
پروژه یادگیری ماشین برای غربالگری رزومه با پایتون
کمپانیها و شرکتها معمولاً برای هر آگهی استخدام، هزاران رزومه مختلف دریافت می کنن و بعد از بررسی و غربالگری رزومهها توسط مسئولان مربوطه، بهترین اشخاص واجد شرایط استخدام میشن. در این مقاله، یک پروژه یادگیری ماشین معرفی میشه که هدف اصلی از پیادهسازی اون، غربالگری رزومه با زبان برنامهنویسی پایتون هست.
غربالگری رزومه چیست؟
استخدام افراد مستعد مناسب برای همه مشاغل یک چالش محسوب میشه. دلایل زیر میتونن باعث بزرگتر شدن این چالش بشن و دلیل اصلی آن حجم بالای متقاضیان هست:
- نیاز به استخدام افراد زیاد
- در حال رشد بودن جایگاه شغلی موردنظر در بازار
- بالا بودن نرخ ترک یا استعفا از شغل موردنظر
در سازمانهای خدماتی معمولی، متخصصانی استخدام میشن که از لحاظ مهارتهای فنی و تجربه در زمینه کسبوکار موردنظر تمام شرایط لازم را داشته باشن. این افراد برای حل مشکلات مشتریان به پروژههای مختلف اختصاص داده میشن. انتخاب بهترین استعداد از بین متقاضیان بهعنوان غربالگری رزومه شناخته میشه.
معمولاً شرکتهای بزرگ زمان کافی برای بررسی تک تک رزومهها رو ندارن، بنابراین از الگوریتمهای یادگیری ماشین برای غربالگری رزومه استفاده میکنن.
پروژه یادگیری ماشین برای غربالگری رزومه با پایتون
در این بخش، وارد مرحله پیادهسازی این پروژه جالب میشیم. این کار با ایمپورت کردن کتابخانههای لازم و دیتاست شروع میشه:
(برای دانلود دیتاست، روی این لینک کلیک کنید.)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
from sklearn.naive_bayes import MultinomialNB
from sklearn.multiclass import OneVsRestClassifier
from sklearn import metrics
from sklearn.metrics import accuracy_score
from pandas.plotting import scatter_matrix
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
resumeDataSet = pd.read_csv('UpdatedResumeDataSet.csv' ,encoding='utf-8')
resumeDataSet['cleaned_resume'] = ''
resumeDataSet.head()
حالا بیایید یه نگاهی بندازیم به دستهبندیهای رزومه موجود در این دیتاست:
print ("Displaying the distinct categories of resume -")
print (resumeDataSet['Category'].unique())

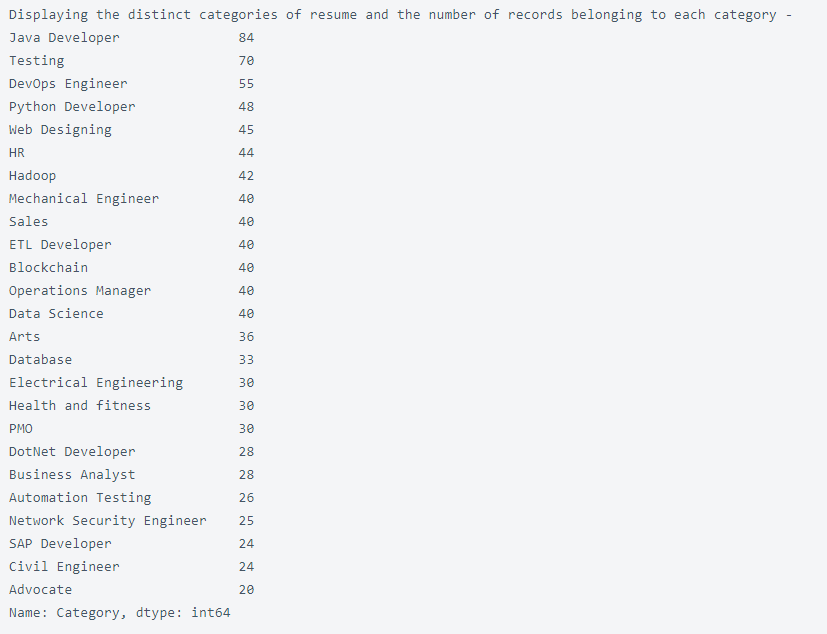
خب در این بخش هم یه نگاهی میندازیم به دستهبندی ها و تعداد رکوردهایی که به هر کدوم از اونها تعلق دارن:
print ("Displaying the distinct categories of resume and the number of records belonging to each category -")
print (resumeDataSet['Category'].value_counts())
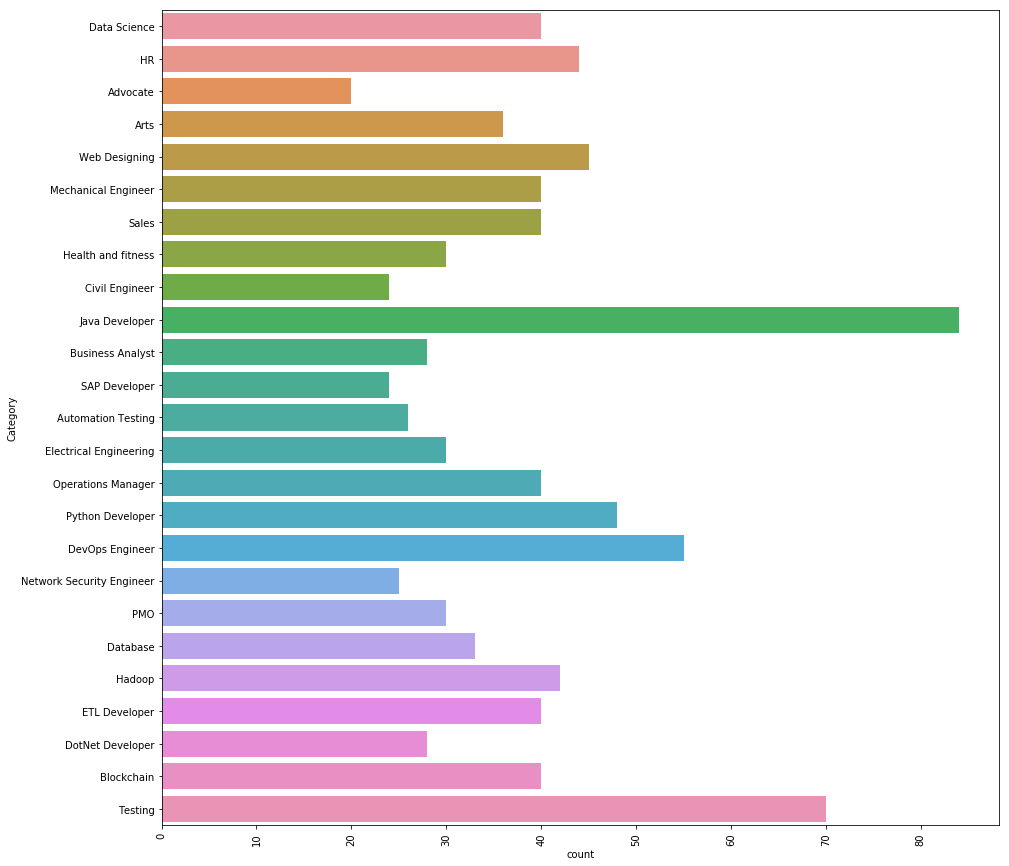
رسم نمودار برای تعداد رکورد مربوط به هر کدوم از دستهبندی ها میتونه درک میزان تقاضا برای هر کدوم از دسته ها رو راحت تر کنه:
import seaborn as sns
plt.figure(figsize=(15,15))
plt.xticks(rotation=90)
sns.countplot(y="Category", data=resumeDataSet)
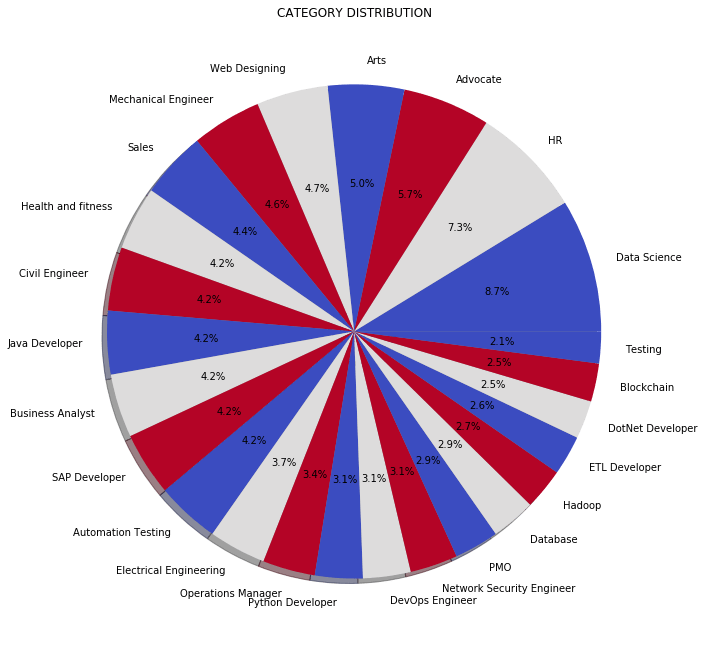
حالا بیاید توزیع دستهبندی ها رو به صورت مصور نشون بدیم:
from matplotlib.gridspec import GridSpec
targetCounts = resumeDataSet['Category'].value_counts()
targetLabels = resumeDataSet['Category'].unique()
# Make square figures and axes
plt.figure(1, figsize=(25,25))
the_grid = GridSpec(2, 2)
cmap = plt.get_cmap('coolwarm')
colors = [cmap(i) for i in np.linspace(0, 1, 3)]
plt.subplot(the_grid[0, 1], aspect=1, title='CATEGORY DISTRIBUTION')
source_pie = plt.pie(targetCounts, labels=targetLabels, autopct='%1.1f%%', shadow=True, colors=colors)
plt.show()
در این بخش یه تابع کمکی ایجاد میشه که URL ها، تگ ها، هشتگ ها، حروف خاص و علائم نگارشی رو حذف کنه:
import re
def cleanResume(resumeText):
resumeText = re.sub('http\S+\s*', ' ', resumeText) # remove URLs
resumeText = re.sub('RT|cc', ' ', resumeText) # remove RT and cc
resumeText = re.sub('#\S+', '', resumeText) # remove hashtags
resumeText = re.sub('@\S+', ' ', resumeText) # remove mentions
resumeText = re.sub('[%s]' % re.escape("""!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~"""), ' ', resumeText) # remove punctuations
resumeText = re.sub(r'[^\x00-\x7f]',r' ', resumeText)
resumeText = re.sub('\s+', ' ', resumeText) # remove extra whitespace
return resumeText
resumeDataSet['cleaned_resume'] = resumeDataSet.Resume.apply(lambda x: cleanResume(x))
بعد از اجرای این تابع، دیتاست حالت تمیزتر و مرتبتری پیدا میکنه. کار بعدی اینه که ابر کلمات یا Wordcloud را نمایش بدیم. یک Wordcloud کلماتی که بیشتر از بقیه در یه ستون خاص از دیتاست تکرار شدن را نشون میده البته همه کلمات رو نشون میده ولی سایز کلمات پرتکرار بزرگتر از بقیه هست.
import nltk
from nltk.corpus import stopwords
import string
from wordcloud import WordCloud
oneSetOfStopWords = set(stopwords.words('english')+['``',"''"])
totalWords =[]
Sentences = resumeDataSet['Resume'].values
cleanedSentences = ""
for i in range(0,160):
cleanedText = cleanResume(Sentences[i])
cleanedSentences += cleanedText
requiredWords = nltk.word_tokenize(cleanedText)
for word in requiredWords:
if word not in oneSetOfStopWords and word not in string.punctuation:
totalWords.append(word)
wordfreqdist = nltk.FreqDist(totalWords)
mostcommon = wordfreqdist.most_common(50)
print(mostcommon)
wc = WordCloud().generate(cleanedSentences)
plt.figure(figsize=(15,15))
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()

حالا این کلمات رو به مقادیر دستهای تبدیل میکنیم:
from sklearn.preprocessing import LabelEncoder
var_mod = ['Category']
le = LabelEncoder()
for i in var_mod:
resumeDataSet[i] = le.fit_transform(resumeDataSet[i])
آموزش مدل یادگیری ماشین برای غربالگری رزومه
قدم بعدی در این پروژه، آموزش یک مدل برای غربالگری رزومه هست. اینجا از مدل طبقهبندی کننده KNeighborsClassifier استفاده میکنیم. اول باید دیتاست رو به دیتاست آموزش و تست تقسیم کنیم:
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from scipy.sparse import hstack
requiredText = resumeDataSet['cleaned_resume'].values
requiredTarget = resumeDataSet['Category'].values
word_vectorizer = TfidfVectorizer(
sublinear_tf=True,
stop_words='english',
max_features=1500)
word_vectorizer.fit(requiredText)
WordFeatures = word_vectorizer.transform(requiredText)
print ("Feature completed .....")
X_train,X_test,y_train,y_test = train_test_split(WordFeatures,requiredTarget,random_state=0, test_size=0.2)
print(X_train.shape)
print(X_test.shape)
در کد بالا از TfidfVectorizer برای مرتبسازی و وزن دهی به کلمات استفاده شده. این وزن دهی بر اساس تعداد تکرار هر یک از کلمات انجام میشه.
تفکیک دیتاست با استفاده از train_test_split انجام میشه. با توجه به کد بالا، ۲۰ درصد از دیتاست بهعنوان داده تست و ۸۰ درصد بقیه بهعنوان داده آموزشی استفاده میشن.
حالا نوبت میرسه به آموزش مدل و چاپ گزارش طبقهبندی.
clf = OneVsRestClassifier(KNeighborsClassifier())
clf.fit(X_train, y_train)
prediction = clf.predict(X_test)
print('Accuracy of KNeighbors Classifier on training set: {:.2f}'.format(clf.score(X_train, y_train)))
print('Accuracy of KNeighbors Classifier on test set: {:.2f}'.format(clf.score(X_test, y_test)))
print("\n Classification report for classifier %s:\n%s\n" % (clf, metrics.classification_report(y_test, prediction)))
Accuracy of KNeighbors Classifier on test set: 0.99
Classification report for classifier OneVsRestClassifier(estimator=KNeighborsClassifier(algorithm=’auto’, leaf_size=30, metric=’minkowski’,
,metric_params=None, n_jobs=None, n_neighbors=5, p=2
,(‘weights=’uniform
:(n_jobs=None
precision recall f1-score support
0 1.00 1.00 1.00 3
1 1.00 1.00 1.00 3
2 1.00 0.80 0.89 5
3 1.00 1.00 1.00 9
4 1.00 1.00 1.00 6
5 0.83 1.00 0.91 5
6 1.00 1.00 1.00 9
7 1.00 1.00 1.00 7
8 1.00 0.91 0.95 11
9 1.00 1.00 1.00 9
10 1.00 1.00 1.00 8
11 0.90 1.00 0.95 9
12 1.00 1.00 1.00 5
13 1.00 1.00 1.00 9
14 1.00 1.00 1.00 7
15 1.00 1.00 1.00 19
16 1.00 1.00 1.00 3
17 1.00 1.00 1.00 4
18 1.00 1.00 1.00 5
19 1.00 1.00 1.00 6
20 1.00 1.00 1.00 11
21 1.00 1.00 1.00 4
22 1.00 1.00 1.00 13
23 1.00 1.00 1.00 15
24 1.00 1.00 1.00 8
micro avg 0.99 0.99 0.99 193
macro avg 0.99 0.99 0.99 193
weighted avg 0.99 0.99 0.99 193
بعد از فیت داده های تست و آموزش، آموزش مدل انجام میشه. بعد از اون پیشبینی داده های تست با استفاده از predict انجام میشه.
دقت مدل با تقسیم تعداد پیشبینی های درست بر تعداد کل پیشبینی ها محاسبه میشه. این دقت یکی از معیارهای ارزیابی عملکرد مدل هست. با توجه به خروجی، میبینیم که دقت مدل ۰.۹۹ شده و این میزان دقت نشاندهنده کارایی بالای مدل هست.
خب در این بخش با نحوه آموزش یک مدل برای غربالگری رزومه آشنا شدید. امیدواریم که از این پست آموزشی لذت برده باشید و یادگیری غربالگری رزومه با زبان پایتون برای شما مفید واقع بشه.
برای هرگونه سوال در زمینه آموزش ها فقط کافیه روی لینک واتساپ یا تلگرام (در زیر همین پست) کلیک کنید. یا با شماره تماس بالای صفحه سایت تماس بگیرید.