
اکثر کیبوردهای گوشیهای هوشمند، ویژگی پیشبینی کلمه بعدی رو به کاربران ارائه میدن. گوگل هم با استفاده از تاریخچه جستجو و مرور از پیشبینی کلمه استفاده میکنه. پس میتونیم نتیجه بگیریم که دادههایی که ما قبلاً تایپ کردیم، در کیبورد گوشیها ذخیره میشن تا پیشبینی کلمه بعدی بهدرستی انجام بشه. تو این مقاله، ساخت یه مدل یادگیری عمیق برای پیشبینی کلمه بعدی رو به شما عزیزان آموزش میدیم. Tensorflow و Keras در پایتون، کتابخونه های موردنیاز برای پیادهسازی این تسک هستند.
ما تو این تسک برای ساخت مدل پیشبینی کلمه بعدی، یه شبکه عصبی بازگشتی (RNN) رو آموزش میدیم. پس بیایید بدون اتلاف وقت، کارمون رو شروع کنیم:
مدل پیشبینی کلمه بعدی
برای شروع کار باید پکیجها و کتابخونه های لازم برای ساخت مدل پیشبینی کلمه بعدی رو ایمپورت کنیم:
import numpy as np
from nltk.tokenize import RegexpTokenizer
from keras.models import Sequential, load_model
from keras.layers import LSTM
from keras.layers.core import Dense, Activation
from keras.optimizers import RMSprop
import matplotlib.pyplot as plt
import pickle
import heapq
همونطورکه قبلاً هم گفتیم، گوگل از تاریخچه جستجوی ما برای پیشبینی کلمه بعدی استفاده میکنه، آموزش کیبوردهای گوشیهای هوشمند با استفاده از برخی دادهها انجام میشه. دیتاستی که برای این تسک استفاده میکنیم، از طریق این لینک قابل دانلود هست:
حالا بیایید دادهها رو بارگذاری کنیم و یه نگاهی به ساختار اونها بندازیم تا بدونیم که برای پیادهسازی این تسک با چه دادههایی سروکار داریم:
path = '1661-0.txt'
text = open(path).read().lower()
print('corpus length:', len(text))
corpus length: 581887
بعد، دیتاست رو به کلمههای جدا تقسیم میکنیم و برخی از کاراکترهای خاص رو هم حذف میکنیم:
tokenizer = RegexpTokenizer(r'w+')
words = tokenizer.tokenize(text)
[‘project’, ‘gutenberg’, ‘s’, ‘the’, ‘adventures’, ‘of’, ‘sherlock’, ‘holmes’, ‘by’, …………………………. , ‘our’, ’email’, ‘newsletter’, ‘to’, ‘hear’, ‘about’, ‘new’, ‘ebooks’]
مرحله بعدی مربوط به مهندسی ویژگی دادهها هست. برای انجام این کار، به یه دیکشنری نیاز داریم که در این دیکشنری هر کلمه منحصربهفرد میشه key و value مربوط به هر key میشه ایندکس مربوط به اون در داخل لیست قبلی.
unique_words = np.unique(words)
unique_word_index = dict((c, i) for i, c in enumerate(unique_words))
مهندسی ویژگی
مهندسی ویژگی به این معناس که هر اطلاعاتی که در مورد مسئله یا مشکلمون داریم رو برداریم و اونها رو به اعدادی تبدیل کنیم که بعداً با استفاده از اون اعداد، ماتریس ویژگی رو ایجاد کنیم.
تو این بخش، یه متغیری رو بهعنوان طول کلمه تعریف میکنیم که نشون دهنده تعداد کلمات قبلی هست که در تعیین کلمه بعدی نقش دارند. تو این بخش prev-word رو برای نگهداری ۵ کلمه قبلی و next-words رو برای کلمات بعدی مرتبط با اونها تعریف میکنیم.
WORD_LENGTH = 5
prev_words = []
next_words = []
for i in range(len(words) - WORD_LENGTH):
prev_words.append(words[i:i + WORD_LENGTH])
next_words.append(words[i + WORD_LENGTH])
print(prev_words[0])
print(next_words[0])
[‘project’, ‘gutenberg’, ‘s’, ‘the’, ‘adventures’]
حالا دو تا آرایه numpy ایجاد میکنیم که x ویژگیها و y هم برچسب مرتبط با ویژگیها رو ذخیره کنه. اگه کلمه موجود باشه، x و y رو تکرار میکنیم که موقعیت مربوطه ۱ بشه.
X = np.zeros((len(prev_words), WORD_LENGTH, len(unique_words)), dtype=bool)
Y = np.zeros((len(next_words), len(unique_words)), dtype=bool)
for i, each_words in enumerate(prev_words):
for j, each_word in enumerate(each_words):
X[i, j, unique_word_index[each_word]] = 1
Y[i, unique_word_index[next_words[i]]] = 1
قبل از اینکه وارد مرحله بعدی بشیم، بهتره یه نگاهی بندازیم به یه توالی از کلمات:
print(X[0][0])
[False False False … False False False]
ساخت شبکه عصبی بازگشتی (RNN)
قبلاً هم اشاره شد که برای مدل پیشبینی کلمه بعدی از RNN استفاده میکنیم. اینجا از مدل LSTM که یه RNN خیلی قویه استفاده میکنیم.
model = Sequential()
model.add(LSTM(128, input_shape=(WORD_LENGTH, len(unique_words))))
model.add(Dense(len(unique_words)))
model.add(Activation('softmax'))
آموزش مدل تشخیص کلمه بعدی
خب حالا مدلی که ساختیم رو با ۲۰ دور تکرار و بهروزرسانی (epoch) آموزش میدیم:
optimizer = RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
history = model.fit(X, Y, validation_split=0.05, batch_size=128, epochs=2, shuffle=True).history
بعد اینکه مدلمون رو با موفقیت آموزش دادیم، قبل از اینکه وارد مرحله ارزیابی بشیم، مدل رو برای استفادههای بعدی ذخیره کنیم.
model.save('keras_next_word_model.h5')
pickle.dump(history, open("history.p", "wb"))
model = load_model('keras_next_word_model.h5')
history = pickle.load(open("history.p", "rb"))
ارزیابی مدل پیشبینی کلمه بعدی
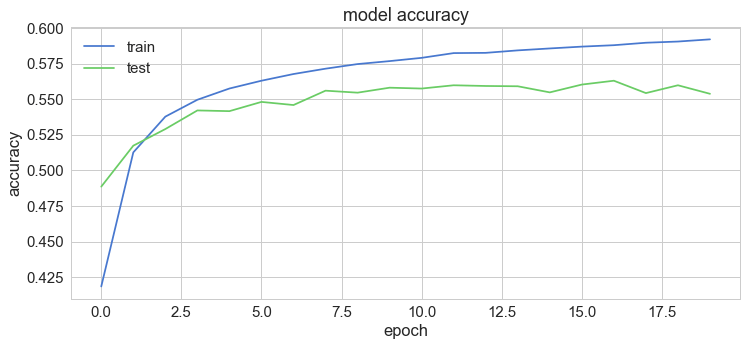
حالا نوبت اینه که بررسی کنیم مدلمون ازلحاظ تغییرات دقت و خطا، چه رفتاری از خودش نشون میده:
plt.plot(history['acc'])
plt.plot(history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
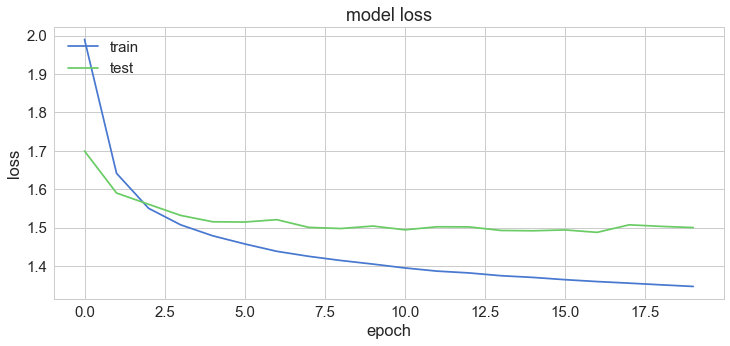
plt.plot(history['loss'])
plt.plot(history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
تست مدل پیشبینی کلمه بعدی
حالا وقت این رسیده که یه برنامه پایتون رو برای پیشبینی کلمه بعدی با استفاده از مدلمون ایجاد کنیم. اول، توابعی که در این فرآیند بهشون نیاز داریم رو تعریف میکنیم:
def prepare_input(text):
x = np.zeros((1, SEQUENCE_LENGTH, len(chars)))
for t, char in enumerate(text):
x[0, t, char_indices[char]] = 1.
return x
قبل از اینکه وارد مرحله بعدی بشیم، این تابع رو تست میکنیم. مطمئن بشید که از برای دادن ورودی از یه تابع ()lower (تابعی که همه حروف رشته ورودی رو به حروف کوچیک تبدیل میکنه) استفاده میکنین:
prepare_input("This is an example of input for our LSTM".lower())

توجه داشته باشین که توالیهایی که بهعنوان ورودی به برنامه میدیم باید حداکثر ۴۰ تا کاراکتر داشته باشند تا بهراحتی بتونیم اون رو در تنسور با ابعاد (۵۷, ۴۰, ۱) فیت کنیم. قبل از هر کار دیگ، اول بیایید بررسی کنیم که این تابع درست کار میکنه یا نه.
def prepare_input(text):
x = np.zeros((1, WORD_LENGTH, len(unique_words)))
for t, word in enumerate(text.split()):
print(word)
x[0, t, unique_word_index[word]] = 1
return x
prepare_input("It is not a lack".lower())

الآن یه تابع دیگر ایجاد میکنیم که sample ها رو بهعنوان خروجی برگردونه:
def sample(preds, top_n=3):
preds = np.asarray(preds).astype('float64')
preds = np.log(preds)
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
return heapq.nlargest(top_n, range(len(preds)), preds.take)
و درنهایت تابع اصلی رو برای پیشبینی کلمه بعدی ایجاد میکنیم:
def predict_completion(text):
original_text = text
generated = text
completion = ''
while True:
x = prepare_input(text)
preds = model.predict(x, verbose=0)[0]
next_index = sample(preds, top_n=1)[0]
next_char = indices_char[next_index]
text = text[1:] + next_char
completion += next_char
if len(original_text + completion) + 2 > len(original_text) and next_char == ' ':
return completion
این تابع تا زمان ایجاد فاصله، کلمه بعدی رو پیشبینی میکنه. تابع این کار رو با تکرار ورودی انجام میده که از مدل درخواست میکنه و نمونههایی رو از اون استخراج میکنه. حالا تابع بالا رو برای پیشبینی چند کاراکتر تغییر میدیم:
def predict_completions(text, n=3):
x = prepare_input(text)
preds = model.predict(x, verbose=0)[0]
next_indices = sample(preds, n)
return [indices_char[idx] + predict_completion(text[1:] + indices_char[idx]) for idx in next_indices]
خب الآن از یه توالی از ۴۰ کاراکتر استفاده میکنیم که بتونیم از اونها بهعنوان پایهای برای پیشبینیهای خودمون استفاده کنیم:
quotes = [
"It is not a lack of love, but a lack of friendship that makes unhappy marriages.",
"That which does not kill us makes us stronger.",
"I'm not upset that you lied to me, I'm upset that from now on I can't believe you.",
"And those who were seen dancing were thought to be insane by those who could not hear the music.",
"It is hard enough to remember my opinions, without also remembering my reasons for them!"
]
خب درنهایت میتونیم از این مدل برای پیشبینی کلمه بعدی استفاده کنیم:
for q in quotes:
seq = q[:40].lower()
print(seq)
print(predict_completions(seq, 5))
print()

امیدواریم که از این مقاله لذت برده باشید و یادگیری نحوه ساخت مدل پیشبینی کلمه بعدی براتون مفید واقع بشه.
برای هرگونه سوال در زمینه آموزش ها فقط کافیه روی لینک واتساپ یا تلگرام (در زیر همین پست) کلیک کنید. یا با شماره تماس بالای صفحه سایت تماس بگیرید.