
پردازش زبان طبیعی یا همون NLP یک فیلد محبوبی از هوش مصنوعیه که این امکان رو برای سیستمها فراهم میکنه که زبان انسان رو درک و پردازش کنند. در این پست، از NLP برای تحلیل چتهای واتس آپ استفاده میشه.
دریافت دادههای واتس آپ برای NLP
اگر تا حالا چتهای واتس آپ خودتون رو اکسپورت نکردین، اصلاً نگران نباشین چون این کار خیلی آسونه. برای پیاده سازی این پروژه، اول باید چتهای واتس آپ خودتون رو از گوشی هوشمند استخراج کنید. برای این کار کافیه که چت موردنظر خودتون رو از واتس آپ باز کنید و بعد از اون، گزینه export chat رو انتخاب کنید.
فایل متنی که دریافت می کنید، به شرح زیر هست:

در این پیاده سازی از دو راهکار برای پردازش زبان طبیعی چتهای واتس آپ استفاده شده.
۱. تمرکز روی مبانی NLP
۲. استفاده از datetime stamp در ابتدای هر گفتگو
قالببندی چتهای واتس آپ برای NLP
برای تجزیه و تحلیل گفتگوهای واتس آپ، اول باید دادههای مربوط به چتها قالببندی بشن که خود این قالببندی دارای چند مرحله اساسی هست. دسترسی به یک قالب مناسب از دادهها با ایجاد یک دیکشنری امکان پذیره و این دیکشنری از دو کلید اصلی ساخته شده به این صورت که یکی مربوط به آی دی شخصه و کلید دیگه یک لیست از گفتگوهای توکن شده مربوط به شخص موردنظر هست.
ppl=defaultdict(list)
for line in content:
try:
person = line.split(':')[2][7:]
text = nltk.sent_tokenize(':'.join(line.split(':')[3:]))
ppl[person].extend(text) # If key exists (person), extend list with value (text),
# if not create a new key, with value added to list
except:
print(line) # in case reading a line fails, examine why
pass
خروجی:
ppl = {'Person_1' : ['This is message 1', 'Another message',
'Hi Person_2', ... , 'My last tokenised message in the chat'] ,
'Person_2':['Hello Person_1!', 'How's it going?', 'Another messsage',
...]}
در کد بالا از nltk استفاده شده. به این صورت که هر خط از فایل اکسپورت شده با استفاده حلقه for بررسی میشه و قسمت قبل از “:” بهعنوان آی دی شخص و قسمت بعد از “:” بهعنوان متن چت مربوط به آن شخص به لیست گفتگوهای توکن شده شخص اضافه میشه.
توجه داشته باشید که:
- اگر آی دی شخص برای اولین بار شناسایی بشه، برای اضافه کردن متن گفتگوهای آن شخص یک لیست جدید ایجاد میشه.
- در غیر این صورت، اگر آی دی شخص قبلاً شناسایی شده، متن گفتگوی جدید به لیست موجود برای آن شخص اضافه میشه.
طبقهبندی گفتگوها
طبقهبندی گفتگوهای توکن شده به کمک آموزش مدل طبقهبندی Naive Bayes یا مجموعه داده آموزشی که در آن برخی از استایل های چت مربوط به گفتگوها دستهبندی شده، انجامپذیر هست.
posts = nltk.corpus.nps_chat.xml_posts()
def extract_features(post):
features = {}
for word in nltk.word_tokenize(post):
features['contains({})'.format(word.lower())] = True
return features
fposts = [(extract_features(p.text), p.get('class')) for p in posts]
test_size = int(len(fposts) * 0.1)
train_set, test_set = fposts[test_size:], fposts[:test_size]
classifier = nltk.NaiveBayesClassifier.train(train_set)
تابع extract_features برای استخراج متن و حذف علائم نگارشی تعریف شده. به این صورت که word_tokenize کلمات مربوط به پارامتر ورودی رو دریافت میکنه و علائم نگارشی غیر مهم بهجز نقطه رو حذف میکنه. بعد از پایان کار که همه قسمتهای متنی پست شناسایی و با word.lower به حروف کوچک تبدیل شد، تابع features، extract_features رو بهعنوان خروجی برمی گردونه.
در بخش دوم نیز همین تابع به ازای همه پستهای موجود در دادههای چت استخراج شده اجرا میشه و کلاس مربوط به متنها شناسایی شده و در داخل تاپل fposts قرار میگیره:
[… ,(features of text 1, class )]
مجموعه داده تست مدل، یک دهم از دادههای fposts ( از ابتدای تاپل) و مجموعه داده آموزش مدل، همه دادههای fposts به غیر از اون یک دهم مربوط به دادههای تست را شامل میشن.
مدل آموزش دیده میتونه با استفاده از مجموعه داده تست یا ورودی کاربر تست بشه. این مدل می تونه هر جمله توکن شده رو در دستههای مختلفی مثل Greetings ( سلام و خوشآمد گویی ها)، Statements (اظهارات)، Emotions (احساسات)، questions (سؤالات) و … طبقهبندی کنه.
classifier.classify(extract_features('Hi there!'))
خروجی:
Greet
classifier.classify(extract_features('Do you want to watch a film later?'))
خروجی:
ynQuestion
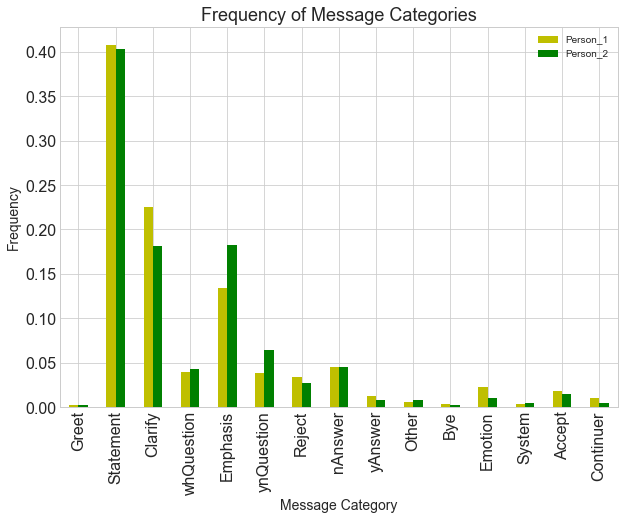
حالا بیایید مدل رو روی دادههای واتس آپ اجرا کنیم و هدف اصلی از این کار محاسبه میزان وقوع هر دسته از گفتگوهای توکن شده باشه:
ax = df.T.plot(kind='bar', figsize=(10, 7), legend=True,
fontsize=16, color=['y','g'])
ax.set_title("Frequency of Message Categories", fontsize= 18)
ax.set_xlabel("Message Category", fontsize=14)
ax.set_ylabel("Frequency", fontsize=14)
#plt.savefig('plots/cat_message') # uncomment to save
plt.show()
خروجی:
NLP برای احساسات ( ایموجی ها) چتهای واتس آپ
بدون شک، همه ما هنگام چت و گفتگو از ایموجی ها مختلف استفاده میکنیم چون در اکثر مواقع یک ایموجی منظور ما را خیلی بهتر و دقیقتر از یک جمله طولانی میرسونه. استفاده از ایموجی تنها محدود به واتس آپ نیست و هر پلتفرم چت با قرار دادن این امکان، کار را برای کاربر راحتتر کرده. حالا بیاید ببینیم که در گفتگوها از کدوم ایموجی ها بیشتر استفاده میشه:
این کد با استفاده از تابع extract_emojis، ایموجی هایی که هر شخص در گفتگوهاش استفاده کرده رو استخراج می کنه و با استفاده از Counter اون ۱۰ تا ایموجی که بیشتر استفاده کرده رو همراه با تعداد استخراج می کنه.
در کل خروجی دو بخش هست:
بخش اول: کل ایموجی هایی که شخص موردنظر در گفتگوهاش استفاده کرده
بخش دوم: ۱۰ ایموجی که بیشتر از ایموجی های دیگر استفاده کرده ( به همراه تعداد تکرار)
def extract_emojis(str):
return ''.join(c for c in str if c in emoji.UNICODE_EMOJI)
for key, val in ppl.items():
emojis=extract_emojis(str(ppl[key]))
count = Counter(emojis).most_common()[:10]
print("{}'s emojis:\n {} \n".format(key, emojis))
print("Most common: {}\n\n".format(count))
خروجی:


این خیلی جالبه که بدونیم یه شخص از کدوم ایموجی ها بیشتر استفاده میکنه چون این تنها راهیه که ما هنگام چت در واتس آپ برای بیان احساسات خودمون استفاده میکنیم.
بررسی احساسات در طی دورههای زمانی
ترسیم و نمایش تصویری احساسات در دورههای زمانی مختلف به این راحتی که به نظر می رسه، نیست. از آنجا که هر شخص در طول یک روز احساسات مختلفی رو تجربه می کنه بنابراین گام اول، ارزیابی میانگین احساسات برای هر روز و سپس گروهبندی آنها بر اساس معیار زمان هست. بیایید ببینیم که چجوری میتونیم این را انجام بدیم:
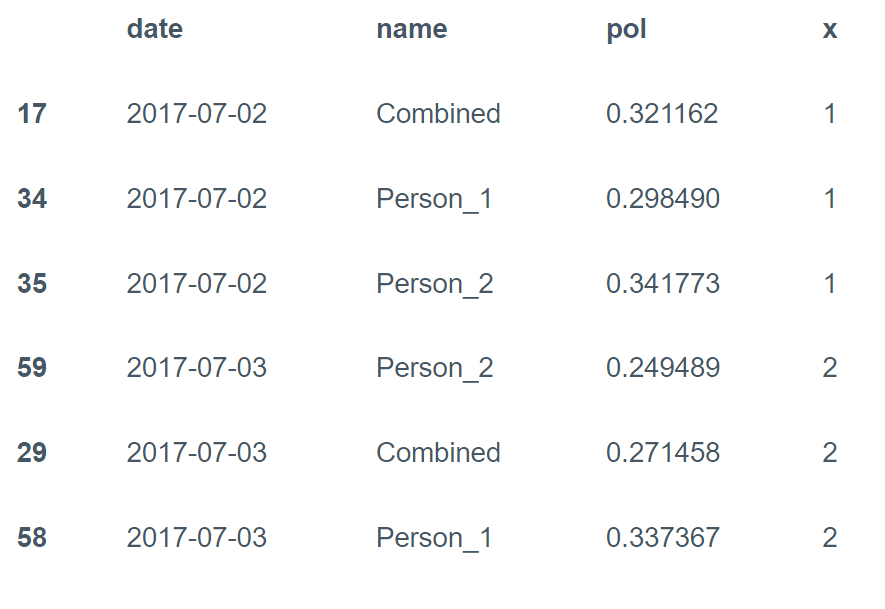
df= pd.DataFrame(final).T # convert dictionary to a dataframe, makes process of plotting straightforward
df.columns = ['pol', 'name', 'date', 'token']
df['pol'] = df['pol'].apply(lambda x : float(x)) # convert polarity to a float
df3 = df.groupby(['date'], as_index=False).agg('mean')
df3['name'] = 'Combined'
final =pd.concat([df2, df3])
final['date'] = pd.to_datetime(final.date, format='%d/%m/%Y') # need to chnage 'date' to a datetime object
final = final.sort_values('date')
final['x'] = final['date'].rank(method='dense', ascending=True).astype(int)
final[:6]
خروجی:
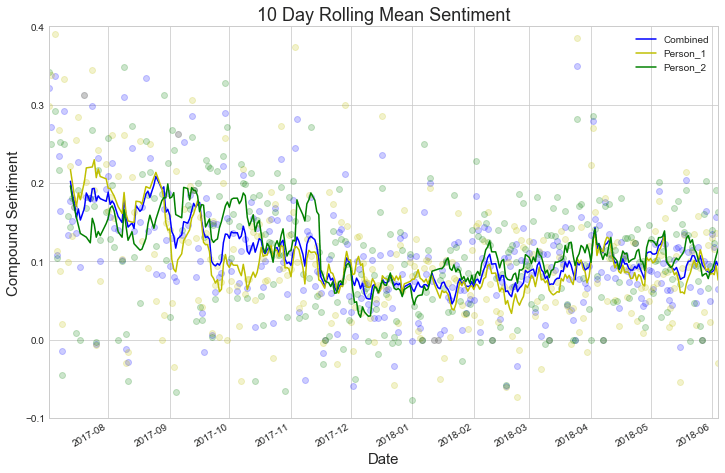
البته، ترسیم میانگین احساسات برای هر روز هم نتیجه چندان واضح و تمیزی به همراه نداره. بنابراین بیاید این میانگین رو بهجای هر روز برای ۱۰ روز درنظربگیریم و نمودار مربوط به میانگین احساسات رو بر این اساس ترسیم کنیم:
sns.set_style("whitegrid")
fig, ax = plt.subplots(figsize=(12,8))
colours=['b','y','g']
i=0
for label, df in final.groupby('name'):
new=df.reset_index()
new['rol'] = new['pol'].rolling(10).mean() # rolling mean calculation on a 10 day basis
g = new.plot(x='date', y='rol', ax=ax, label=label, color=colours[i]) # rolling mean plot
plt.scatter(df['date'].tolist(), df['pol'], color=colours[i], alpha=0.2) # underlying scatter plot
i+=1
ax.set_ybound(lower=-0.1, upper=0.4)
ax.set_xlabel('Date', fontsize=15)
ax.set_ylabel('Compound Sentiment', fontsize=15)
g.set_title('10 Day Rolling Mean Sentiment', fontsize=18)
خروجی:
فرکانس ( پراکندگی تعداد پیام ها در طول روز) چتها
حالا بیایید به فرکانس چتهای واتس آپ به نگاهی بندازیم که به بخش جدا از NLP برای واتس آپ هست ولی بخشی از تجزیه و تحلیل بر اساس زمان هست. ما اینجا می تونیم از سریهای زمانی برای مشاهده فرکانس چتها استفاده کنیم. اول نیاز به این داریم که یک پالت رنگی ایجاد کنیم که بر اساس تعداد کل پیامها در طول روز تنظیم شده باشه.
pal = sns.cubehelix_palette(7, rot=-.25, light=.7)
لیست مرتبشده بر اساس تعداد کل پیامها:
days_freq = list(df.day.value_counts().index)
days = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
ترتیب فعلی رنگها به صورت زیر هست:
lst = list(zip(days, pal[::-1]))
lst
خروجی:
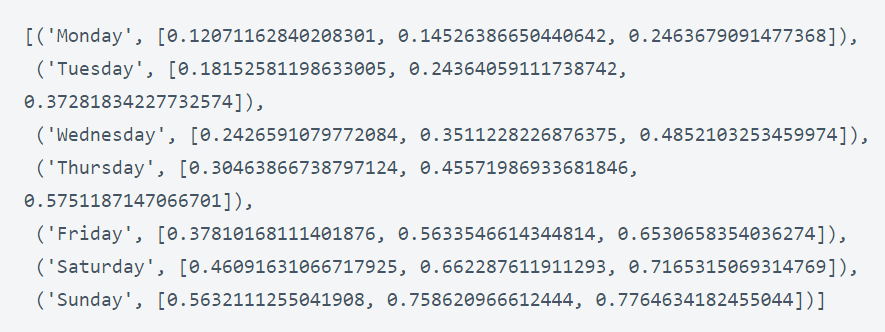
مرتبسازی مجدد رنگها بر اساس موقعیت ایندکس آنها در لیست ‘days_freq’:
pal_reorder=[]
for i in days:
#print(i)
j=0
for day in days_freq:
if i == day:
#print(lst[j][1])
pal_reorder.append(lst[j][1])
j+=1
pal_reorder # colours ordered according to total message count for the day
خروجی:
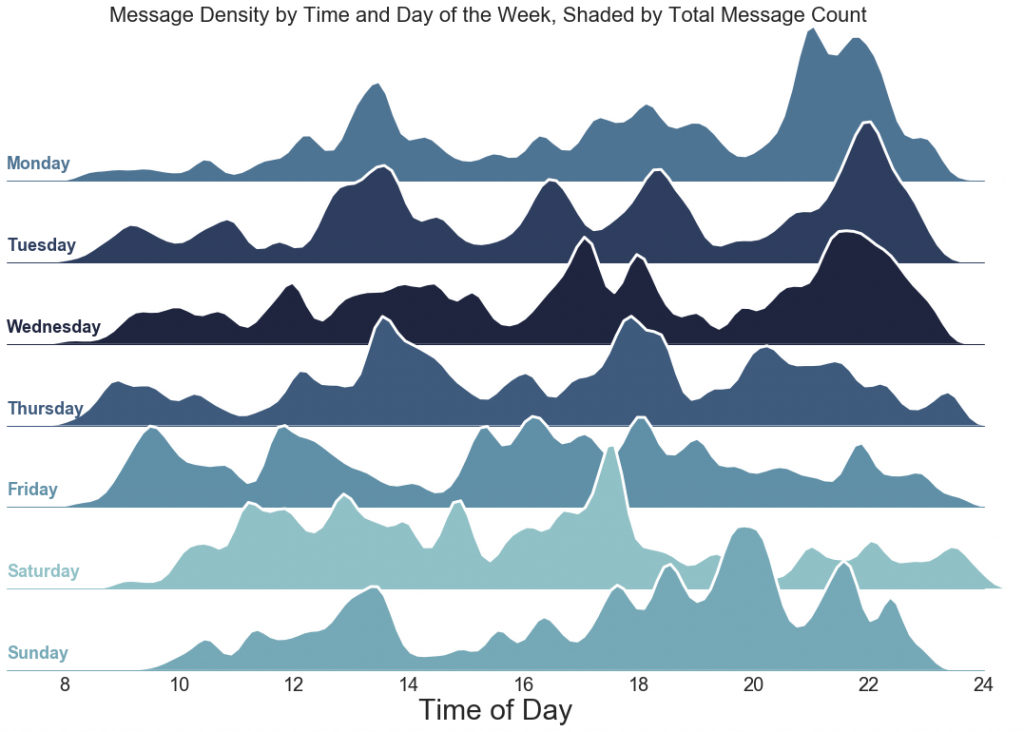
sns.set(style="white", rc={"axes.facecolor": (0, 0, 0, 0)})
pal = sns.cubehelix_palette(7, rot=-.25, light=.7)
g = sns.FacetGrid(df[(df.float_time > 8)], row="day", hue="day", # change "day" to year_month if required
aspect=10, size=1.5, palette=pal_reorder, xlim=(7,24))
# Draw the densities in a few steps
g.map(sns.kdeplot, "float_time", clip_on=False, shade=True, alpha=1, lw=1.5, bw=.2)
g.map(sns.kdeplot, "float_time", clip_on=False, color="w", lw=3, bw=.2)
g.map(plt.axhline, y=0, lw=1, clip_on=False)
# Define and use a simple function to label the plot in axes coordinates
def label(x, color, label):
ax = plt.gca()
ax.text(0, 0.1, label, fontweight="bold", color=color,
ha="left", va="center", transform=ax.transAxes, size=18)
g.map(label, "float_time")
g.set_xlabels('Time of Day', fontsize=30)
g.set_xticklabels(fontsize=20)
# Set the subplots to overlap
g.fig.subplots_adjust(hspace=-0.5)
g.fig.suptitle('Message Density by Time and Day of the Week, Shaded by Total Message Count', fontsize=22)
g.set_titles("")
g.set(yticks=[])
g.despine(bottom=True, left=True)
خروجی:
امیدواریم که از خوندن این مقاله که برای تجزیه و تحلیل چتهای واتس آپ با استفاده از NLP تهیه شده بود، لذت برده باشید و برای شما مفید واقع شده باشه.
برای هرگونه سوال در زمینه آموزش ها فقط کافیه روی لینک واتساپ یا تلگرام (در زیر همین پست) کلیک کنید. یا با شماره تماس بالای صفحه سایت تماس بگیرید.