این مدل با این ترشولد بههیچوجه گزینه خوبی نخواهد بود.
امیدواریم که از این پست آموزشی لذت برده باشید و یادگیری نحوه پیاده سازی سیستم پیشبینی تغییرات نرخ بیت کوین بر اساس اخبار جهانی با استفاده از یادگیری ماشین براتون مفید واقع بشه.
برای هرگونه سوال در زمینه آموزش ها فقط کافیه روی لینک واتساپ یا تلگرام (در زیر همین پست) کلیک کنید. یا با شماره تماس بالای صفحه سایت تماس بگیرید.