
تو این مقاله، نحوه تشخیص پیام اسپم یا هرزنامه با استفاده از یادگیری ماشین رو به شما عزیزان آموزش میدیم. تو این پروژه، از Naive Bayes چندجملهای استفاده میکنیم.
اینclassifier برای طبقهبندی ویژگیهای گسسته مناسبه. اگر بخوایم یه مثالی در زمینه ویژگیهای گسسته داشته باشیم، در مورد همین کاری که در ادامه مقاله قراره انجام بدیم، تعداد کلمات برای طبقهبندی متن یه ویژگی گسسته محسوب میشه. classifier موردنظر ما تعداد کلمات صحیح رو بهعنوان ورودی در نظر میگیره.
از طرف دیگه، Gaussian Naive Bayes بیشتر برای دادههای پیوسته مناسبه چون فرض میکنه که دادههای ورودی دارای توزیع نرمال (گاوسی) هستند.
تشخیص پیام اسپم
حالا بیایید کارمون رو با ایمپورت کتابخونه ها شروع کنیم:
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import nltk
دانلود و خواندن دیتاست
دیتاست رو از اینجا دانلود کنید
import pandas
df_sms = pd.read_csv('spam.csv',encoding='latin-1')
df_sms.head()
حذف ستون های غیرضروری و تغییر نام ستون های مهم
df_sms = df_sms.drop(["Unnamed: 2", "Unnamed: 3", "Unnamed: 4"], axis=1)
df_sms = df_sms.rename(columns={"v1":"label", "v2":"sms"})
df_sms.head()
بررسی حداکثر طول پیام
print(len(df_sms))
تعداد رکوردهای spam (اسپم) و ham (غیر اسپم)
df_sms.label.value_counts()
ham 4825
spam 747
Name: label, dtype: int64
توصیف دیتاست
df_sms.describe()

بررسی طول هر کدوم از پیامها
df_sms['length'] = df_sms['sms'].apply(len)
df_sms.head()

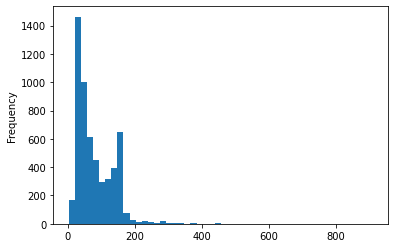
فرکانس طول پیامها
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
df_sms['length'].plot(bins=50, kind='hist')
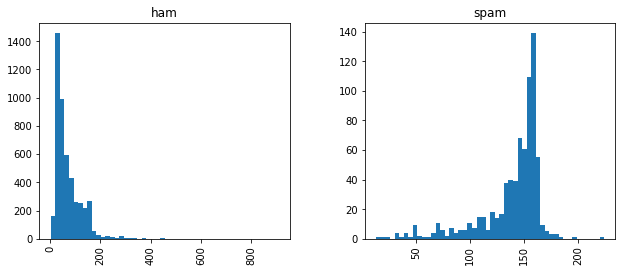
هیستوگرام مربوط به پیامهای اسپم و غیر اسپم
df_sms.hist(column='length', by='label', bins=50,figsize=(10,4))
تغییر مقادیر ستون label بهصورت باینری (ham=0، spam=1)
df_sms.loc[:,'label'] = df_sms.label.map({'ham':0, 'spam':1})
print(df_sms.shape)
df_sms.head()

راهکار کوله کلمات (Bag of Words)
در این دیتاست، مجموعه بزرگی از دادههای متنی داریم و با توجه به این که بیشتر الگوریتمهای یادگیری ماشین متکی به دادههای عددی هستند و اعداد رو بهعنوان ورودی دریافت میکنند، پیامها (ایمیل و پیامک) معمولاً متنهای سنگینی دارند. به همین خاطر، ما به یه روشی نیاز داریم که دادههای متنی رو برای الگوریتم یادگیری ماشین، بازنمایی کنیم و مدل BoW به ما کمک میکنه که این کار رو بهراحتی انجام بدیم.
تو این راهکار، برای هر پیام از کلمات توکن شده استفاده میکنیم و فرکانس توزیع هر توکن رو پیدا میکنیم.
با استفاده از این تکنیک، میتونیم مجموعهای از داکیومنت ها رو به ماتریس تبدیل کنیم. هر داکیومنت میشه یه سطر از ماتریس و هر کلمه (توکن) میشه یه ستون از ماتریس و مقادیر مربوط به هر سطر و ستون، فرکانس وقوع هر کلمه یا توکن رو در داکیومنت موردنظر نشون میدن.
بهعنوان مثال:
بیایید فرض کنیم که ۴ داکیومنت زیر رو داریم:
[‘Hello, how are you!’, ‘Win money, win from home.’, ‘Call me now’, ‘Hello, Call you tomorrow?’]
هدف ما اینه که این متنها رو به ماتریس توزیع فرکانس تبدیل کنیم که بهاینترتیب ماتریس زیر رو بهعنوان نتیجه این تبدیل داریم:
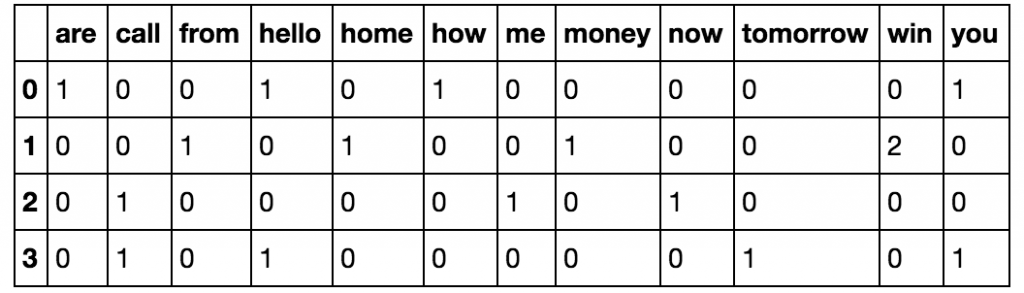
همونطورکه میبینیم، ایندکس داکیومنت ها در سطرها و کلمات هم در ستونها قرار گرفتند و مقادیر مرتبط با هر سطر و ستون، فرکانس کلمه در داکیومنت رو مشخص میکنه. بهعنوان مثال، کلمه are در داکیومنت با ایندکس ۰ یا همون متن اول در مجموعه، یه بار اومده که مقدار مربوط به خانه (۰, are) برابر با یک میشه و بقیه خانهها هم به همین صورت تکمیل شدند.
اجازه بدید که ببینیم چطوری میتونیم این تبدیل رو با مجموعه کوچکی از داکیومنت ها انجام بدیم.
برای این کار، از روش sklearns count vectorizer استفاده میکنیم که اقدامات زیر رو انجام میده:
- رشته رو توکن گذاری میکنه (رشته رو به کلمات مجزا تقسیم میکنه) و به هر توکن یه شناسه منحصربفرد اختصاص میده.
- میزان وقوع هر کدوم از توکن ها رو محاسبه میکنه.
پیادهسازی راهکار Bag of Words
مرحله ۱. تبدیل هر کدوم از رشتهها به رشته معادل با حروف کوچک
documents = ['Hello, how are you!',
'Win money, win from home.',
'Call me now.',
'Hello, Call hello you tomorrow?']
lower_case_documents = []
lower_case_documents = [d.lower() for d in documents]
print(lower_case_documents)
[‘hello, how are you!’, ‘win money, win from home.’, ‘call me now.’, ‘hello, call hello you tomorrow?’]
مرحله ۲. حذف همه علائم نگارشی
sans_punctuation_documents = []
import string
for i in lower_case_documents:
sans_punctuation_documents.append(i.translate(str.maketrans("","", string.punctuation)))
sans_punctuation_documents
[‘hello how are you’,
‘win money win from home’,
‘call me now’,
‘hello call hello you tomorrow’]
مرحله ۳. توکن سازی
preprocessed_documents = [[w for w in d.split()] for d in sans_punctuation_documents]
preprocessed_documents
[[‘hello’, ‘how’, ‘are’, ‘you’],
[‘win’, ‘money’, ‘win’, ‘from’, ‘home’],
[‘call’, ‘me’, ‘now’],
[‘hello’, ‘call’, ‘hello’, ‘you’, ‘tomorrow’]]
مرحله ۴. محاسبه فرکانسها
frequency_list = []
import pprint
from collections import Counter
frequency_list = [Counter(d) for d in preprocessed_documents]
pprint.pprint(frequency_list)
[Counter({‘hello’: 1, ‘how’: 1, ‘are’: 1, ‘you’: 1}),
Counter({‘win’: 2, ‘money’: 1, ‘from’: 1, ‘home’: 1}),
Counter({‘call’: 1, ‘me’: 1, ‘now’: 1}),
Counter({‘hello’: 2, ‘call’: 1, ‘you’: 1, ‘tomorrow’: 1})]
پیادهسازی Bag of Words در scikit-learn
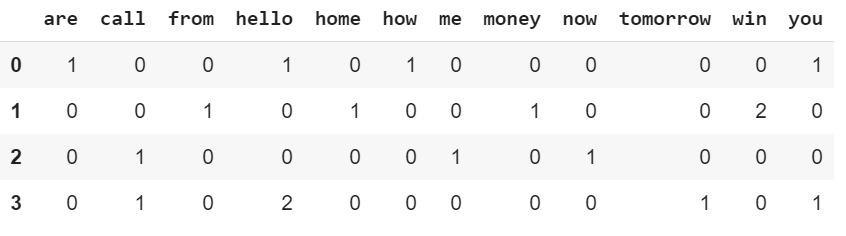
تو این بخش میخوایم برای مجموعه داکیومنت کوچکتر، یه ماتریس فرکانس ایجاد کنیم تا مطمئن بشیم که نحوه ایجاد یه ماتریس بر اساس داکیومنت رو بهطور کامل متوجه شدیم. مجموعه داکیومنت ما بهصورت زیر هست:
documents = [‘Hello, how are you!’, ‘Win money, win from home.’, ‘Call me now.’, ‘Hello, Call hello you tomorrow?’]
from sklearn.feature_extraction.text import CountVectorizer
count_vector = CountVectorizer()
پیشپردازش دادهها با CountVectorizer
پیادهسازی یه نسخه از متد CountVectorizer نیاز به پاکسازی دادهها داره. این پاکسازی، تبدیل همه حروف متنها به حروف کوچیک و حذف علائم نگارشی رو شامل میشه.
CountVectorizer پارامترهای خاصی داره که این کار رو برای ما انجام میده. در ادامه به بررسی این پارامترها میپردازیم:
lowercase = True
پارامتر lowercase بهصورت پیشفرض true هست که تمام حروف متنها رو به حروف کوچیک تبدیل میکنه.
token_pattern = (?u)\b\w\w+\b
پارامتر token_pattern دارای مقدار پیشفرض بالا هست که توسط آن همه علائم نگارشی رو نادیده میگیره. این پارامتر با این مقدار علائم نگارشی رو بهعنوان محدودکننده در نظر میگیره و رشتههایی با طول بزرگتر مساوی ۲ رو بهعنوان توکن جداگانه میپذیره.
stop_words
پارامتر stop_words، همه کلمات انگلیسی که در لیست مربوط به stopword های scikit-learn قرار دارند رو از داکیومنت حذف میکنه. کلماتی مثل و، این و … که حضور اونها در داخل متن تأثیری در محتوا و نتیجه نداره، جزو stopword هستند.
با توجه به اندازه دیتاست ما و این نکته که پیامهای ما طول کمتری دارند (برخلاف ایمیل)، نیازی به مقداردهی این پارامتر نداریم.
count_vector.fit(documents)
count_vector.get_feature_names()
[‘are’,
‘call’,
‘from’,
‘hello’,
‘home’,
‘how’,
‘me’,
‘money’,
‘now’,
‘tomorrow’,
‘win’,
‘you’]
doc_array = count_vector.transform(documents).toarray()
doc_array
array([[1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1],
[۰, ۰, ۱, ۰, ۱, ۰, ۰, ۱, ۰, ۰, ۲, ۰],
[۰, ۱, ۰, ۰, ۰, ۰, ۱, ۰, ۱, ۰, ۰, ۰],
[۰, ۱, ۰, ۲, ۰, ۰, ۰, ۰, ۰, ۱, ۰, ۱]])
frequency_matrix = pd.DataFrame(doc_array, columns = count_vector.get_feature_names())
frequency_matrix
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df_sms['sms'],
df_sms['label'],test_size=0.20,
random_state=1)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df_sms['sms'],
df_sms['label'],test_size=0.20,
random_state=1)
پیادهسازی الگوریتم یادگیری ماشین Naive Bayes
تو این بخش برای انجام پیشبینی روی دیتاست برای تشخیص پیام اسپم از متد sklearn.naive_bayes استفاده میکنیم.
اگر بخوایم دقیقتر بگیم، ما برای این پیادهسازی از Naive Bayes چندجملهای استفاده میکنیم. این classifier خاص برای طبقهبندی ویژگیهای گسسته مناسبه و تو این تسک، تعداد کلمات صحیح رو بهعنوان ورودی در نظر میگیره.
از طرف دیگه، Naive Bayes گاوسی بیشتر مناسب دادههای پیوسته هست چون دادههای ورودی دارای توزیع نرمال (گاوسی) هستند.
from sklearn.naive_bayes import MultinomialNB
naive_bayes = MultinomialNB()
naive_bayes.fit(training_data,y_train)
ارزیابی مدل تشخیص پیام اسپم
حالا که پیشبینیهای خودمون روی مجموعه داده تست انجام دادیم، هدف بعدیمون ارزیابی عملکرد مدل هست. مکانیسم های متنوعی برای انجام این کار وجود داره و بهتره اول هر کدوم از اونها بهطور سریع بررسی کنیم:
Accuracy (دقت )، میزان پیشبینیهای صحیح مدل رو نشون میده. Accuracy از نسبت تعداد پیشبینیهای صحیح به تعداد کل پیشبینیها ( تعداد دادههای آموزشی) به دست میاد.
precision (صحت و درستی) به ما میگه که چند درصد از اون پیامهایی که مدل بهعنوان پیام اسپم طبقهبندی کرده، واقعاً پیام اسپم هستند. درواقع، precision از تقسیم تعداد پیشبینیهای مثبت واقعی ( اونایی که واقعاً اسپم هستند و مدل هم بهدرستی اونها رو اسپم تشخیص داده) بر تعداد کل پیشبینیهای مثبت ( همه پیشبینیهای اسپم، چه اسپم باشند چه نه) به دست میاد.
Precision = [True Positives/(True Positives + False Positives)]
recall (پوشش) به ما میگه که چه تعداد از اون پیامهایی که واقعاً اسپم بودند، بهعنوان اسپم طبقهبندی شدند.
مقدار مربوط به این معیار برابر هست با نسبت تعداد پیشبینیهای مثبت واقعی ( کلماتی که بهعنوان اسپم طبقهبندی شدند و در واقعیت هم اسپم هستند) به تعداد کلماتی که در واقعیت اسپم هستند.
Recall = [True Positives/(True Positives + False Negatives)]
ما میتونیم ۹۰ پیام رو بهعنوان غیر اسپم طبقهبندی کنیم ( شامل ۲ موردی که اسپم بودند، ولی ما اونها رو بهعنوان غیر اسپم طبقهبندی کردیم و این میشه – false negative) و ۱۰ پیام رو بهعنوان اسپم ( همه این ۱۰ پیام غیر اسپم بودند و ما به اشتباه اونها رو بهعنوان اسپم طبقهبندی کردیم – false positives) و با وجود این طبقهبندیها نادرست باز هم از دقت معقولی برخورداریم.
برای چنین مواردی، اندازهگیری Precision و recall بسیار مفیده. این دو معیار میتونن با هم ترکیب بشن و از این طریق، نمره F1 به دست بیاد. این F1 میانگین وزنی نمرههای Precision و recall هست. نمره F1 در بازه بین ۰ تا ۱ قرار داره و ۱ بهترین نمره F1 ممکن است.
ما برای اطمینان از عملکرد درست مدلمون از هر ۴ معیار استفاده کردیم. مقادیر هر یک از این ۴ معیار در بازه ۰ تا ۱ قرار دارد، هر چقد نمره مربوط به این معیارها به ۱ نزدیک باشه، نشون میده که مدل ما عملکرد خوبی داره.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
print('Accuracy score: {}'.format(accuracy_score(y_test, predictions)))
print('Precision score: {}'.format(precision_score(y_test, predictions)))
print('Recall score: {}'.format(recall_score(y_test, predictions)))
print('F1 score: {}'.format(f1_score(y_test, predictions)))
Accuracy score: 0.9847533632286996
Precision score: 0.9420289855072463
Recall score: 0.935251798561151
F1 score: 0.9386281588447652
نتایج مربوط به هر کدوم از این معیارها نشون میده که مدل ما عملکرد در تشخیص پیام اسپم، عملکرد خوبی از خودش نشون میده.
امیدوارم که از این پست آموزشی لذت برده باشید و یادگیری نحوه پیاده سازی مدل تشخیص پیام اسپم براتون مفید واقع بشه.
برای هرگونه سوال در زمینه آموزش ها فقط کافیه روی لینک واتساپ یا تلگرام (در زیر همین پست) کلیک کنید. یا با شماره تماس بالای صفحه سایت تماس بگیرید.