
پیش بینی آرتروز زانو با یادگیری عمیق:
سلام، به مجموعه درسهای آموزش پایتون در حوزه پزشکی خوش اومدید!در این مقاله یاد می گیریم که چگونه با استفاده از شبکه عصبی کانولوشن، پیش بینی طبقه بندی اشعه ایکس زانو را تشخیص دهیم و سپس مدل را با استفاده از اپلیکیشن Flask مبتنی بر وب اجرا کنیم.
پس با ما همراه باشید!تصویر زیر درواقع یک نمونه تصویر اشعه ایکس زانوعه که خیلی جاها موارد مشابه اون رو مشاهده کردید. و ما قراره در پیش بینی مون از این نوع تصاویر استفاده کنیم در واقع این تصویر داده ورودی ماست.
اما بطور کلی، مجموعه داده شامل ۱۶۵۰ تصویر دیجیتالی اشعه ایکس از مفصل زانو است که از بیمارستان ها و مراکز تشخیصی معتبر جمع آوری شده. تصاویر اشعه ایکس با استفاده از دستگاه اشعه ایکس PROTEC PRS 500E به دست آمده است. تصاویر اصلی تصویر ۸ بیتی در مقیاس خاکستری هستند. هر تصویر رادیوگرافی اشعه ایکس زانو به صورت دستی بر اساس درجات Kellgren و Lawrence توسط ۲ متخصص پزشکی، برچسب گذاری شده است. در این روش یک رویکرد جدید برای استخراج خودکار ناحیه غضروف (منطقه مورد نظر ما) بر اساس تراکم پیکسل ها توسعه یافته است.
دستگاه اشعه ایکس PROTEC PRS 500E: سیستم سری PRS 500 E از تمام تکنیک های رادیوگرافی در زمینه های ارتوپدی، جراحی و اورولوژی پشتیبانی می کند. در این سیستم واحد اشعه ایکس دارای یک مبدل-ژنراتور کنترل شده با میکروپروسسور از سری PROVARIO HF است . سری PRS 500 E به دلیل گستره کاربردی زیاد، امکانات تقریباً نامحدودی را برای برآورده کردن بیشتر نیازهای بیماران ارائه می دهد.
هدف، ارزیابی عملکرد الگوریتم یادگیری عمیق برای پیشبینی به ازای درجات Kellgren و Lawrence است.
سیستم طبقه بندی Kellgren و Lawrence:
درجه ۰ (طبیعی): عدم وجود قطعی تغییرات اشعه ایکس در آرتروز .
درجه ۱ (مشکوک): باریک شدن فضای مفصلی مشکوک و احتمال استئوفیتی لیپینگ
درجه ۲ (میانه): استئوفیت های قطعی و درجه باریک شدن فضای مفصلی احتمالی
درجه ۳ (در حد متوسط): استئوفیت های چندگانه متوسط، باریک شدن مشخص فضای مفصل و مقداری اسکلروز و تغییر شکل احتمالی انتهای استخوان
درجه ۴ (شدید): استئوفیت های بزرگ، باریک شدن مشخص فضای مفصل، اسکلروز شدید و تغییر شکل قطعی انتهای استخوان.
لینک دانلود مجموعه داده: اینجا
import cv2,os
data_path='/content/drive/MyDrive/Knee-project/Knee-Dataset/'
categories=os.listdir(data_path)
labels=[i for i in range(len(categories))]
label_dict=dict(zip(categories,labels)) #دیکشنری خالی
print(label_dict)
print(categories)
print(labels)
img_size=256
data=[]
label=[]
for category in categories:
folder_path=os.path.join(data_path,category)
img_names=os.listdir(folder_path)
for img_name in img_names:
img_path=os.path.join(folder_path,img_name)
img=cv2.imread(img_path)
try:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
resized=cv2.resize(gray,(img_size,img_size))
# تغییر اندازه تصویر به ۲۵۶ x 256، زیرا ما به یک اندازه مشترک ثابت برای همه تصاویر در مجموعه داده نیاز داریم
data.append(resized)
label.append(label_dict[category])
# اضافه کردن تصویر و برچسب (دسته بندی شده) به لیست (مجموعه داده)
except Exception as e:
print('Exception:',e)
#اگر استثنایی مطرح شود، استثنا در اینجا چاپ می شود. و به تصویر می رود
برچسبهای دستهبندی را یادآوری و اختصاص دهید
import numpy as np
data=np.array(data)/255.0
data=np.reshape(data,(data.shape[0],img_size,img_size,1))
label=np.array(label)
from keras.utils import np_utils
new_label=np_utils.to_categorical(label)
معماری شبکه عصبی کانولوشنال
from keras.models import Sequential
from keras.layers import Dense,Activation,Flatten,Dropout
from keras.layers import Conv2D,MaxPooling2D
from keras.callbacks import ModelCheckpoint
model=Sequential()
model.add(Conv2D(128,(3,3),input_shape=data.shape[1:]))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
# اولین لایه CNN به دنبال لایه های Relu و MaxPooling
model.add(Conv2D(64,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
# لایه کانولوشن دوم به دنبال لایه های Relu و MaxPooling
model.add(Conv2D(32,(3,3)))
model.add(Conv2D(32,(3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
# لایه پیچیدگی سوم به دنبال لایه های Relu و MaxPooling
model.add(Flatten())
# لایه را صاف کنید تا پیچ های خروجی از لایه کانولوشن سوم روی هم قرار گیرند
model.add(Dropout(0.2))
model.add(Dense(128,activation='relu'))
# لایه متراکم از ۱۲۸ نورون
model.add(Dropout(0.1))
model.add(Dense(64,activation='relu'))
# لایه متراکم از ۶۴ نورون
model.add(Dense(5,activation='softmax'))
# لایه نهایی با دو خروجی برای دو دسته
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
خروجی کد بالا:

تقسیم داده ها به دو بخش آموزش و آزمایش
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(data,new_label,test_size=0.1)
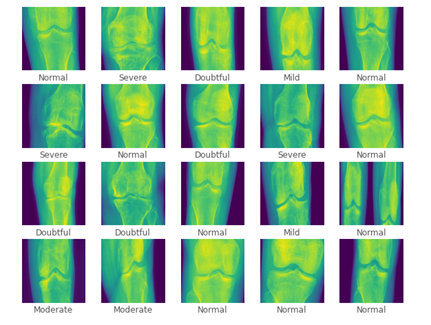
import matplotlib.pyplot as plt
plt.figure(figsize=(10,10))
for i in range(20):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(np.squeeze(x_test[i]))
plt.xlabel(categories[np.argmax(y_test[i])])
plt.show()
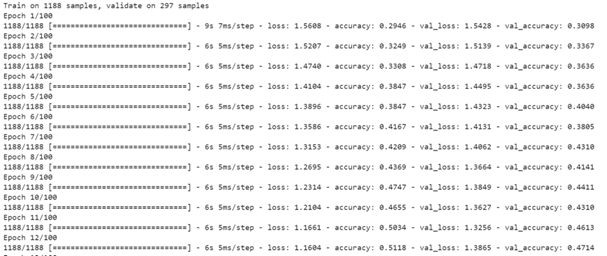
history=model.fit(x_train,y_train,epochs=100,validation_split=0.2)
خروجی بخش آموزش
model.save('model.h5')
from matplotlib import pyplot as plt
# ترسیم دقت و خطای مدل اموزش
N = 100 #تعداد دورهای مدل
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), history.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), history.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), history.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), history.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="center right")
plt.savefig("CNN_Model")
vaL_loss, val_accuracy= model.evaluate(x_test, y_test, verbose=0)
print("test loss:", vaL_loss,'%')
print("test accuracy:", val_accuracy,"%")
X = 32
img_size = 256
img_single = x_test[X]
img_single = cv2.resize(img_single, (img_size, img_size))
img_single = (np.expand_dims(img_single, 0))
img_single = img_single.reshape(img_single.shape[0],256,256,1)
predictions_single = model.predict(img_single)
print('A.I predicts:',categories[np.argmax(predictions_single)])
print("Correct prediction for label",np.argmax(y_test[X]),'is',categories[np.argmax(y_test[X])])
plt.imshow(np.squeeze(img_single))
plt.grid(False)
plt.show()
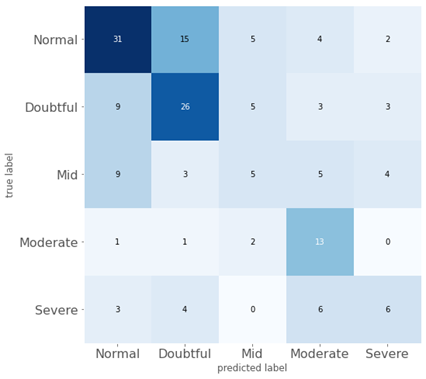
from sklearn.metrics import confusion_matrix
from mlxtend.plotting import plot_confusion_matrix
test_labels = np.argmax(y_test, axis=1)
predictions = model.predict(x_test)
predictions = np.argmax(predictions, axis=-1)
cm = confusion_matrix(test_labels, predictions)
plt.figure()
plot_confusion_matrix(cm,figsize=(12,8), hide_ticks=True,cmap=plt.cm.Blues)
plt.xticks(range(5), ['Normal','Doubtful','Mid','Moderate','Severe'], fontsize=16)
plt.yticks(range(5), ['Normal','Doubtful','Mid','Moderate','Severe'], fontsize=16)
plt.show()
ماتریس سردرگمی:
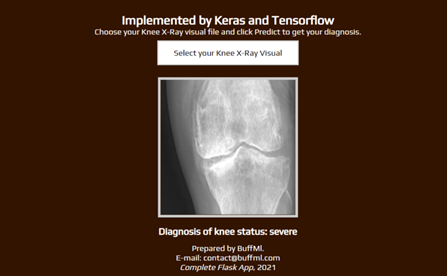
رابط برنامه فلسک

لینک دانلود کامل سورس کد پروژه: اینجا
لینک توضیحات انگلیسی: اینجا