
یادگیری ماشین کاربردهای قابلتوجهی در زمینه پیشبینی قیمت سهام دارد. ما در این پروژه، پیشبینی قیمت سهام با استفاده از یادگیری ماشین رو موردبررسی قرار میدیم. اگه بخوایم دقیقتر در مورد کاری که میخوایم انجام بدیم، صحبت کنیم اینجوریه که مدلسازی رو با استفاده از شبکههای عصبی LSTM انجام میدیم و بعد با استفاده از اون، قیمت سهام یک بازه زمانی مشخصی رو پیشبینی میکنیم. با ادامه مقاله همراه باشید تا پیادهسازی این پروژه پیچیده و مبهم رو با بهرهمندی از توضیحات فنی دقیق یاد بگیرید:
پروژه پیشبینی قیمت سهام با LSTM
دانلود دیتاست
ما برای این پروژه از دیتاست NSE TATA GLOBAL استفاده میکنیم. Tata یک شرکت هندیه که در زمینه تولید و عرضه انواع نوشیدنیها فعالیت میکنه. برای دانلود دیتاست میتونید روی این لینک کنید.
ایمپورت پکیج و کتابخانهها
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib.pylab import rcParams
rcParams['figure.figsize']=20,10
from keras.models import Sequential
from keras.layers import LSTM,Dropout,Dense
from sklearn.preprocessing import MinMaxScaler
خواندن دیتاست
df=pd.read_csv("NSE_Tata.csv")
df.head()
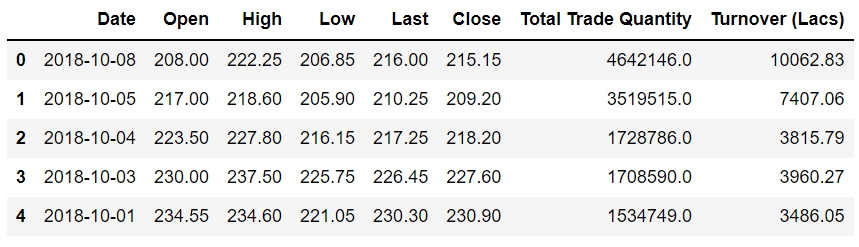
آنالیز نحوه تغییر قیمت سهام
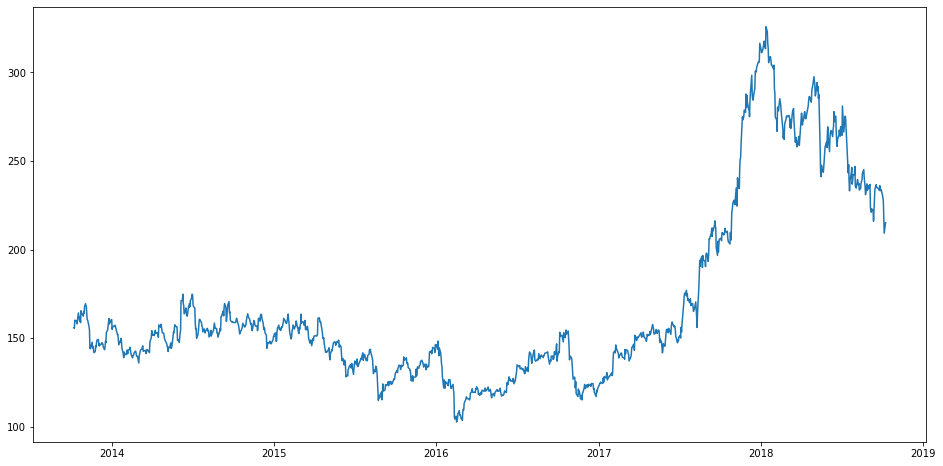
اول فرمت مقادیر ستون Date مربوط به دیتاست رو به “%Y-%m-%d” تغییر میدیم و بعد این ستون رو بهعنوان ایندکس دیتاست تعیین میکنیم. نمودار خروجی نحوه تغییر قیمت close رو طی سالهای متوالی نشون میده. منظور از قیمت close همون قیمتی هست که بهعنوان قیمت روز اون سهام تعیین میشه.
df["Date"]=pd.to_datetime(df.Date,format="%Y-%m-%d")
df.index=df['Date']
plt.figure(figsize=(16,8))
plt.plot(df["Close"],label='Close Price history')
ایجاد دیتا فریم جدید
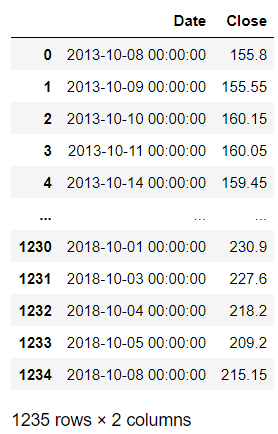
تو این بخش بعدازاینکه دیتا فریم رو بهصورت صعودی مرتب کردیم، یه دیتاست جدید با طول دیتاست قبلی و دو ستون Date و Close ایجاد میکنیم و ستونها رو بر اساس دیتا فریم قبلی مقداردهی میکنیم. شبیه اینه که یه کپی از اون ایجاد میکنیم ولی فیلترهای که انجام میدیم باعث میشه که فقط اطلاعات موردنیازمون رو در اختیار داشته باشیم.
data=df.sort_index(ascending=True,axis=0)
new_dataset=pd.DataFrame(index=range(0,len(df)),columns=['Date','Close'])
for i in range(0,len(data)):
new_dataset["Date"][i]=data['Date'][i]
new_dataset["Close"][i]=data["Close"][i]
new_dataset
چون در مرحله بعدی قرار نرمال سازی انجام بدیم و تابع نرمال سازی روی مقادیر عددی انجام میشه پس ستون Date رو از دیتاست حذف می کنیم:
new_dataset.drop("Date",axis=1,inplace=True)
final_dataset=new_dataset.values

نرمالسازی دیتاست فیلتر شده
حالا با استفاده از MinMaxScaler مقادیر عدد دیتاست رو نرمالسازی میکنیم تا در بازه ۰ تا ۱ قرار بگیرند.
scaler=MinMaxScaler(feature_range=(0,1))
scaled_data=scaler.fit_transform(final_dataset)

تقسیم دیتاست به دیتاست آموزش و تست
تقسیمبندی دیتاست آموزش تست رو طوری انجام میدیم که از کل دیتاست که ۱۲۳۵ رکورد داره، ۹۸۷ تای اول به دیتاست آموزش و بقیه به دیتاست تست اختصاص داده میشن.
train_data=final_dataset[0:987,:]
valid_data=final_dataset[987:,:]
بعد از تقسیم نوبت میرسه به مقداردهی آرایه X و Y لازم برای آموزش مدل:
x_train_data,y_train_data=[],[]
for i in range(60,len(train_data)):
x_train_data.append(scaled_data[i-60:i,0])
y_train_data.append(scaled_data[i,0])
x_train_data,y_train_data=np.array(x_train_data),np.array(y_train_data)
x_train_data=np.reshape(x_train_data,(x_train_data.shape[0],x_train_data.shape[1],1))
مقداردهی آرایه X و Y بهصورت زیر انجام میشه:

np.array و np.reshape هر کدوم از اون رکوردهایی که در هر دور حلقه for به آرایهها اضافه میشن رو ساختاربندی میکنند و آرایه چندبعدی مرتبتری ایجاد میکنند.
ساخت و آموزش مدل
بعد از آمادهسازی دادهها، میرسیم به مرحله اصلی یا همون مرحله ساخت مدل. تو این مدلسازی از شبکه عصبی LSTM استفاده میکنیم. اگر دوست دارید در مورد جزئیات مربوط به آرگومانهای این لایهها بیشتر بدونید، بهتره به این لینک مراجعه کنید و توضیحات قسمت مدلسازی رو بررسی کنید.
lstm_model=Sequential()
lstm_model.add(LSTM(units=50,return_sequences=True,input_shape=(x_train_data.shape[1],1)))
lstm_model.add(LSTM(units=50))
lstm_model.add(Dense(1))
lstm_model.compile(loss='mean_squared_error',optimizer='adam')
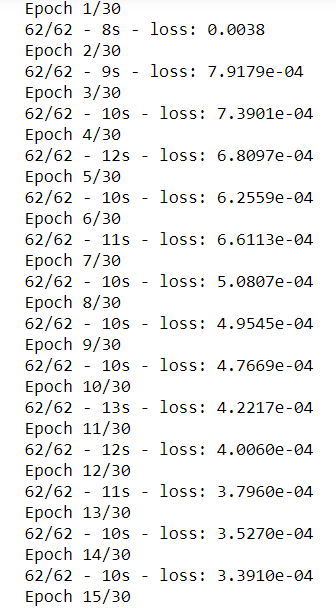
lstm_model.fit(x_train_data,y_train_data,epochs=30,batch_size=15,verbose=2)
آمادهسازی دیتاست تست و پیش بینی
حالا دادههایی که برای تست مدل لازم داریم رو آماده میکنیم.
inputs_data=new_dataset[len(new_dataset)-len(valid_data)-60:].values
inputs_data=inputs_data.reshape(-1,1)
inputs_data=scaler.transform(inputs_data)
X_test=[]
for i in range(60,inputs_data.shape[0]):
X_test.append(inputs_data[i-60:i,0])
X_test=np.array(X_test)
X_test=np.reshape(X_test,(X_test.shape[0],X_test.shape[1],1))
و نوبت میرسه به مرحله پیشبینی. آرایهای که برای مجموعه داده X تست در نظر گرفتیم رو بهعنوان ورودی پیشبینی قرار میدیم. البته چون قبلاً روی دادهها نرمالسازی انجام دادیم. بعد از پیشبینی، مقادیر حاصل رو با استفاده از inverse_transform به بازه عادی خودشون برمی گردونیم تا مقایسه اونها با مقادیر واقعی بهدرستی انجام بشه.
predicted_closing_price=lstm_model.predict(X_test)
predicted_closing_price=scaler.inverse_transform(predicted_closing_price)
توجه: درصورتیکه میخواین مدل رو ذخیره کنید و در هر پیادهسازی و پروژه دیگه ای ازش استفاده کنید، می تونید عمل ذخیرهسازی مدل رو با استفاده از کد زیر انجام بدید:
lstm_model.save("saved_model.h5")
رسم نمودار مقایسه قیمت واقعی و قیمت پیشبینیشده برای سهام
برای ۹۸۷ رکورد اول فقط مقادیر قیمت دیتاست آموزش رو قرار میدیم و اون رو با رنگ آبی نشون میدیم.
بعد یه ستون جدید به اسم Predictions برای valid_data درست میکنیم و مقادیر پیشبینیشده رو در این ستون قرار میدیم. در کل الآن ۲۴۸ تا رکورد داریم که هم قیمت واقعی (خط سبز) و هم قیمت پیشبینیشده براشون (خطر نارنجی) رو در اختیار داریم و مقایسه اونها میتونه جالب باشه برامون.
train_data=new_dataset[:987]
valid_data=new_dataset[987:]
valid_data['Predictions']=predicted_closing_price
plt.plot(train_data["Close"],color='blue')
plt.plot(valid_data['Close'], color='green')
plt.plot(valid_data['Predictions'],color='orange')
plt.show()
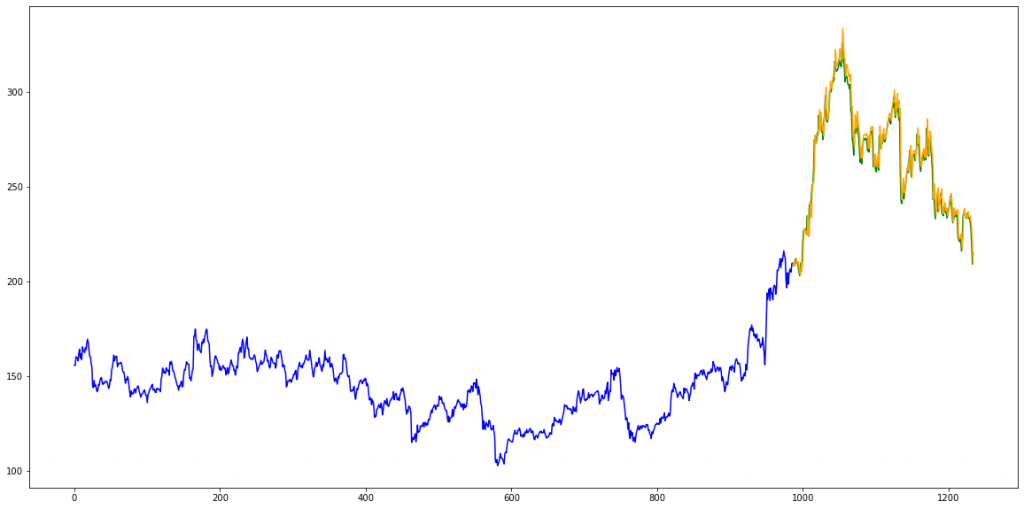
نتیجه نشون میده که قیمتهایی که با LSTM پیشبینی شدند به قیمتهای واقعی خیلی نزدیکن و این یه نتیجه موفقیتآمیز محسوب میشه.
پروژه پیشبینی قیمت سهام با LSTM که در این مقاله ارائهشده مخصوص مبتدیان هست و مطمئناً بعد اینکه خودتون هم این پیادهسازی رو انجام بدید بهتر متوجه روش پیادهسازی این پروژه میشید. امیدواریم که از این مقاله لذت برده باشید و یادگیری نحوه پیادهسازی پروژه پیشبینی قیمت سهام براتون مفید واقع بشه.
برای هرگونه سوال در زمینه آموزش ها فقط کافیه روی لینک واتساپ یا تلگرام (در زیر همین پست) کلیک کنید. یا با شماره تماس بالای صفحه سایت تماس بگیرید.
سلام
در تقسیم دیتاست به دیتاست آموزش و تست از final_dataset استفاده کردید. آیا نباید از scaled_data استفاده می کردید؟
سلام وقت بخیر دوست عزیز.
بله هردو مورد هم استفاده میشه و scaled_data کاربردش بیشتره