
تحلیل احساسات در توییتر به فرآیند شناسایی و دستهبندی مجموعهای از توییت ها گفته میشه. هدف اصلی و ویژه از این تحلیل، تعیین نظر نویسنده نسبت به یه موضوع، محصول، اتفاق و … مثبت، منفی یا خنثی هست.
تو این پست آموزشی، تجزیه و تحلیل احساسات در توییتر رو بر اساس NLP و با استفاده از کتابخونه NLTK پایتون انجام میدیم.
تحلیل احساسات در توییتر
حالا بیایید کارمون رو با ایمپورت کتابخونه ها شروع کنیم:
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from sklearn.model_selection import train_test_split # function for splitting data to train and test sets
import nltk
from nltk.corpus import stopwords
from nltk.classify import SklearnClassifier
from wordcloud import WordCloud,STOPWORDS
import matplotlib.pyplot as plt
دانلود دیتاست
برای دانلود دیتاست موردنیاز برای این پروژه، روی این لینک کلیک کنید:
data = pd.read_csv('Sentiment.csv')
# Keeping only the neccessary columns
data = data[['text','sentiment']]
اول، دیتاست رو به دو مجموعه آموزش و تست تقسیم میکنیم. تقسیمبندی به این صورته که مجموعه تست ۱۰ درصد از دیتاست رو شامل میشه.
برای اینکه این تحلیل با نتایج خاص و مفیدی همراه باشه، اون دسته توییتهایی که خنثی هستند و شامل یه نظر مثبت یا منفی نیستن رو از دیتاست حذف میکنیم چون هدف اصلی از این کار تحلیل فرق بین توییت های مثبت و منفیه.
# Splitting the dataset into train and test set
train, test = train_test_split(data,test_size = 0.1)
# Removing neutral sentiments
train = train[train.sentiment != "Neutral"]"
در مرحله بعدی، توییت های مثبت و منفی دیتاست آموزشی رو جدا میکنیم تا بهراحتی بتونیم کلماتی که به هر کدوم از این دو دسته تعلق دارن رو شناسایی کنیم:
اول، هشتگها، منشنها و لینکها رو از متن توییت ها پاک میکنیم. الآن دیگ، دادهها آماده این هستند که با wordcloud، مهمترین و برجستهترین کلمات مربوط به توییت های مثبت و منفی رو نشون بدیم.
train_pos = train[ train['sentiment'] == 'Positive']
train_pos = train_pos['text']
train_neg = train[ train['sentiment'] == 'Negative']
train_neg = train_neg['text']
def wordcloud_draw(data, color = 'black'):
words = ' '.join(data)
cleaned_word = " ".join([word for word in words.split()
if 'http' not in word
and not word.startswith('@')
and not word.startswith('#')
and word != 'RT'
])
wordcloud = WordCloud(stopwords=STOPWORDS,
background_color=color,
width=2500,
height=2000
).generate(cleaned_word)
plt.figure(1,figsize=(13, 13))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
print("Positive words")
wordcloud_draw(train_pos,'white')
print("Negative words")
wordcloud_draw(train_neg)
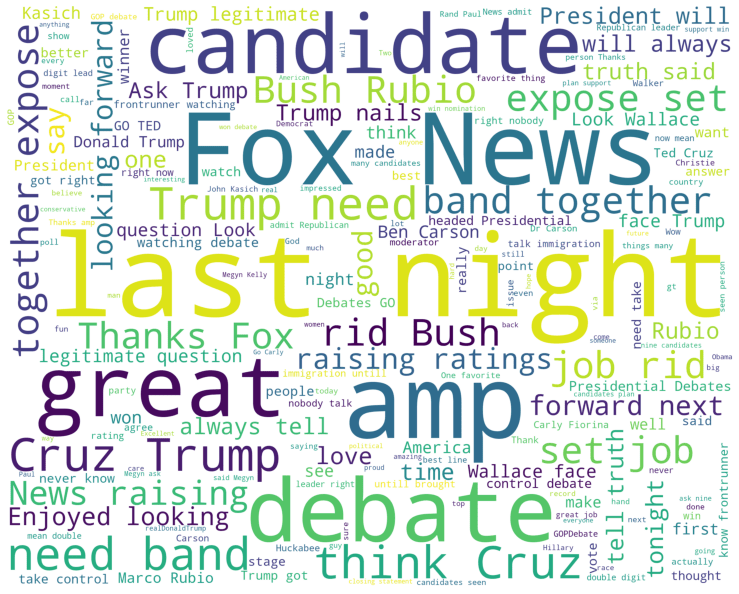
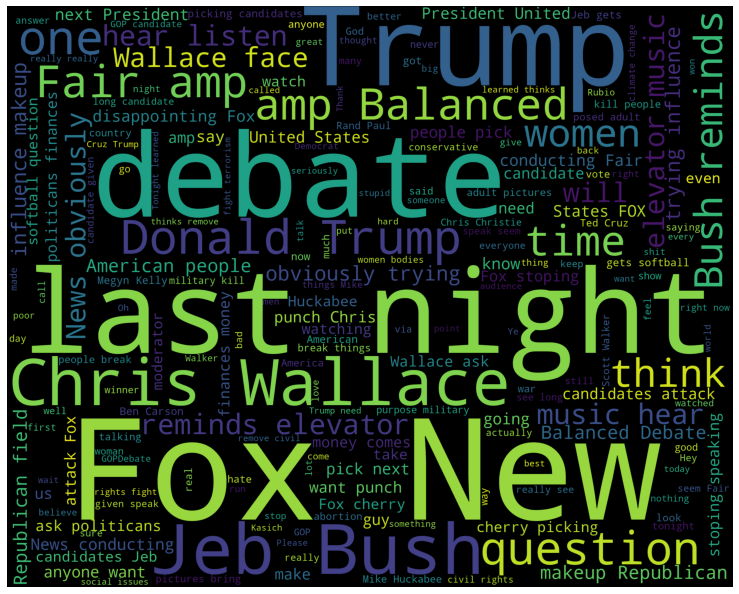
جالبه که به برجسته ترین کلمات مربوط به دیتاست توییت های مثبت توجه کنید:
truth, strong, legitimate, together, love, job
نتیجه اینه که مردم معتقدند که کاندید ایده آل اونها دارای ویژگیهایی مثل راستگویی و کاردرستیه و در کل خوبه.
از طرف دیگه، توییت های منفی شامل کلمات زیر هستن:
influence, news, elevatormusic, disappointing, softball, makeup, cherry picking, trying
و نتیجه این خروجی هم اینه که مردمی تصمیم قاطعی در مورد کاندیدها ندارند، شروع به سرزنش کل کاندیدها میکنن.
بعد مصورسازی، هشتگها، منشنها، لینکها و stopwordها رو از مجموعه آموزشی حذف میکنیم.
stopwordها کلماتی هستند که استفاده از اونها در این جستجو و تجزیه و تحلیل اهمیتی نداره.
معمولاً این نوع کلمات از پرسوجوها حذف میشن چون اطلاعات غیرمفید و بیاهمیت زیادی رو برمیگردونن. (مثل: the،for، this و …)
tweets = []
stopwords_set = set(stopwords.words("english"))
for index, row in train.iterrows():
words_filtered = [e.lower() for e in row.text.split() if len(e) >= 3]
words_cleaned = [word for word in words_filtered
if 'http' not in word
and not word.startswith('@')
and not word.startswith('#')
and word != 'RT']
words_without_stopwords = [word for word in words_cleaned if not word in stopwords_set]
tweets.append((words_without_stopwords, row.sentiment))
test_pos = test[ test['sentiment'] == 'Positive']
test_pos = test_pos['text']
test_neg = test[ test['sentiment'] == 'Negative']
test_neg = test_neg['text']
در مرحله بعد، با nltk lib، ویژگیها رو استخراج میکنیم و این کار رو با اندازهگیری یه فرکانس توزیع و انتخاب کلیدهای حاصل انجام میدیم.
# Extracting word features
def get_words_in_tweets(tweets):
all = []
for (words, sentiment) in tweets:
all.extend(words)
return all
def get_word_features(wordlist):
wordlist = nltk.FreqDist(wordlist)
features = wordlist.keys()
return features
w_features = get_word_features(get_words_in_tweets(tweets))
def extract_features(document):
document_words = set(document)
features = {}
for word in w_features:
features['contains(%s)' % word] = (word in document_words)
return features
بهاینترتیب، بیشترین فرکانس توزیع کلمات رو ترسیم میکنیم. بیشترین کلمات در شبهای مناظره متمرکز شدند.
wordcloud_draw(w_features)
با استفاده از nltk NaiveBayes Classifier، ویژگیهای استخراجشده رو طبقهبندی میکنیم:
# Training the Naive Bayes classifier
training_set = nltk.classify.apply_features(extract_features,tweets)
classifier = nltk.NaiveBayesClassifier.train(training_set)
درنهایت، با معیارهای نهچندان هوشمندانه، نحوه نمره دهی الگوریتم طبقهبندی رو اندازهگیری میکنیم:
neg_cnt = 0
pos_cnt = 0
for obj in test_neg:
res = classifier.classify(extract_features(obj.split()))
if(res == 'Negative'):
neg_cnt = neg_cnt + 1
for obj in test_pos:
res = classifier.classify(extract_features(obj.split()))
if(res == 'Positive'):
pos_cnt = pos_cnt + 1
print('[Negative]: %s/%s ' % (len(test_neg),neg_cnt))
print('[Positive]: %s/%s ' % (len(test_pos),pos_cnt))
امیدواریم که از این پست آموزشی لذت برده باشید و یادگیری نحوه تحلیل احساسات در توییتر براتون مفید واقع بشه.
برای هرگونه سوال در زمینه آموزش ها فقط کافیه روی لینک واتساپ یا تلگرام (در زیر همین پست) کلیک کنید. یا با شماره تماس بالای صفحه سایت تماس بگیرید.