
صنعت خودرو در حال حاضر تغییر الگویی را از وسایل نقلیه معمولی بشر به وسایل نقلیه خودران مستقل تجربه می کند.در حال حاضر ، اتومبیل های خودران دائماً تیتر اول روزنامه ها هستند. آنچه دهه ها پیش به نظر می رسید یک فیلم علمی تخیلی است ، در حال حاضر واقعیت دارد. ما در حال حاضر خودروهایی داریم که برای حمل انسان از نقطه A به نقطه B بدون دخالت انسان طراحی شده است. در حال حاضر اتومبیل های خودران یکی از داغ ترین زمینه های تحقیق هستند و شکی نیست که خودروهای خودران ،آینده هستند!
این خودروهای خودران از بینایی کامپیوتر و یادگیری عمیق در حل مشکلات خودرو از جمله تشخیص خطوط مسیر ، پیش بینی زاویه فرمان و موارد دیگر استفاده می کنند.
در این بخش ، نحوه استفاده از تکنیک های ضروری بینایی کامپیوتر برای شناسایی خطوط مسیر در جاده ها را آموزش می دهیم.
بینایی کامپیوتر برای رانندگی خودکار:
ما انسانها به شدت به حواس پنجگانه خود وابسته ایم تا آن چیزی را که در اطراف ما می گذرد تفسیر کنیم. هر حسی برای ما به یک اندازه مهم است.ما از چشم ها برای دیدن و درک بسیاری از چیزهای اطراف خود استفاده می کنیم. این به ما کمک می کند تا جاده اطراف خود را ببینیم ، موانع اطراف خود را ببینیم ، خطوط را تشخیص دهیم و موارد دیگر. در برنامه های کاربردی مانند خودرو خودران ، Robotics ، این هنوز یکی از چالش برانگیزترین کارها برای آموزش ماشین ها برای دیدن و درک همچون انسان ها است.
بینایی کامپیوتر یکی از موضوعات داغ در هوش مصنوعی است. این برنامه به طور گسترده در رباتیک ، وسایل نقلیه خودران ، طبقه بندی تصاویر ، تشخیص و ردیابی اشیاء ، تقسیم بندی معنایی(semantic segmentation) و همچنین در برنامه های مختلف تصحیح عکس استفاده می شود. در خودروهای خودران ، بینایی منبع اصلی اطلاعات برای تشخیص خطوط ، چراغ های راهنمایی و سایر ویژگی های بصری است.
با وجود چالش ها ، در حال حاضر پیشرفت های زیادی در زمینه بینایی کامپیوتر انجام شده است.

خودروهای خودران مانند تسلا به شدت به دوربین/بینایی کامپیوتر بستگی دارند در حالی که رقیب آن به Lidar بستگی دارد. ایلان ماسک در روز رونمایی از خودرو خودران بیان کرد که” لیدار کار افراد احمق است ، هر کسی به لیدار تکیه کند محکوم به فنا است!بحث های زیادی در مورد اینکه کدام بهتر است انجام شده است.
بنابراین حسگر غنی تر و عمیق تر دوربین است ، اما سخت تر است ، شما باید حجم عظیمی از اطلاعات را جمع آوری کنید.
به طور طبیعی ، یکی از اولین کارهایی که در توسعه یک خودروی خودران انجام می شود ، تشخیص خودکار خطوط مسیر با استفاده از نوعی الگوریتم است. در این پروژه ، از پایتون و OpenCV برای شناسایی خودکار خطوط مسیر استفاده خواهیم کرد.
OpenCV:
OpenCV مخفف “Open Source Computer Vision” یک کتابخانه برای بینایی کامپیوتر و یادگیری ماشین است که توسط Intel در سال ۱۹۹۹ اختراع شد. OpenCV دارای رابط های C++ ، Python ، Java و MATLAB است و از Windows ، Linux ، Android و Mac OS پشتیبانی می کند. OpenCV به زبان ++C نوشته شده است و دارای یک رابط است که به طور یکپارچه با نگه دارنده های STL کار می کند.

نصب OpenCV:
OpenCV را میتوان با پکیچ pip installer نصب کرد.
pip install opencv-python
جزئیات نصب کردن را میتوانید اینجا ببینید:OpenCV-python installation
راستی آزمایی کردن نصب OpenCV:
بعد از نصب کردن, پکیچ را import کنید تا مطمئن شوید همه چیز خوب کار میکند.
import cv2
cv2.__version__
اگر بدون هیچ خطایی کار میکند میتوانیم به مراحل بعد برویم.
تشخیص خطوط مسیر با استفاده از OpenCV
لود کردن تصاویر و مشخص کردن محدوده موردنظر:
هدف این بخش ایجاد برنامه ای است که بتواند خطوط مسیر را در یک تصویر یا یک فریم ویدیویی تشخیص دهد. وقتی ما انسان ها رانندگی می کنیم ، از چشم و عقل برای رانندگی استفاده می کنیم. ما به راحتی می توانیم خطوط جاده را تشخیص دهیم و بر اساس آن عملیات را انجام می دهیم. اما انجام این کار با ماشین ها ، کار دشواری است و در آن زمان بینایی کامپیوتر وارد می شود. ما الگوریتم های پیچیده بینایی کامپیوتری را ایجاد می کنیم تا به ماشین ها تشخیص خطوط مسیر را آموزش بدهیم.
رویکرد اصلی ما در اینجا ایجاد دنباله ای از توابع به منظور تشخیص خطوط مسیر است. ما از فریم تصویر به عنوان نمونه تصویر استفاده می کنیم ، وقتی که توانستیم خطوط مسیر را در این قاب تصویر تشخیص دهیم ، سپس همه تصاویر ویدئویی دوربین مدار بسته و خطوط خط تشخیص داده شده را کنار هم قرار می دهیم.
کار را با این تصویر آغاز میکنیم:

بارگذاری تصویر و تبدیل به مقیاس خاکستری(grayscale):
بارگذاری تصویر در opencv خیلی آسان انجام میشود:
import cv2
lane_image = cv2.imread('road.jpeg')
دلیل اینکه ما مجبوریم این تصویر را به مقیاس خاکستری تبدیل کنیم این است که پردازش تک کانال بسیار سریعتر از RGB سه کاناله است و شدت محاسبات آن کمتر است. یک تصویر رنگارنگ دارای ۳ کانال قرمز ، سبز و آبی است. هر پیکسل دارای شدت ۳ رنگ می باشد. اما در GrayScale شدت فقط برای یک رنگ از ۰ تا ۲۵۵ متغیر است.
تبدیل عکس به مقیاس خاکستری:
gray = cv2.cvtColor(lane_image, cv2.COLOR_RGB2GRAY)

کاهش نویز و صاف کردن تصویر:
این تصویر شامل Noise است و باید آنها را حذف کنیم. با تار کردن تصویر می توان نویز را حذف کرد. نویز تصویر باعث ایجاد لبه های کاذب می شود و در نهایت می تواند روی تشخیص لبه تأثیر بگذارد که یک مرحله بسیار مهم در تشخیص خطوط است. دلایل زیادی برای تار کردن وجود دارد ، اما در اینجا از آن برای کاهش نویز استفاده می کنیم. ما از فیلتر Gaussian غیر یکنواخت کم گذربرای تار کردن تصویر استفاده می کنیم.
blur = cv2.GaussianBlur(gray, (5,5), 0)

توجه کنید که ارتفاع و عرض کرنل باید یک عدد مثبت و فرد باشد. شما می توانید ارتفاع و عرض کرنل را افزایش یا کاهش دهید تا تغییر شدت تاری را مشاهده کنید.
در OpenCV استفاده از فیلتر Gaussian بسیار ساده است ، اما تغییر پارامترها نیاز به درک ریاضیات نویز تصویر دارد.
تشخیص لبه(canny):
تشخیص لبه canny یکی از الگوریتم های تشخیص لبه است که بسیار مورد استفاده قرار می گیرد. این الگوریتم چند مرحله ای برای تشخیص لبه توسط جان کانی در سال ۱۹۸۶ توسعه یافته است. مراحل مختلف الگوریتم تشخیص لبه کانی عبارتند از:
۱. کاهش نویز
۲. یافتن گرادیان شدت تصویر
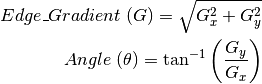
۳.توقیف غیر ماکزیمم
۴.آستانه گذاری Hysteresis
تابع Canny Edge همچنین فیلتر کرنل Gaussian پنج در پنج را پیاده سازی می کند که در مرحله قبل استفاده کردیم. با وجود اینکه Canny عملکرد خود را برای حذف نویز دارد ، توصیه می شود قبل از تشخیص Canny Edge ، عملکرد تار کردن را پیاده کنید.
ما لبه را ناحیه ای از تصویر می نامیم که در آن تغییر شدید در شدت یا تغییر شدید رنگ بین پیکسل های مجاور در تصویر وجود دارد. تغییر در روشنایییک سری پیکسل بیش از یک درجه است. شیب قوی نشان دهنده تغییر شدید و شیب کوچک نشان دهنده تغییر سطحی است. هر جایی که لبه ای وجود داشته باشد ، پیکسل های مجاور در دو طرف لبه تفاوت زیادی بین شدت خود دارند. تصویر ابتدا در جهت افقی و عمودی اسکن می شود تا برای هر پیکسل درجه پیدا شود. پس از به دست آوردن اندازه و جهت شیب ، اسکن کامل یک تصویر برای حذف پیکسل های ناخواسته که ممکن است لبه را تشکیل ندهند ، انجام می شود.اگر حداکثر محلی در همسایگی هر پیکسل باشد آن پیکسل بررسی می شود . این مرحله سرکوب غیر حداکثر نامیده می شود.
canny = cv2. Canny (تصویر ، آستانه کم ، آستانه بالا)
low_threshold و above_threshold را تعیین کنید که لبه باید چقدر قوی باشد تا تشخیص داده شود.آستانه پیشنهاد داده شده از کم به زیاد ۱:۲ یا ۱:۳ است.
cannyImage = cv2.Canny(blur, 50, 150)
حالا که قوی ترین شیب را محاسبه کردیم ، باید منطقه مورد نظر خود را مشخص کنیم.قبل از آن ، همه اینها را کنار هم قرار میدهیم.
def CannyEdge(image):
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
blur = cv2.GaussianBlur(gray, (5,5), 0)
cannyImage = cv2.Canny(blur, 60, 180)
return cannyImage
ناحیه مورد نظر:
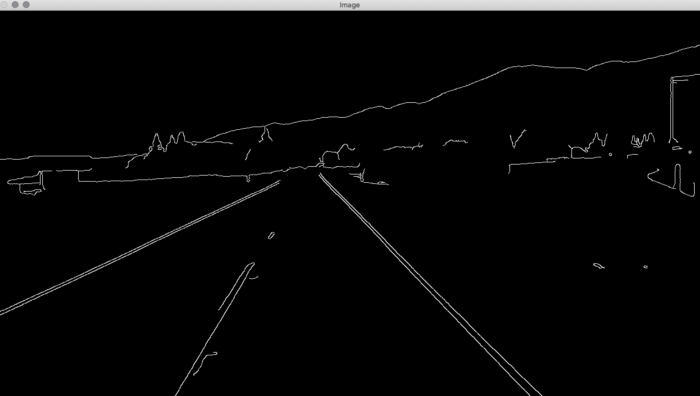
برای ما مساحت داخل این مثلث قرمز منطقه مورد نظر است. ما برای تعیین منطقه مورد نظر خود به مختصات این نقاط نیاز داریم. برای یافتن مختصات ، می توانیم از matplotlib استفاده کنیم.
import matplotlib.pyplot as plt
plt.imshow(CannyEdge(image))
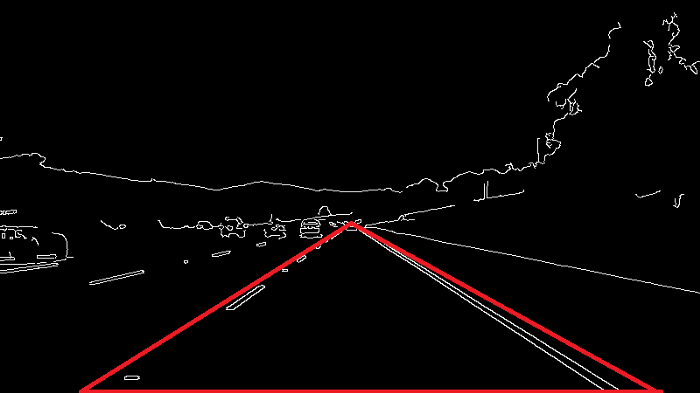
اکنون مختصات منطقه مورد نظر خود را می دانیم.حالا یک تابع به نام region_of_interest ایجاد میکنیم که از یک آرگومان به نام image استفاده می کند.
def region_of_interest(image):
height = image.shape[0]
triangle = np.array([[(200, height),(550, 250),(1100, height),]], np.int32)
mask = np.zeros_like(image)
cv2.fillPoly(mask, triangle, 255)
return mask
ماسک ما دقیقا به این شکل است.در مثلث متغیر ، یک آرایه numpy با رأس مثلث ماسک دار تعریف کردیم. ما می دانیم که یک تصویر یک آرایه از پیکسل ها است ، zeros_like یک آرایه از صفرها با همان شکل تصویر ایجاد می کند. به این معنی که هر دو ماسک و سطر دارای تعداد سطر و ستون یکسانی خواهند بود. اگرچه ماسک کاملاً سیاه می شود چون فقط شامل صفر است. اکنون باید ماسک خود را با مثلثی که به تازگی تعریف کردیم و شامل رئوس میدان دید است ، پر کنیم. ما از تابع fillPoly OpenCV برای پر کردن چند ضلعی روی ماسک استفاده می کنیم. سومین پارامتر در fillPoly رنگ چند ضلعی است.
اما این هیچ معنایی نخواهد داشت. ما باید خطوط خط را مشاهده کنیم. برای انجام این کار می توانیم از تصویر بیتی و عمل بین تصویر عادی که داشتیم و ماسک استفاده کنیم. می دانید که نتیجه باینری تنها زمانی ۱ است که هر دو ۱ باشند. همانطور که می دانید پیکسل های سفید در cannyImage و maskImage هر دو با ۱ مطابقت دارد. بنابراین وقتی AND را روی هر دو پیاده می کنیم خط مسیر را در منطقه مورد نظر دریافت می کنیم. پس بیایید تابع بالا را کمی تغییر بدهیم.
def region_of_interest(image):
height = image.shape[0]
triangle = np.array([[(200, height),(550, 250),(1100, height),]], np.int32)
mask = np.zeros_like(image)
cv2.fillPoly(mask, triangle, 255)
masked_image = cv2.bitwise_and(image, mask)
return masked_image
ا ما فقط عملیات AND را با استفاده از bitwise_and () OpenCV انجام دادیم. نتیجه به دست آمده به شکل زیر است:
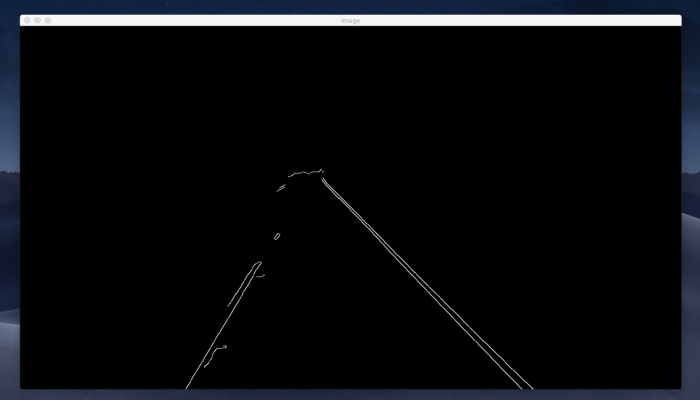
اگر تصویری را که قبلاً با استفاده از Canny Edge Detection گرفته بودیم با این مقایسه کنید ، می بینید که پیشرفت زیادی کرده ایم. در حال حاضر ما یک منطقه موردنظر را تعریف کرده ایم و هر چیز دیگری را که نیازی به آن نداریم حذف کرده ایم.
تشخیص خط- Hough Transform
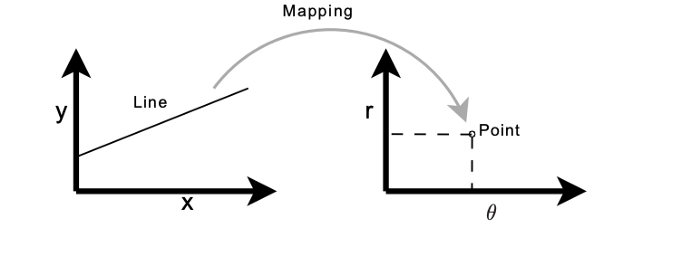
معمولاً خطوط را می توان با دو پارامتر منحصر به فرد نشان داد:
y = m * x + b
با این حال ، این نمی تواند خطوط عمودی را نشان دهد. بنابراین Hough transform از یک معادله استفاده می کند که به صورت زیر است:
r = x * cos θ + y *sin θ
که به نوبه خود می تواند به شکل زیر بازنویسی شود:
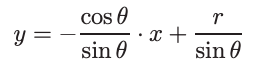
بنابراین فضای Hough برای خطوط دارای دو بعد θ و r است و یک خط با یک نقطه نشان داده می شود.
پیاده سازی در OpenCV:
def display_lines(image, lines):
line_image = np.zeros_like(image)
if lines is not None:
for line in lines:
x1, y1, x2, y2 = line.reshape(4)
cv2.line(line_image, (x1, y1), (x2, y2), (255, 0, 0), 10)
return line_imagecropped_Image = region_of_interest(canny)
rho = 2
theta = np.pi/180
threshold = 100
lines = cv2.HoughLinesP(cropped_Image,rho, theta, threshold, np.array ([]), minLineLength=40, maxLineGap=5)
line_image = display_lines(lane_image, lines)
cv2.imshow('Lane Lines', line_image)
چیزی که دریافت میکنیم:
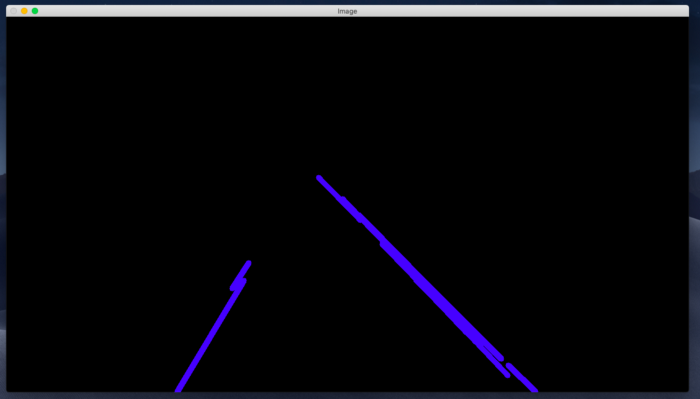
حال اگر بخواهیم این خطوط را در بالای تصویر خود نمایش دهیم ، می توانیم از یک تابع addWeighted در OpenCV استفاده کنیم.
combo_image = cv2.addWeighted(lane_image, 0.8, line_image, 1, 1)
cv2.imshow(“Image”, combo_image)
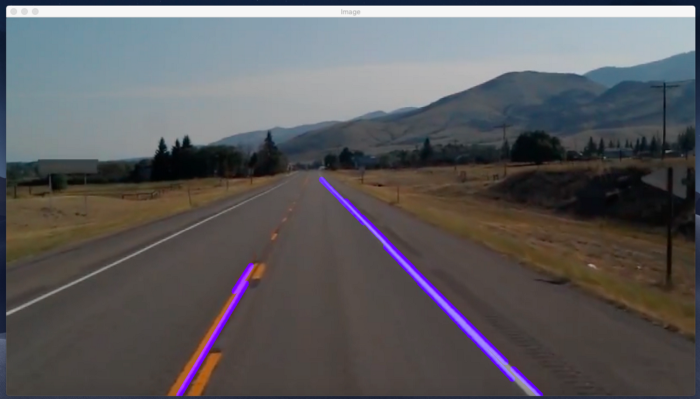
در نهایت ، خطوطی را که در بالای تصویر خط ما قرار دارد ، دریافت کردیم.
حالا بیاید این کار را در ویدئو انجام دهیم. یک ویدئو فقط مجموعه ای از چندین فریم تصویر است.
یک سری تغییر جزیی در کد:
cap = cv2.VideoCapture("test.mp4")
while(cap.isOpened()):
_, frame = cap.read()
canny = CannyEdge(frame)
cropped_Image = region_of_interest(canny)
rho = 2
theta = np.pi/180
threshold = 100
lines = cv2.HoughLinesP(cropped_Image,rho, theta, threshold, np.array ([ ]), minLineLength=40, maxLineGap=5)
line_image = display_lines(frame, lines)
combo_image = cv2.addWeighted(frame, 0.8, line_image, 1, 1)
cv2.imshow("Image", combo_image)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()

کد کامل:
import cv2
import numpy as np
def CannyEdge(image):
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
blur = cv2.GaussianBlur(gray, (5,5), 0)
cannyImage = cv2.Canny(blur, 50, 150)
return cannyImage
def region_of_interest(image):
height = image.shape[0]
triangle = np.array([[(200, height),(550, 250),(1100, height),]], np.int32)
mask = np.zeros_like(image)
cv2.fillPoly(mask, triangle, 255)
masked_image = cv2.bitwise_and(image, mask)
return masked_image
def display_lines(image, lines):
line_image = np.zeros_like(image)
if lines is not None:
for line in lines:
x1, y1, x2, y2 = line.reshape(4)
cv2.line(line_image, (x1, y1), (x2, y2), (255, 0, 0), 10)
return line_image
cap = cv2.VideoCapture("test.mp4")
while(cap.isOpened()):
_, frame = cap.read()
canny = CannyEdge(frame)
cropped_Image = region_of_interest(canny)
rho = 2
theta = np.pi/180
threshold = 100
lines = cv2.HoughLinesP(cropped_Image,rho, theta, threshold, np.array ([ ]), minLineLength=40, maxLineGap=5)
line_image = display_lines(frame, lines)
combo_image = cv2.addWeighted(frame, 0.8, line_image, 1, 1)
cv2.imshow("Image", combo_image)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
کاری که الان میخواهیم انجام بدهیم ، بهینه سازی بیشتر نحوه نمایش این خطوط است. همانطور که می بینیم خطوط زیادی داریم ،کاری که الان انجام می دهیم این است که میانگین این خطوط را میگیریم و یک خط واحد به دست می آوریم.
def average_slope_intercept(image, lines):
left_fit = []
right_fit = []
for line in lines:
x1, y1, x2, y2 = line.reshape(4)
parameters = np.polyfit((x1, y1), (x2, y2), 1)
slope = parameters[0]
intercept = parameters[1]
if slope < 0:
left_fit.append((slope, intercept))
else:
right_fit.append((slope, intercept))
left_fit_average = np.average(left_fit, axis = 0)
right_fit_average = np.average(right_fit, axis = 0)
کاری که ما در این تابع انجام دادیم این بود که دو لیست خالی left_fit و right_fit را مشخص کردیم. left_fit مختصات خطوط سمت چپ و right_fit شامل مختصات خطوط سمت راست است. سپس برای هر خط تکرار می کنیم و هر خط را به یک آرایه تک بعدی تغییر شکل می دهیم و در x1 ، y1 ، x2 ، y2 unpack میکنیم.
x1 ، y1 ، x2 ، y2 نقاط یک خط هستند و هنگامی که نقطه یک خط به ما داده می شود ، محاسبه شیب برای معادله y = mx + b بسیار آسان است.
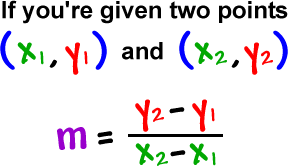
کاری که polyfit انجام می دهد ، این است یک چند جمله ای درجه اول را شامل می شود ، که یک تابع خطی y = mx + b است. قرار است چند جمله ای را با نقاط x & y فیت کند و برگرداند و ضریب برداری شیب را در y-intercept برگرداند.
برای اطلاعات بیشتر https://docs.scipy.org/doc/numpy/reference/generated/numpy.polyfit.html را ببینید.
نکته ای که باید به آن توجه کرد این است که تمام خطوط جاده شناسایی شده در سمت چپ به سمت راست منحرف و خطوط جاده شناسایی شده در سمت راست مایل به چپ هستند. حالا اگر بخواهیم شیب را محاسبه کنیم ، متوجه خواهیم شد که شیب خطوط شناسایی شده در سمت چپ منفی و در سمت راست مثبت خواهد بود. بنابراین ما یک شرط مینویسیم تا بررسی کنیم که شیب به سمت راست است یا چپ. سپس ما با استفاده از تابعی به نام میانگین در numpy میانگین left_fit و right_fit را محاسبه میکنیم. الان به مختصات خطوط نیاز داریم ، پس یک تابع به نام make_points () ایجاد کردیم که مختصات خطوط ما را برمی گرداند.
def make_points(image, line_parameters):
slope, intercept = line_parameters
y1 = int(image.shape[0])
y2 = int(y1*3/5)
x1 = int((y1 - intercept)/slope)
x2 = int((y2 - intercept)/slope)
return [[x1, y1, x2, y2]]
کاری که در اینجا کردیم به شکل زیر است:
y1 = int(image.shape[0])
y2 = int(y1*3/5)
ما می خواهیم طول خطوط ۳/۵ از کل ارتفاع تصویر از پایین باشد . و به همین شکل ، ما مختصات x را هم با استفاده از شیب محاسبه کردیم.
x1 = int((y1 - intercept)/slope)
x2 = int((y2 - intercept)/slope)
تابع average_slope_intercept () کامل شده به این شکل است ، چیزی تغییری نکرده است ، اما یک خط برای برگرداندن آرایه ای از خطوط اضافه شده است.
def average_slope_intercept(image, lines):
left_fit = []
right_fit = []
for line in lines:
x1, y1, x2, y2 = line.reshape(4)
parameters = np.polyfit((x1, y1), (x2, y2), 1)
slope = parameters[0]
intercept = parameters[1]
if slope < 0:
left_fit.append((slope, intercept))
else:
right_fit.append((slope, intercept))
left_fit_average = np.average(left_fit, axis = 0)
right_fit_average = np.average(right_fit, axis = 0)
return np.array((left_line, right_line))
کد نهایی:
import cv2
import numpy as np
def make_points(image, line_parameters):
slope, intercept = line_parameters
y1 = int(image.shape[0])
y2 = int(y1*3/5)
x1 = int((y1 - intercept)/slope)
x2 = int((y2 - intercept)/slope)
return [[x1, y1, x2, y2]]
def average_slope_intercept(image, lines):
left_fit = []
right_fit = []
if lines is None:
return None
for line in lines:
x1, y1, x2, y2 = line.reshape(4)
parameters = np.polyfit((x1, x2), (y1, y2), 1)
slope = parameters[0]
intercept = parameters[1]
if slope < 0:
left_fit.append((slope, intercept))
else:
right_fit.append((slope, intercept))
left_fit_average = np.average(left_fit, axis = 0)
right_fit_average = np.average(right_fit, axis = 0)
left_line = make_points(image, left_fit_average)
right_line = make_points(image, right_fit_average)
return np.array((left_line, right_line))
def CannyEdge(image):
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
blur = cv2.GaussianBlur(gray, (5,5), 0)
cannyImage = cv2.Canny(blur, 50, 150)
return cannyImage
def region_of_interest(image):
height = image.shape[0]
triangle = np.array([[(200, height),(550, 250),(1100, height),]], np.int32)
mask = np.zeros_like(image)
cv2.fillPoly(mask, triangle, 255)
masked_image = cv2.bitwise_and(image, mask)
return masked_image
def display_lines(image, lines):
line_image = np.zeros_like(image)
if lines is not None:
for line in lines:
x1, y1, x2, y2 = line.reshape(4)
cv2.line(line_image, (x1, y1), (x2, y2), (255, 0, 0), 10)
return line_image
cap = cv2.VideoCapture("test.mp4")
while(cap.isOpened()):
_, frame = cap.read()
canny = CannyEdge(frame)
cropped_Image = region_of_interest(canny)
rho = 2
theta = np.pi/180
threshold = 100
lines = cv2.HoughLinesP(cropped_Image,rho, theta, threshold, np.array ([ ]), minLineLength=40, maxLineGap=5)
averaged_lines = average_slope_intercept(frame, lines)
line_image = display_lines(frame, averaged_lines)
combo_image = cv2.addWeighted(frame, 0.8, line_image, 1, 1)
cv2.imshow("Image", combo_image)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
در آموزش های بعدی هم ما رو همراهی کنید:)