
موجودیت یا همان entity نام دار به معنای هر چیزیه که در دنیای واقعی با یک اصطلاح خاصی شناخته می شه مثل، یک شخص، مکان، سازمان، محصول و هر چیزی که دارای یک اسم هست.
به عنوان مثال:
“My name is Aman, and I and a Machine Learning Trainer”
در این جمله اسم “Aman”، فیلد یا موضوع ” Machine Learning” و حرفه “مربی” همگی موجودیتهای نام دار هستند.
در یادگیری ماشین، شناسایی موجودیت نام دار یا NER یک تسک از پردازش زبان طبیعیه که برای شناسایی موجودیت نام دار در بخشی از متن استفاده میشه.
تا حالا از نرم افزاری به اسم Grammarly استفاده کردین؟ این ابزار، همه غلطهای املایی و نگارشی یک متن رو شناسایی می کنه و اونها رو تصحیح میکنه؛ اما Grammarly هیچ کاری با موجودیتهای نام دار نداره و همیشه از یه تکنیک استفاده میکنه. در این مقاله، به شرح کامل پروژه شناسایی موجودیت نام دار با یادگیری ماشین میپردازیم.
بارگذاری دیتاست لازم برای شناسایی موجودیت نام دار (NER)
دیتاستی که برای این پروژه استفاده شده بهراحتی از طریق این لینک قابل دانلود هست. حالا، اولین کاری که باید انجام بدیم اینه که دیتاست رو بارگذاری کنیم و یه نگاهی به ساختارش داشته باشیم تا بدونیم قراره این پروژه رو با چه دادههایی پیادهسازی کنیم.
files.upload تمام فایل هایی که در google colab آپلود شدند رو برمی گردونه و از این طریق دسترسی به فایل دیتاست رو امکانپذیر میشه. ایمپورت کتابخانه pandas و بارگذاری دادهها به صورت زیر انجام میشه:
from google.colab import files
uploaded = files.upload()
import pandas as pd
data = pd.read_csv('ner_dataset.csv', encoding= 'unicode_escape')
data.head()
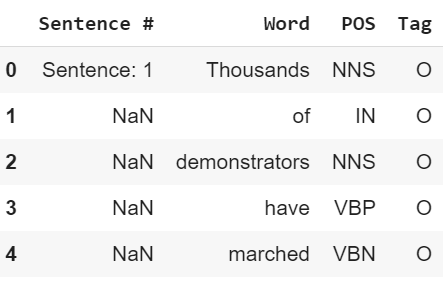
اگر به خروجی دقت کنیم، میبینیم که ستون word شامل کلماتی هستند که یه جمله و توالی این جملهها متن اصلی رو تشکیل میدن. منتها هر کدوم از این کلمات تو ردیفهای جدا قرار دارن. ستون word نشاندهنده ویژگی X و ستون tag نشاندهنده برچسب Y هست.
آمادهسازی دادهها برای شبکههای عصبی
در این پروژه، یک مدل شبکه عصبی برای شناسایی موجودیت نام دار آموزش داده میشه؛ بنابراین، ما باید یه سری تغییرات و اصلاحاتی روی دادهها انجام بدیم تا به نحوی آماده بشن که بهراحتی در یک شبکه عصبی فیت بشن. این مرحله با استخراج نگاشتهای لازم برای آموزش شبکه عصبی شروع میشه:
from itertools import chain
def get_dict_map(data, token_or_tag):
tok2idx = {}
idx2tok = {}
if token_or_tag == 'token':
vocab = list(set(data['Word'].to_list()))
else:
vocab = list(set(data['Tag'].to_list()))
idx2tok = {idx:tok for idx, tok in enumerate(vocab)}
tok2idx = {tok:idx for idx, tok in enumerate(vocab)}
return tok2idx, idx2tok
token2idx, idx2token = get_dict_map(data, 'token')
tag2idx, idx2tag = get_dict_map(data, 'tag')
با این کد، یه لیست از مقادیر ستون word و یه لیست از مقادیر ستون tag ایجاد میکنیم و بعد از اون این لیستها رو به دو دیکشنری تبدیل میکنیم.
حالا این ستونها رو به دادههایی تبدیل میکنیم که دادههای متوالی لازم برای شبکه عصبی استخراج بشه:
data['Word_idx'] = data['Word'].map(token2idx)
data['Tag_idx'] = data['Tag'].map(tag2idx)
data_fillna = data.fillna(method='ffill', axis=0)
# Groupby and collect columns
data_group = data_fillna.groupby(
['Sentence #'],as_index=False
)['Word', 'POS', 'Tag', 'Word_idx', 'Tag_idx'].agg(lambda x: list(x))
دیگر نوبت این رسیده که دیتاست رو به دو بخش دیتاست آموزش و تست تقسیم کنیم. برای این کار از یک تابع استفاده شده چون لایههای LSTM توالیهایی با طول یکسان رو قبول میکنه.
LSTM نوعی شبکه عصبی بازگشتی هست که قادر به یادگیری وابستگی ترتیبی در مسائل پیشبینی متوالی هست. این رفتار در حوزههای پیچیدهای مثل ترجمه ماشینی، تشخیص گفتار و … موردنیازه.
from sklearn.model_selection import train_test_split
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
def get_pad_train_test_val(data_group, data):
#get max token and tag length
n_token = len(list(set(data['Word'].to_list())))
n_tag = len(list(set(data['Tag'].to_list())))
#Pad tokens (X var)
tokens = data_group['Word_idx'].tolist()
maxlen = max([len(s) for s in tokens])
pad_tokens = pad_sequences(tokens, maxlen=maxlen, dtype='int32', padding='post', value= n_token - 1)
#Pad Tags (y var) and convert it into one hot encoding
tags = data_group['Tag_idx'].tolist()
pad_tags = pad_sequences(tags, maxlen=maxlen, dtype='int32', padding='post', value= tag2idx["O"])
n_tags = len(tag2idx)
pad_tags = [to_categorical(i, num_classes=n_tags) for i in pad_tags]
#Split train, test and validation set
tokens_, test_tokens, tags_, test_tags = train_test_split(pad_tokens, pad_tags, test_size=0.1, train_size=0.9, random_state=2020)
train_tokens, val_tokens, train_tags, val_tags = train_test_split(tokens_,tags_,test_size = 0.25,train_size =0.75, random_state=2020)
print(
'train_tokens length:', len(train_tokens),
'\ntrain_tokens length:', len(train_tokens),
'\ntest_tokens length:', len(test_tokens),
'\ntest_tags:', len(test_tags),
'\nval_tokens:', len(val_tokens),
'\nval_tags:', len(val_tags),
)
return train_tokens, val_tokens, test_tokens, train_tags, val_tags, test_tags
train_tokens, val_tokens, test_tokens, train_tags, val_tags, test_tags = get_pad_train_test_val(data_group, data)
train_tokens length: 32372
train_tokens length: 32372
test_tokens length: 4796
test_tags: 4796
val_tokens: 10791 val_tags: 10791
آموزش شبکه عصبی برای شناسایی موجودیت نام دار (NER)
حالا، کار رو با آموزش معماری شبکه عصبی مدل ادامه میدیم. پس بیایید کار رو با ایمپورت کردن همه پکیجهای لازم برای آموزش شبکه عصبی شروع کنیم.
import numpy as np
import tensorflow
from tensorflow.keras import Sequential, Model, Input
from tensorflow.keras.layers import LSTM, Embedding, Dense, TimeDistributed, Dropout, Bidirectional
from tensorflow.keras.utils import plot_model
from numpy.random import seed
seed(1)
tensorflow.random.set_seed(2)
لایه زیر ابعاد رو از لایه LSTM میگیره و بیشترین طول و بیشترین تگ ها رو به عنوان خروجی میده:
input_dim = len(list(set(data['Word'].to_list())))+1
output_dim = 64
input_length = max([len(s) for s in data_group['Word_idx'].tolist()])
n_tags = len(tag2idx)
خب، تو این بخش یه تابع کمکی ایجاد میکنیم که در ارائه خلاصهای از هر لایه مدل شبکه عصبی برای شناسایی موجودیت به ما کمک کنه:
def get_bilstm_lstm_model():
model = Sequential()
# Add Embedding layer
model.add(Embedding(input_dim=input_dim, output_dim=output_dim, input_length=input_length))
# Add bidirectional LSTM
model.add(Bidirectional(LSTM(units=output_dim, return_sequences=True, dropout=0.2, recurrent_dropout=0.2), merge_mode = 'concat'))
# Add LSTM
model.add(LSTM(units=output_dim, return_sequences=True, dropout=0.5, recurrent_dropout=0.5))
# Add timeDistributed Layer
model.add(TimeDistributed(Dense(n_tags, activation="relu")))
#Optimiser
# adam = k.optimizers.Adam(lr=0.0005, beta_1=0.9, beta_2=0.999)
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
return model
الآن یه تابع کمکی ایجاد میکنیم که در آموزش مدل شناسایی موجودیت نام دار بهمون کمک کنه:
def train_model(X, y, model):
loss = list()
for i in range(25):
# fit model for one epoch on this sequence
hist = model.fit(X, y, batch_size=1000, verbose=1, epochs=1, validation_split=0.2)
loss.append(hist.history['loss'][0])
return loss
درایو کد برای اجرا و تست کدهای قبلی:
results = pd.DataFrame()
model_bilstm_lstm = get_bilstm_lstm_model()
plot_model(model_bilstm_lstm)
results['with_add_lstm'] = train_model(train_tokens, np.array(train_tags), model_bilstm_lstm)
این مدل بعد از اینکه ۲۵ دور اجرا شد، یه خروجی نهایی به ما میده. به خاطر همین اجرای کامل اون کمی زمانبر هست.
تست مدل NER
الآن نوبت اینه که مدل رو روی بخشی از متن تست کنیم:
import spacy
from spacy import displacy
nlp = spacy.load('en_core_web_sm')
text = nlp('Hi, My name is Aman Kharwal \n I am from India \n I want to work with Google \n Steve Jobs is My Inspiration')
displacy.render(text, style = 'ent', jupyter=True)
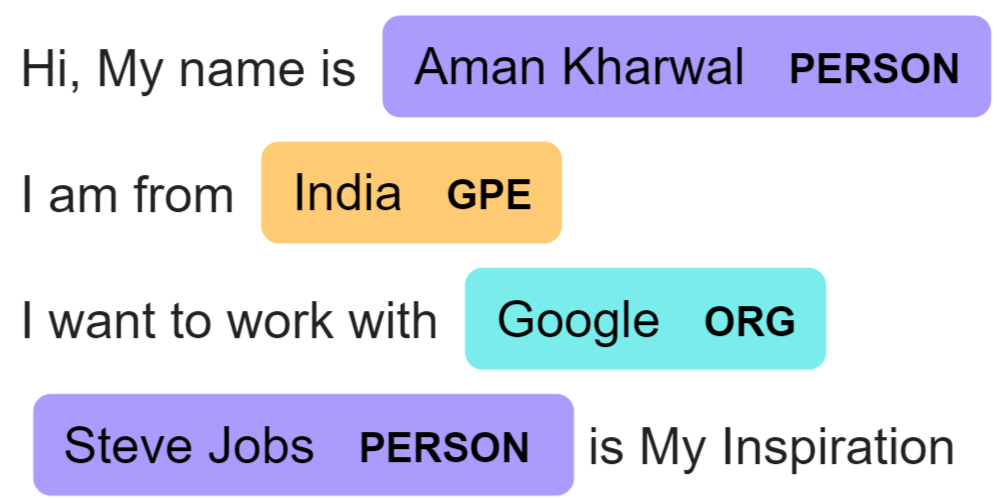
با مشاهده خروجی میتونیم به این نتیجه برسیم که مدل بهخوبی از عهده شناسایی موجودیتها برمیاد. امیدواریم که از این مقاله که در مورد شناسایی موجودیتهای نام دار هست، لذت برده باشید.
برای هرگونه سوال در زمینه آموزش ها فقط کافیه روی لینک واتساپ یا تلگرام (در زیر همین پست) کلیک کنید. یا با شماره تماس بالای صفحه سایت تماس بگیرید.