
تو این دوره که هممون حداقل تو یه گروه واتس اپ عضو هستیم، تجزیه و تحلیل چت گروهی واتس اپ میتونه نتایج جالب و مفیدی رو در اختیارمون قرار بده. به همین دلیله که تو این مقاله نحوه تجزیه و تحلیل چت گروهی واتس اپ با علم داده یا data science رو به شما عزیزان آموزش میدیم.
اگر نمیدونید که چطوری پیام ها رو از هر چت استخراج کنید، فقط کافیه که چت دلخواه خودتونو باز کنید و روی آیکون ۳ نقطه بالای چت کلیک کنید و بعد more و در ادامه explore chat رو انتخاب کنید. بعد، با انتخاب share فایل موردنظر رو به هر جایی که میخواید ارسال کنید (ترجیحاً ایمیل).
این چتی که دانلود کردید، در کل نیازی به هیچ عمل آماده سازی و پاکسازی نداره و به طور مستقیم میتونه برای پیاده سازی این تسک استفاده بشه. حالا بیایید تجزیه و تحلیل چت گروهی واتس اپ رو شروع کنیم. اول، کار رو با ایمپورت پکیج های لازم شروع میکنیم:
import regex
import pandas as pd
import numpy as np
import emoji
import plotly.express as px
from collections import Counter
import matplotlib.pyplot as plt
from os import path
from PIL import Image
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
% matplotlib inline
تجزیه و تحلیل چت گروهی واتس اپ
با این که این داده ها آماده استفاده هستن ولی هنوز نیاز به این داریم که فرمت تاریخ و ساعت چت ها رو تغییر بدیم که این کار به راحتی قابل انجامه. برای انجام این تغییر باید یه تابعی تعریف کنیم که هر خطی که با یه تاریخ شروع میشه رو به عنوان یه پیام منحصربفرد شناسایی کنه:
def startsWithDateAndTime(s):
pattern = '^([0-9]+)(\/)([0-9]+)(\/)([0-9]+), ([0-9]+):([0-9]+)[ ]?(AM|PM|am|pm)? -'
result = re.match(pattern, s)
if result:
return True
return False
فرمت تاریخ و ساعت رو به عنوان الگو مشخص میکنیم و بعد با استفاده از re.match الگوی موردنظر رو با پارامتر ورودی تطابق میدیم تا تشخیص بدیم که با یه تاریخ/ساعت شروع شده یا نه.
حالا یه تابع رو برای استخراج نام های کاربری موجود داخل چت ها تعریف میکنیم که این نام های کاربری رو به عنوان authors میشناسیم:
def FindAuthor(s):
s=s.split(":")
if len(s)==2:
return True
else:
return False
خب تو این بخش یه تابع رو برای جداسازی همه اطلاعات از یکدیگر ایجاد میکنیم تا بتونیم به راحتی از این اطلاعات به عنوان dataframe پانداس استفاده کنیم:
def getDataPoint(line):
splitLine = line.split(' - ')
dateTime = splitLine[0]
date, time = dateTime.split(', ')
message = ' '.join(splitLine[1:])
if FindAuthor(message):
splitMessage = message.split(': ')
author = splitMessage[0]
message = ' '.join(splitMessage[1:])
else:
author = None
return date, time, author, message
کد زیر به ما کمک میکنه که به داده ها دسترسی پیدا کنیم. اگر از یه IDE یا Jupyter notebook یا Google Colab استفاده میکنید، می تونید از کد زیر استفاده کنید منتها اگر از Jupyter notebook یا Colab استفاده نمیکنید باید از درست بودن مسیر دیتاست روی سیستم خودتون مطمئن بشید.
from google.colab import files
uploaded = files.upload()
data = [] # List to keep track of data so it can be used by a Pandas dataframe
conversation = 'WhatsApp Chat (1).txt'
with open(conversation, encoding="utf-8") as fp:
fp.readline() # Skipping first line of the file because contains information related to something about end-to-end encryption
messageBuffer = []
date, time, author = None, None, None
while True:
line = fp.readline()
if not line:
break
line = line.strip()
if startsWithDateAndTime(line):
if len(messageBuffer) > 0:
parsedData.append([date, time, author, ' '.join(messageBuffer)])
messageBuffer.clear()
date, time, author, message = getDataPoint(line)
messageBuffer.append(message)
else:
messageBuffer.append(line)
حالا بیاید این داده ها رو در dataframe قرار بدیم و یه نگاهی داشته باشیم به ساختار این دیتافریم:
df = pd.DataFrame(parsedData, columns=['Date', 'Time', 'Author', 'Message']) # Initialising a pandas Dataframe.
df["Date"] = pd.to_datetime(df["Date"])
df.tail(20)
دیتافریم بالایی خیلی خوب و تمیز به نظر میرسه. حالا نوبت اینه که تجزیه و تحلیل چت گروهی واتس اپ رو شروع کنیم:
برای دریافت کل authors:
منظور از authors یا نویسنده ها کاربرانی هستن که در گروه عضو هستن و در چت مشارکت دارند. حالا بیاید اسم این کاربرها رو استخراج کنیم:
df.Author.unique()
array([None, ‘Aman Kharwal’, ‘Sahil Pansare’, ‘+۹۱ ۹۷۳۸۶ ۳۰۲۶۶’, ‘+۹۱ ۹۷۲۱۷ ۹۵۹۵۸’, ‘+۹۱ ۸۳۶۹۶ ۲۱۹۱۶’, ‘+۹۱ ۸۸۰۶۴ ۵۱۷۵۱’, ‘+۹۱ ۹۶۶۲۷ ۷۸۵۵۸’, ‘+۹۱ ۹۰۲۵۲ ۵۱۲۰۴’, ‘+۹۱ ۷۰۶۶۵ ۴۰۴۹۸’, ‘+۹۱ ۸۴۴۷۱ ۸۵۰۹۳’, ‘+۹۱ ۷۹۰۶۵ ۵۶۷۴۳’, ‘+۶۰ ۱۱-۵۶۸۹ ۲۰۴۰’, ‘+۹۱ ۹۹۱۵۰ ۱۵۲۸۱’, ‘+۹۱ ۹۳۹۸۳ ۱۸۳۹۳’, ‘+۹۱ ۹۵۶۱۲ ۷۷۷۰۶’, ‘+۹۱ ۹۸۲۲۴ ۳۵۴۳۳’, ‘+۹۱ ۹۸۶۷۳ ۷۴۲۸۷’, ‘+۹۱ ۷۴۴۷۴ ۸۰۱۹۰’, ‘+۹۱ ۸۷۲۸۸ ۴۸۰۴۱’, ‘+۹۱ ۸۶۱۰۶ ۹۰۴۶۱’, ‘+۹۱ ۷۶۲۰۰ ۱۴۰۵۸’, ‘+۹۱ ۹۸۵۰۷ ۳۴۹۱۲’, ‘+۹۱ ۷۷۸۶۸ ۶۸۹۸۷’, ‘+۹۱ ۷۷۳۸۷ ۱۲۸۰۴’, ‘+۹۱ ۹۸۱۱۹ ۱۴۷۴۱’, ‘+۹۱ ۹۹۷۲۴ ۹۱۴۵۳’, ‘+۹۱ ۷۰۳۸۲ ۵۰۷۰۱’, ‘+۹۱ ۸۳۴۴۸ ۲۶۳۱۴’, ‘+۹۱ ۹۵۰۰۰ ۲۸۵۳۶’, ‘+۹۱ ۹۳۷۰۳ ۴۹۰۶۳’, ‘+۹۱ ۹۳۸۰۸ ۲۲۶۴۵’, ‘+۹۱ ۹۹۱۶۵ ۶۶۶۸۳’, ‘+۹۱ ۷۰۴۲۴ ۷۳۴۶۰’, ‘Sumehar’, ‘+۹۱ ۸۶۰۰۲ ۹۴۷۶۱’], dtype=object)
با توجه به خروجی فقط ۳ کاربر با اسم خودشون داخل این آرایه قرار دارن (مخاطبانی که شمارشون در گوشی ذخیره شده). از داده ها همونطوری که هست استفاده میکنیم و ۳ کاربر که اسمشون مشخصه رو بررسی میکنیم.
تجزیه و تحلیل چت گروهی واتس اپ: وضعیت گروه
حالا بیایید با نگاه به آمار، یه سری داده ها رو تجزیه و تحلیل کنیم. اول یه تابع تعریف میکنیم که متن، فایل های رسانه ای، لینک ها و ایموجی ها رو از یکدیگه جدا کنه:
media_messages = df[df['Message'] == '<Media omitted>'].shape[0]
print(media_messages)
def split_count(text):
emoji_list = []
data = regex.findall(r'\X', text)
for word in data:
if any(char in emoji.UNICODE_EMOJI for char in word):
emoji_list.append(word)
return emoji_list
df["emoji"] = df["Message"].apply(split_count)
emojis = sum(df['emoji'].str.len())
print(emojis)
URLPATTERN = r'(https?://\S+)'
df['urlcount'] = df.Message.apply(lambda x: re.findall(URLPATTERN, x)).str.len()
links = np.sum(df.urlcount)
print("Data science Community")
print("Messages:",total_messages)
print("Media:",media_messages)
print("Emojis:",emojis)
print("Links:",links)
Data Science Community
Messages: 2201
Media: 470
Emojis: 613
Links: 437
بعد، میزان فعالیت کاربرها رو تو چت گروهی واتس اپ بررسی می کنیم:
media_messages_df = df[df['Message'] == '<Media omitted>']
messages_df = df.drop(media_messages_df.index)
messages_df.info()
messages_df['Letter_Count'] = messages_df['Message'].apply(lambda s : len(s))
messages_df['Word_Count'] = messages_df['Message'].apply(lambda s : len(s.split(' ')))
messages_df["MessageCount"]=1
l = ["Aman Kharwal", "Sahil Pansare", "Sumehar"]
for i in range(len(l)):
# Filtering out messages of particular user
req_df= messages_df[messages_df["Author"] == l[i]]
# req_df will contain messages of only one particular user
print(f'Stats of {l[i]} -')
# shape will print number of rows which indirectly means the number of messages
print('Messages Sent', req_df.shape[0])
#Word_Count contains of total words in one message. Sum of all words/ Total Messages will yield words per message
words_per_message = (np.sum(req_df['Word_Count']))/req_df.shape[0]
print('Words per message', words_per_message)
#media conists of media messages
media = media_messages_df[media_messages_df['Author'] == l[i]].shape[0]
print('Media Messages Sent', media)
# emojis conists of total emojis
emojis = sum(req_df['emoji'].str.len())
print('Emojis Sent', emojis)
#links consist of total links
links = sum(req_df["urlcount"])
print('Links Sent', links)
print()
Stats of Aman Kharwal –
Messages Sent 431
Words per message 5.907192575406032
Media Messages Sent 17
Emojis Sent 83
Links Sent 245
Stats of Sahil Pansare –
Messages Sent 306
Words per message 20.81045751633987
Media Messages Sent 12
Emojis Sent 195
Links Sent 52
Stats of Sumehar –
Messages Sent 52
Words per message 4.826923076923077
Media Messages Sent 0
Emojis Sent 8
Links Sent 0
همونطوری که تو خروجی هم میبینین، تعداد پیام های ارسالی، میانگین تعداد کلمه به ازای هر پیام، تعداد فایل های رسانه ای ارسالی، تعداد ایموجی های ارسالی و تعداد لینک های ارسالی مربوط به هر کاربر مشخص شدند.
خب بیایید یه نگاهی بندازیم به ایموجی هایی که بیشتر از بقیه استفاده شدند:
total_emojis_list = list([a for b in messages_df.emoji for a in b])
emoji_dict = dict(Counter(total_emojis_list))
emoji_dict = sorted(emoji_dict.items(), key=lambda x: x[1], reverse=True)
for i in emoji_dict:
print(i)

تجزیه و تحلیل چت گروهی واتس اپ: ابر کلمه (wordcloud)
تو این بخش میخوایم با استفاده از wordcloud کلماتی که تو این چت بیشتر استفاده شدند رو مشخص کنیم. wordcloud یه گراف از کلماته و سبک نمایش اون به این صورته که کلماتی که بیشتر از بقیه استفاده شدند رو بزرگتر نشون میده:
text = " ".join(review for review in messages_df.Message)
print ("There are {} words in all the messages.".format(len(text)))
stopwords = set(STOPWORDS)
# Generate a word cloud image
wordcloud = WordCloud(stopwords=stopwords, background_color="white").generate(text)
# Display the generated image:
# the matplotlib way:
plt.figure( figsize=(10,5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
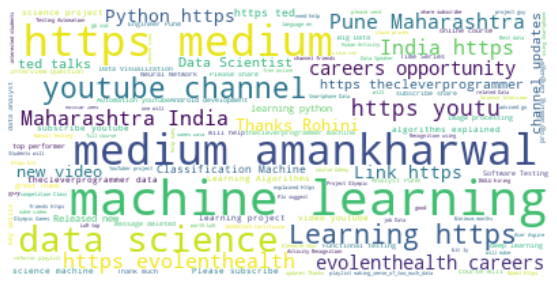
خب، wordcloud بالایی براساس چت کل گروهه. بیایید یه نگاهی بندازیم به وضعیت wordcloud چت های کاربرها:
l = ["Aman Kharwal", "Sahil Pansare", "Sumehar"]
for i in range(len(l)):
dummy_df = messages_df[messages_df['Author'] == l[i]]
text = " ".join(review for review in dummy_df.Message)
stopwords = set(STOPWORDS)
#Generate a word cloud image
print('Author name',l[i])
wordcloud = WordCloud(stopwords=stopwords, background_color="white").generate(text)
#Display the generated image
plt.figure( figsize=(10,5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
Author name Aman Kharwal

Author name Sahil Pansare
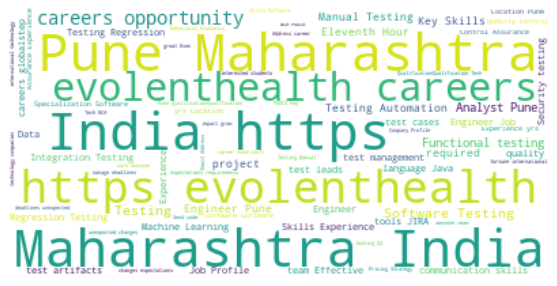
Author name Sumehar
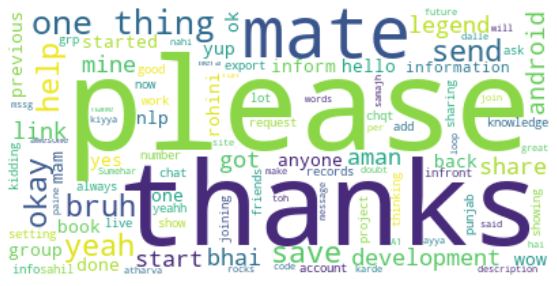
تجزیه و تحلیل ها نشون میده که این گروه یه گروه دوستانه نیست و اعضای این گروه مبتدیان یادگیری ماشین و برنامه نویسی هستن.
امیدواریم که از این پست آموزشی لذت برده باشید و آشنایی با نحوه تجزیه و تحلیل چت گروهی واتس اپ براتون مفید واقع بشه.
برای هرگونه سوال در زمینه آموزش ها فقط کافیه روی لینک واتساپ یا تلگرام (در زیر همین پست) کلیک کنید. یا با شماره تماس بالای صفحه سایت تماس بگیرید.