
سلاام! به همه علاقمندان به مباحث داغ شبکه های عصبی و به ویژه موضوع جذاب LSTM با ما با همراه باشید……
در این بخش می خوایم با استفاده از LSTM یک پیش بینی دقیق از قیمت بیت کوین داشته باشیم…. اما قبلش باید با چند اصطلاح و موضوع آشنا بشیم…
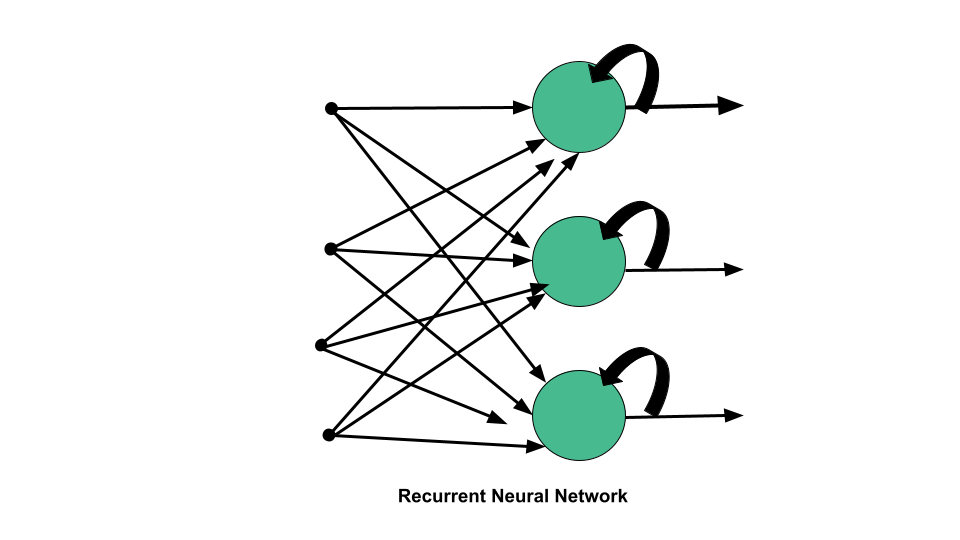
شبکههای عصبی بازگشتی یکی از الگوریتمهای پیشرفته برای دادههای متوالی هستن که در نرمافزار سیری اپل و جستجوی صوتی گوگل هم از این شبکهها استفاده شده. این الگوریتم طرز کارش به این صورته که به خاطر بهرهمندی از یه حافظه داخلی، ورودیهای خودش رو به خاطر میسپاره و همین ویژگی باعث شده که برای حل مشکلات یادگیری ماشین با دادههای متوالی یک گزینه کاملاً ایده آل و مناسب باشه. این الگوریتم در یادگیری عمیق نتایج بسیار خوبی داره. تو این مقاله، نحوه پیشبینی قیمت بیتکوین با تجزیهوتحلیل اطلاعات مربوط به یک سال پیش رو موردبررسی قرار میدیم. در کل، با استفاده از پایتون و شبکههای بازگشتی (RNN) مدلی ایجاد میکنیم که به کمک اون نحوه عملکرد بیتکوین در سریهای زمانی مختلف رو بهتر درک کنیم.
آشنایی با بیتکوین
بیتکوین، محبوبترین و ارزشمندترین ارز دیجیتاله که در ژانویه سال ۲۰۰۹ ایجاد شد. این ارز دیجیتال باارزش در بیش از ۴۰ صرافی سراسر جهان معامله میشه و بیش از ۳۰ ارز مختلف رو می پذیره. بیتکوین فرصت جدیدی رو برای پیشبینی قیمت ارائه میده چون نوسان این ارز در مقایسه با سایر ارزهای سنتی بسیار بیشتر است.
سیستم بیتکوین مجموعهای از نودهای نامتمرکزه که این نودها کد بیتکوین رو اجرا میکنن و بلاکچین اون رو ذخیره میکنند. بلاک چین مجموعهای از بلاکها و هر بلاک مجموعهای از تراکنشها هست. با توجه به اینکه همه کامپیوترهای اجراکننده این بلاکچین دارای لیست یکسانی از بلوکها و تراکنشها هستند، تشکیل بلوک جدید و اضافه شدن تراکنشهای جدید به این بلوک بهصورت کاملاً شفاف انجام میشه و هیچکس نمیتونه سیستم رو فریب بده.
بیتکوین برای راحت سازی پرداختهای فوری از تکنولوژی نظیر به نظیر استفاده میکنه. ماینر ها یا همون استخراجکنندههای بیتکوین مسئول پردازش تراکنشها در بلاکچین هستند و تحت تأثیر هزینههای بازخرید قرار میگیرند.
برای اینکه متوجه دلیل محبوبیت بیتکوین بشیم اول باید نحوه عملکرد اون رو درک کنیم. برخلاف سرمایهگذاریهای دیگر، ارز دیجیتال به دارایی فیزیکی یا دلار آمریکا وابسته نیست. کلاً هدف اصلی اینه که برای دو نفر در هر جای دنیا امکان مبادله ارز فراهم بشه. این به این معنیه که هیچ کنترل متمرکزی برای این شبکه وجود نداره، هیچ دولت و بانک مرکزی وجود نداره که بتونه بهصورت خودسرانه، ارزش بیتکوین رو کاهش بده یا اون رو بهطور کامل متوقف کنه.
این خیلی جالبه که ببینیم بانکهای مرکزی تا چه حدی شروع به دیجیتالی کردن ارزهای خود میکنند. هر چقد که سیستمهای مالی به سمت دیجیتالی شدن پیش برن، بیتکوین بیشتر موردتوجه قرار میگیره و جریان بهرهبرداری از اون تشدید پیدا میکنه ولی بهتره اینم بدونیم که تجدید فعالیت ارز دیجیتال با وضعیت مالی جهانی ارتباط نزدیکی داره.
هر بار که یک شخص تراکنش جدیدی انجام میده، برای تائید وضعیت، یک امضای دیجیتال منحصربهفرد به ledger اضافه میشه. حالا منظور از ledger چیه؟ ledger به لیستی از رکوردها هست که برای حفظ و نگهداری اطلاعات استفاده میشه. بلاکچین بهعنوان مجموعهای از بلاکها از نوع ledger هست و از ویژگیها و عملیات مخصوص این متغیر برخورداره.
تکنولوژیهای مورداستفاده
شبکههای عصبی بازگشتی (RNN)
RNN ها یکی از شبکههای عصبی قدرتمند هستند که به خاطر داشتن حافظه داخلی، یکی از حرفهای ترین الگوریتمها محسوب میشن.
شبکههای عصبی بازگشتی برای اولین بار در سال ۱۹۸۰ ایجاد شدند ولی عملکرد اونها در چند سال اخیر بهبود پیدا کرده و پتانسیل واقعیشون محقق شده. افزایش قدرت محاسباتی، حجم عظیم دادهها و اختراع حافظه کوتاهمدت از جمله دلایلی هستند که باعث مطرح شدن RNN ها شدند.
این الگوریتم برای دادههای متوالی مثل سریهای زمانی، متن، دادههای مالی، صدا، ویدیو، آبوهوا و … عملکرد بسیار خوبی داره. یه شبکه عصبی بازگشتی در مقایسه با الگوریتمهای دیگر، میتونه درک عمیقتری از یه دنباله و زمینه اون داشته باشه.
در یه RNN، اطلاعات یه چرخه رو طی میکنند و تصمیمگیری بر اساس ورودی فعلی هر آنچه از ورودیهای قبلی به دست اومده انجام میشه.
به این جمله دقت کنید: “ هر آنچه از ورودیهای قبلی به دست اومده“
شبکه عصبی عمیق به خاطر حافظه داخلی خودش، چیزهای مهمی که از ورودیهای قبلی به دست آورده رو ذخیره میکنه و تا بعداً به کمک اونها و ورودیهای بعدی تصمیمگیری دقیقتری برای پیشبینی موارد بعدی داشته باشه.
تصویر زیر نحوه عملکرد جریان اطلاعات در الگوریتم RNN رو نشون میده:
حافظه طولانی کوتاهمدت (LSTM)
شبکههای LSTM توسعهیافته شبکههای RNN هستند که بهطور اساسی حافظه رو گسترش میدن. به همین خاطر برای کاربردهایی که یادگیری از تجربیات مهم مربوط به فاصلههای زمانی زیاد لازمه، یه گزینه بسیار ایده آل محسوب میشه.
LSTM ها، شبکههای عصبی بازگشتی رو قادر میسازن که ورودیها رو طی مدت زمان طولانیتر به خاطر بسپارند. دلیل اصلی این ویژگی اینه که حافظه این شبکهها مثل کامپیوتر حاوی اطلاعاتی هستند و میتونن اون اطلاعات رو از حافظه بخونند، حذف کنند یا در حافظه بنویسند.
در LSTM، ۳ گیت داریم: گیت ورودی، گیت فراموشی و گیت خروجی.
این گیتها تعیین میکنند که اطلاعات جدید وارد بشه (گیت ورودی)، اطلاعات غیر مهم حذف بشه (گیت فراموشی) یا اینکه اطلاعات مهم روی خروجی تأثیر داده بشه (گیت خروجی). تصویر زیر مربوط به یه RNN با ۳ خروجی هست:
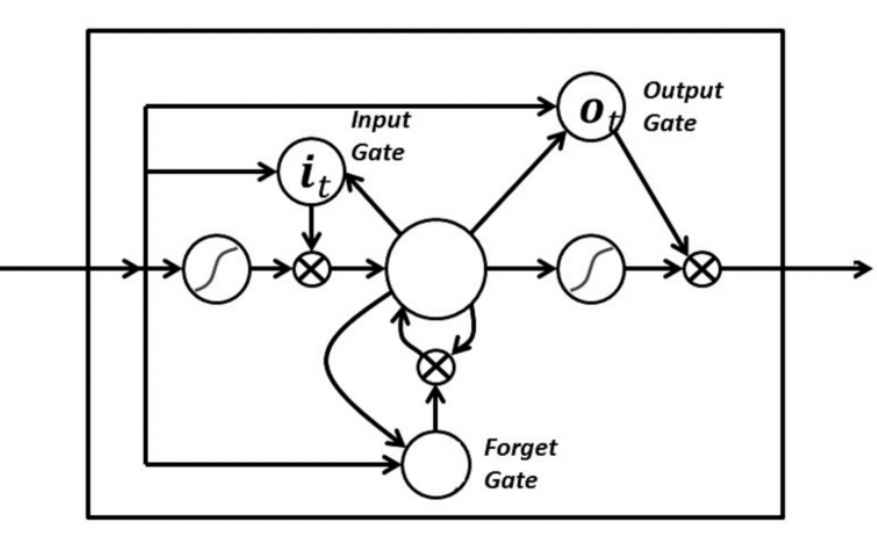
حافظه مربوط به LSTM حکم یه سلول در دار رو داره به این معنی که بر اساس اهمیتی که برای اطلاعات قائله تصمیم میگیره که اونها رو ذخیره یا حذف کنه. تعیین اهمیت از طریق وزنها انجام میشه که این وزنها هم طی فرآیند یادگیری توسط الگوریتم مشخص میشن. پس بهمرورزمان شبکه LSTM یاد میگیره که چطوری اطلاعات مهم و غیر مهم رو تشخیص بده و بر اساس اون تصمیمگیری های لازم رو انجام بده.
این گیتها در LSTM بهصورت سیگموئید هستند یعنی بازه اونها بین ۰ تا ۱ قرار داره. واقعیت اینه که آنالوگ بودن اونها باعث میشه که backpropagation (پس انتشار) امکانپذیر بشه.
backpropagation بهعنوان یه الگوریتم سوارکار اسب در یادگیری ماشین شناخته میشه. پس انتشار برای محاسبه گرادیان تابع خطا با توجه به وزنهای شبکه عصبی استفاده میشه. این الگوریتم توسط لایههای مختلف به عقب برمیگرده تا با توجه به وزنها، مشتق جزئی خطاها رو پیدا کنه. backpropagation از این وزنها برای کاهش حاشیه خطاها هنگام آموزش استفاده میکنه.
دریافت دیتاست ارز دیجیتال
خب بیاید وارد بخش کدنویسی بشیم…
دیتاست مربوط به این تسک رو میتونید از طریق این لینک دانلود کنید. توجه داشته باشید که این دیتاست بلادرنگ با گذشت زمان تغییر میکنه و رکوردهای جدیدی متناسب با قیمت بیتکوین در تاریخهای جدید ثبت میشه.
تو این بخش برای جداسازی مجموعه داده آموزش و تست یه تاریخی رو مشخص میکنیم و دادههای قبل از اون رو در مجموعه آموزش و دادههای بعد اونو در مجموعه تست قرار میدیم. ما تقسیمبندی رو طوری انجام دادیم که ۸۰ درصد رو برای مجموعه آموزش و ۲۰ درصد رو برای مجموعه تست در نظر گرفتیم و با محاسبه درصدی، تاریخ ’۰۸-۰۵-۲۰۲۱′ برای این نوع تقسیمبندی مناسب بود.
با استفاده از dropna رکوردهایی که مقادیر ستونهای قیمت اون NAN هست رو از دیتاست حذف میکنیم تا بعداً محاسبات بهدرستی انجام بشن. ما برای حذف رکوردهای NAN، ستون Close رو در نظر گرفتیم.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
data = pd.read_csv('BTC-USD.csv', date_parser = True)
data.dropna(subset = ["Close"], inplace=True)
data.tail(360)
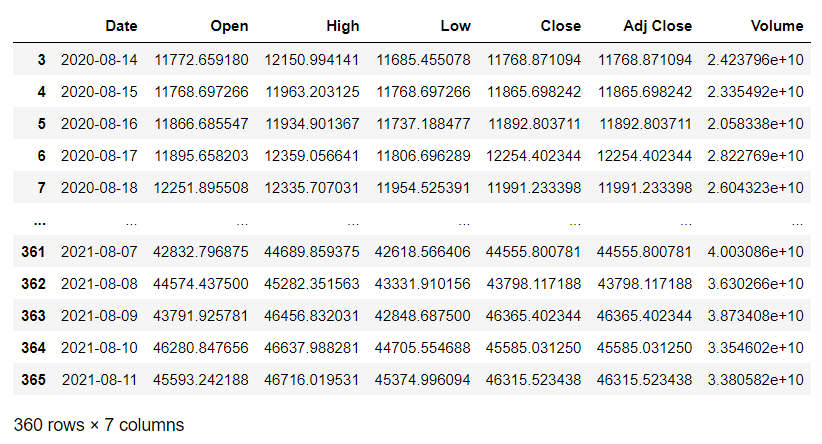
data_training = data[data['Date']< '2021-05-28'].copy()
data_training
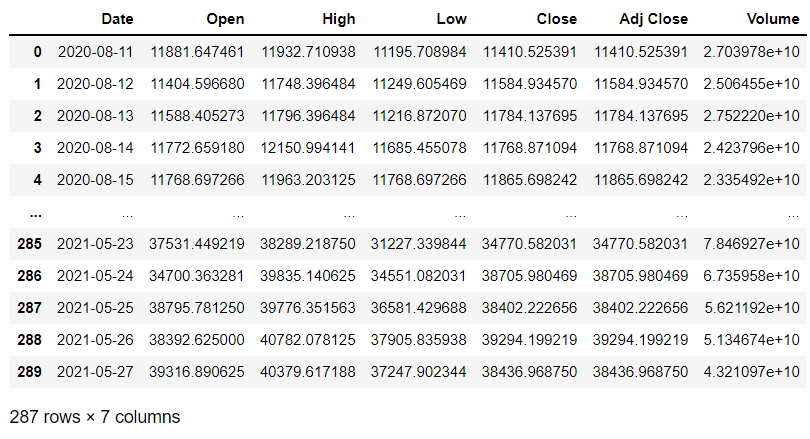
data_test = data[data['Date']> '2021-05-28'].copy()
data_test
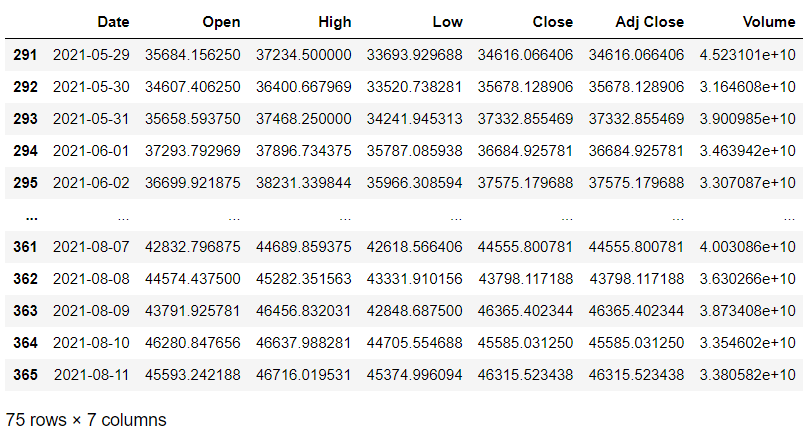
حالا چون در ادامه نیاز به نرمالسازی داریم، بهتره که ستون ‘Date’ و ‘Adj Close’ رو از دیتاست حذف کنیم تا نرمالسازی بهدرستی انجام بشه.
training_data = data_training.drop(['Date', 'Adj Close'], axis = 1)
training_data.head()
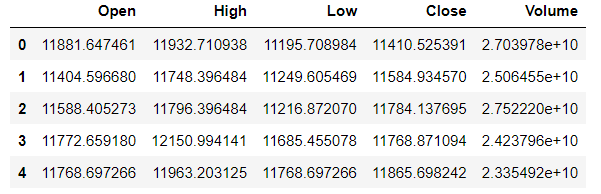
نرمالسازی
اولین کاری که باید در مورد دادهها انجام بدیم اینه که مقادیر مربوط به هر کدوم از ستونهای باقیمانده رو نرمال کنیم. هدف از نرمالسازی اینه که بدون ایجاد تحریف در بازه اعداد، مقادیر برای این نرمالسازی اول یه شی از MinMaxScaler تعریف میکنیم و با استفاده از متد fit_transform مقادیر عددی مربوط به مجموعه داده آموزش رو به حالت نرمال تغییر میدیم و این مقدار نرمال با محاسبه میانگین و مشتق جزئی به دست میاد.
scaler = MinMaxScaler()
training_data = scaler.fit_transform(training_data)
training_data

بعد نرمالسازی نوبت اینه که مقادیر x و y مربوط به دیتاست آموزش رو مقداردهی کنیم. برای این که معیار ۶۰ روز رو مشخص میکنیم. به این صورت که مقادیر ستونهای هر ۶۰ روز میشه x و مقدار قیمت open مربوط به روز بعد میشه y.
X_train = []
Y_train = []
training_data.shape[0]
for i in range(60, training_data.shape[0]):
X_train.append(training_data[i-60:i])
Y_train.append(training_data[i,0])
X_train, Y_train = np.array(X_train), np.array(Y_train)
X_train.shape
(۲۲۷, ۶۰, ۵)
بهعنوان مثال، اگر دور اول رو در نظر بگیریم نحوه مقداردهی اینجوری میشه:
i = 60
Training_data[ i-60:i ] => Training_data[ 0:60 ]
خروجی این میشه یه آرایه از مقادیر نرمال شده ۵ ستون مربوط به رکوردهای ۰ تا ۵۹ که append میشه به X_train و بعد برای Y-train هم اینجوری میشه که:
Training_data[ i:0 ] => Training_data[ 60:0 ]
خروجی این میشه مقدار قیمت open مربوط به رکورد ۶۰ که برای Y نظیر آرایه رکوردهای ۰ تا ۵۹ (X) در نظر گرفته میشه.
پیشبینی قیمت بیتکوین با استفاده از شبکه عصبی LSTM (یادگیری عمیق)
تو این بخش دیگ وارد مرحله ساخت مدل میشیم. پیدا کردن یه مدل درست واقعاً یه هنره چون ساخت یه مدل با لایههای درست و تعیین پارامترهای مناسب برای هر کدوم نیاز به چندین بار تست و اصلاح داره.
مدلی که میخوایم برای این نوع مسئله بسازیم کاملاً ساده و استاندارد هست.
آموزش این مدل رو میتونید بهراحتی و حتی بدون GPU هم انجام بدید چون حجم داده کمه و معماری شبکه خیلی ساده هست ولی آموزش مدلهایی که به خاطر اطلاعات تخصصی، پیشرفتهتر میشن میتونه چند ساعت یا چند روز طول بکشه.
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout
#Initialize the RNN
model = Sequential()
model.add(LSTM(units = 50, activation = 'relu', return_sequences = True, input_shape = (X_train.shape[1], 5)))
model.add(Dropout(0.2))
model.add(LSTM(units = 60, activation = 'relu', return_sequences = True))
model.add(Dropout(0.3))
model.add(LSTM(units = 80, activation = 'relu', return_sequences = True))
model.add(Dropout(0.4))
model.add(LSTM(units = 120, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(units =1))
model.summary()

بعدازاینکه پکیجهای لازم رو ایمپورت کردیم نوبت میرسه به مرحله ایجاد مدل. مدل ما از نوع sequential هست و این مدل برای ایجاد یه استک از لایهها که هر لایه یه تنسور ورودی و خروجی داره، مناسبه. هر لایه رو با استفاده از add به مدل اضافه میکنیم. لایههای اصلی از نوع LSTM هستند که با تعداد unit های متفاوت مقداردهی شدند.
حالا بهتره که آرگومانها رو بررسی کنیم تا جزئیات لایهها مشخص بشه:
units: ابعاد فضای خروجی یا همون تعداد نورونها رو مشخص میکنه (یک عدد صحیح مثبت).
Activation: تابع Activation برای به دست آوردن خروجی لایه موردنظر استفاده میشه. در حال حاضر Relu یکی از پرکاربردترین توابع Activation هست که تقریباً در همه شبکههای عصبی کانولوشن و یادگیری عمیق استفاده میشه.
return_sequences: این آرگومان با True یا False مقداردهی میشه. به این صورت که اگر True باشه، خروجی اون لایه یه توالی میشه و اگر False باشه، خروجی یک بردار میشه.
input_shape: این آرگومان برای لایه اول لازمه. اگر بخوایم بیشتر توضیح بدیم، دلیلش اینه که لایه ورودی یه لایه محسوب نمیشه و فقط بهعنوان یه تنسور مقادیر ورودی رو به اولین لایه مخفی ارسال میکنه. ابعاد این تنسور باید با ابعاد مجموعه آموزش یکی باشه که مقداردهی ابعاد از طریق این آرگومان انجام میشه.
Dropout: لایه Dropout که بعد از هر لایه LSTM اضافه شده، مسئول اینه که بر اساس نرخی که براش مشخص میشه، بهطور تصادفی مقدار بعضی از unit یا نورونهای ورودی رو صفر قرار بده تا از Overfitting جلوگیری کنه. حالا برای اینکه مجموع کل مقادیر نورونها بدون تغییر بمونن، اون واحدهایی که صفر نشدن رو بهاندازه (۱-rate) /1 افزایش میده.
Dense: لایه Dense یه لایه ساده هست که هر نورون رو به نورون لایه بعدی متصل میکنه. درواقع، این لایه نشون دهنده ضرب برداری ماتریسی هست که مقادیر این ماتریس پارامترهای قابلآموزش هستن و حین backpropagation بهروزرسانی میشن.
توجه: اگر تو اجرای این بخش با خطای زیر مواجه شدید:
NotImplementedError: Cannot convert a symbolic Tensor (2nd_target:0) to a numpy array
برای برطرف کردن این خطا کافیه که ورژن پایتون رو به ۳.۶ و ورژن numpy رو به ۱.۱۹.۵ تغییر بدید.
حالا بعد از ایجاد مدل، نوبت به کامپایل و آموزش مدل میرسه:
model.compile(optimizer = 'adam', loss = 'mean_squared_error')
history= model.fit(X_train, Y_train, epochs = 20, batch_size =50, validation_split=0.1)
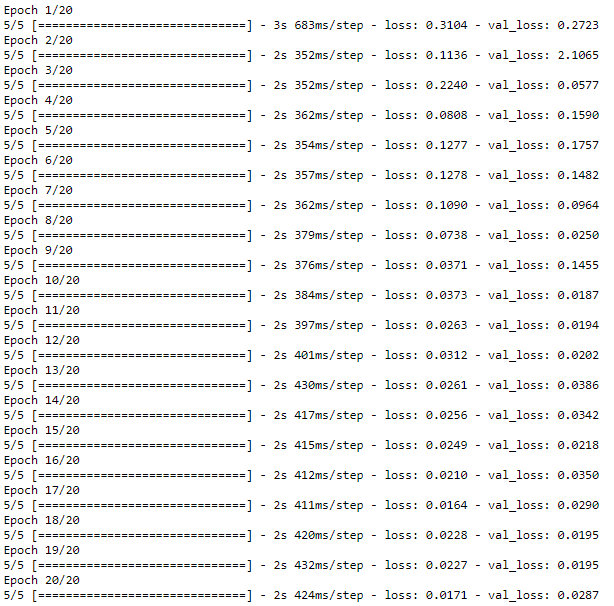
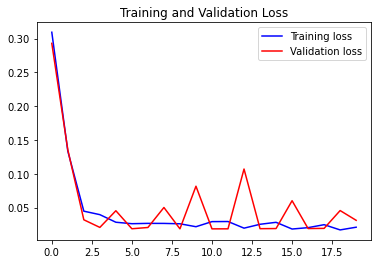
تو این قسمت هم با استفاده از نمودار خطی، میزان خطای train و validation رو نشون میدیم:
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(loss))
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title("Training and Validation Loss")
plt.legend()
plt.show()
دیتاست تست
برای تست مدل از دادههای مربوط به ۶۰ روز آخر مجموعه آموزش استفاده میکنیم. به این صورت که اول این مقادیر مربوط به این ۶۰ روز رو در یه دیتا فریم قرار میدیم بعد مجموعه تستی که قبل با استفاده از یه تاریخ مشخص کردین رو به اون دیتا فریم اضافه میکنیم و ستونهایی که لازم نیستن رو حذف میکنیم.
part_60_days = data_training.tail(60)
df= part_60_days.append(data_test, ignore_index = True)
df = df.drop(['Date', 'Adj Close'], axis = 1)
df.head()
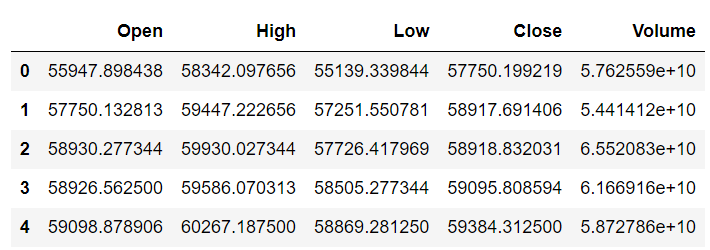
نرمال سازی برای این دیتاست هم انجام میشه:
inputs = scaler.transform(df)
مقداردهی x و y مجموعه تست هم درست مثل مجموعه داده آموزش انجام میشه:
X_test = []
Y_test = []
for i in range (60, inputs.shape[0]):
X_test.append(inputs[i-60:i])
Y_test.append(inputs[i, 0])
X_test, Y_test = np.array(X_test), np.array(Y_test)
Y_pred = model.predict(X_test)
بعد با ضرب یه متغیر float با یه مقدار مشخص، مقیاس دادههای x , y تست رو تغییر میدیم تا اعداد از محدوده صفر و یک خارج بشن.
scale = 1/5.18164146e-05
Y_test = Y_test*scale
Y_pred = Y_pred*scale
حالا با استفاده از نمودار خطی، رابطه بین قیمت واقعی و قیمت پیشبینیشده رو ترسیم میکنیم:
plt.figure(figsize=(14,5))
plt.plot(Y_test, color = 'red', label = 'Real Bitcoin Price')
plt.plot(Y_pred, color = 'green', label = 'Predicted Bitcoin Price')
plt.title('Bitcoin Price Prediction using RNN-LSTM')
plt.xlabel('Time')
plt.ylabel('Price')
plt.legend()
plt.show()
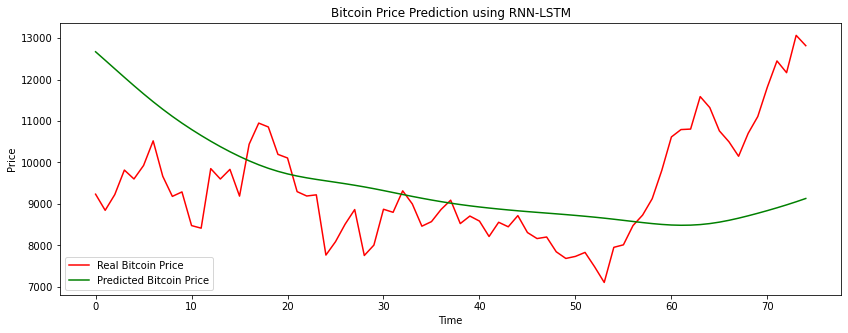
RNN ها و LSTM تکنولوژیهای عالی هستند و معماری فوقالعاده اونها باعث شده که یه گزینه عالی برای تجزیهوتحلیل و پیشبینی سریهای زمانی باشند. تمرکز ما بیشتر روی این بود که یه مدل ساده رو برای پیشبینی قیمت ارائه بدیم. اگر به این موضوع خیلی علاقه دارید، میتونید چیزهای مختلفی رو امتحان کنید و آرگومانهای لایهها و پارامترهای دیگه رو تغییر بدید و نتایج رو مشاهده کنید.
برای هرگونه سوال در زمینه آموزش ها فقط کافیه روی لینک واتساپ یا تلگرام (در زیر همین پست) کلیک کنید. یا با شماره تماس بالای صفحه سایت تماس بگیرید.