
آپاچی هادوپ چیست؟
یکی از روشها برای پردازش حجم عظیمی از داده ها استفاده از هادوپ است. هادوپ یک چارچوب یا مجموعه ای از نرم افزارها و کتابخانه هایی است که ساز و کار پردازش حجم عظیمی از داده های توزیع شده را فراهم می کند. در مدل پردازشی هادوپ، داده ها در کل شبکه یا کلاستر توسط سیستم فایل HDFS توزیع می شوند و برای پردازش داده ها از مکانیزم MapReduce استفاده میشود.
یعنی پردازش مورد نیاز بر روی داده ها مثل آمارگیری یا یافتن یک الگوی خاص در متن با هر نود محاسباتی ارسال می شود.(عمل نگاشت یا map) سپس روی هر سیستم فایل داده ای پردازش شده و نتایج به شکل استاندارد در آمده و با یک نود محاسباتی دیگر برای تجمیع ارسال می شود. (عمل تجمیع یا Reduce) این عمل با تجمیع تمام نتایج در یک نود و نمایش آن به کاربر به پایان می رسد. در واقع Hadoop را می توان به یک سیستم عامل تشبیه کرد که طراحی شده تا بتواند حجم زیادی از داده ها را بر روی ماشین های مختلف پردازش و مدیریت کند. این مدل، بیش از ده سال، رایجترین مدل پردازشی کلان داده و مبتنی بر اکوسیستم هادوپ بوده است. از کمپانیهای متخصص در زمینه سرویس های هادوپ می توان به MapR ، Cloudera و HortonWorks اشاره کرد.
اجزای اصلی هادوپ
HDFS
مخفف Hadoop Distributed File System و سیستمی است که ذخیره مجموعه بزرگی از دادهها را در سراسر یک خوشه در هادوپ مدیریت میکند.
MapReduce
این روش قطعات داده را از HDFS، برای جداسازی وظایف در خوشه اختصاصی قرار میدهد و تکهها را به صورت موازی پردازش میکند.
YARN
مسئولیت مدیریت منابع محاسباتی و زمان کارها را هم برعهده دارد.
Hadoop Common
هسته هادوپ که شامل مجموعهای از کتابخانهها و ابزارهای کمکی رایج است و از تمام اجزای دیگر هادوپ پشتیبانی میکند.
عیبهای هادوپ
مدل پردازشی MapReduce با وجود مزایای فراوانی که دارد از جمله مقیاس پذیری، تحمل خطا و مدل ساده پردازشی برای تولید برنامه و پردازش داده، دارای دو عیب عمده است :
- اول اینکه این سیستم برای کار با دیسک طراحی شده است و تمام نتایج در مراحل مختلف باید در دیسک ذخیره شوند که خود سرعت پردازش را بسیار پایین می آورد.
- دوم اینکه توابع آماده آن بسیار محدود هستند و بار اصلی تولید برنامه و پردازش داده بر روی برنامه نویسان آشنا با مکانیزم MapReduce است.
معرفی آپاچی اسپارک
در سال ۲۰۱۰ دانشگاه برکلی مدلی جدید برای پردازش کلان داده با نام اسپارک ارائه داد .اسپارک یکی از فعالترین پروژه های بنیاد آپاچی است. آپاچی اسپارک یک Engine بسیار قدرتمند، برای پردازش دادههای بزرگ به صورتِ توزیعشده است که قابلیت پردازش داده ها به صورت موازی روی چندین کامپیوتر به صورت خودکار و همزمان را داراست. اسپارک برای عملکرد سریع طراحی شده است و از رَم (RAM) برای ذخیره و پردازش دادهها استفاده میکند.
اسپارک می تواند عملیاتهایی همچون پردازش دستهای MapReduce-like ، پردازش جریان زمان واقعی، یادگیری ماشین، محاسبه گرافها و کوئریهای محاورهای (Interactive Queries) را بر روی بیگ دیتا انجام دهد. با استفاده آسان از APIهای سطح بالا، اسپارک میتواند با بسیاری از کتابخانههای مختلف از جمله PyTorch و TensorFlow ادغام شود.
مزایای فریمورک آپاچی اسپارک
– تمرکز اسپارک بر روی انجام محاسبات درون حافظه ای است یعنی تا حد امکان و با وجود ظرفیت رم دستگاه، محاسبات درون حافظه انجام می شود. این امر باعث می شود سرعت پردازش داده ها نسبت به هادوپ معمولی در پردازش های دیسک محور تا ده برابر و در پردازش های درون حافظه ای تا صد برابر افزایش پیدا کند که خود بهبود بسیار زیادی را نشان می دهد و برای الگوریتم های تکرار شونده بسیار عالی عمل می کند.
– پشتیبانی آن از انواع توابع مورد نیاز برای پردازش داده ها مانند مرتب سازی، فیلتر کردن، انجام یک تابع روی تک تک عناصر لیست، شمارش عناصر و غیره است که کار برنامه نویس را بسیار ساده می کند.
– آپاچی اسپارک سعی میکند معماری دستهای سفت و سخت MapReduce را انعطاف پذیرتر کند.
– اسپارک به برنامه نویسان اجازه می دهد تا گراف های غیر چرخشی جهت دار و چند مرحله ای (DAGs) بسازند.
– همچنین به jobها اجازه می دهد تا داده ها را برای پرس و جو و پردازش سریعتر در حافظه نگه دارند.
– اسپارک توانایی انجام محاسبات تکراری را دارد.
– MapReduce یک مدل برنامه نویسی برای محاسبات توزیع شده است اما Spark یک سیستم محاسباتی خوشهای عمومی است که از عملیات موازی MapReduce-like استفاده میکند.
– اسپارک علاوه بر “map” و “reduce” ساده، مجموعه ای غنی از تبدیلات توزیع شده را پشتیبانی می کند.
– اسپارک از APIهای سطح بالا (رابط برنامه نویسی کاربردی) در جاوا، اسکالا و پایتون پشتیبانی می کند.
معماری آپاچی اسپارک
معماری اسپارک یک معماری ارباب/برده یا همان کلاینت/سرور بوده و شامل پنج موجودیت اصلی است.
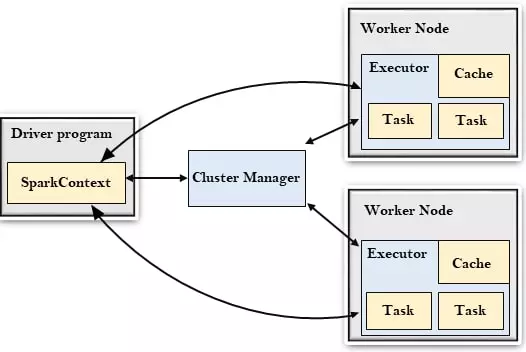
اصلی ترین مولفه اسپارک، برنامه Driver است که اجرای عملیات بر روی RDDها را بین شبکه، توزیع کرده و نتایج را دریافت می کند. Driver از طریق مدیرکلاستر، با worker ها ارتباط برقرار می کند. Worker ها از دو بخش مدیریت حافظه و اجراکننده تشکیل شده است که اجراکننده (executor) وظیفه انجام پردازش ها بر روی RDDها را برعهده دارد.
اجرای یک برنامه اسپارک شامل مفاهیم زمان اجرا، مانند driver ، executor، task، job، stage است. درک این مفاهیم برای نوشتن سریع و کارامد برنامه های اسپارک ضروری است. میتوان گفت driver جریان کار را مدیریت و وظایف را زمان بندی می کند یعنی Task یا وظایف را بین گره های کارگر سرور توزیع کرده و بر آنها نظارت می کند و در تمام مدت اجرای برنامه در دسترس است. stage مجموعه ای از وظایف است که همان کد را اجرا می کنند و هر کدام در زیر مجموعه ای متفاوت از داده ها هستند. executorها مسئولیت اجرای کار(job) را در قالب TASKها و همچنین ذخیره هر داده ای که در حافظه پنهان قرار دارد را بر عهده دارند. یک executor تعدادی اسلات برای اجرای وظایف دارد.
مجموعه داده های توزیع شده برگشت پذیر یا RDD (Resilient Distributed Datasets)
نقطه قوت اصلی اسپارک استفاده از مجموعه داده های توزیع شده برگشت پذیر یا RDD است. تمام داده ها در اسپارک برای پردازش باید به شکل RDD در آیند که البته به کمک توابع خود اسپارک این امر به راحتی امکان پذیر است . RDDها فقط خواندنی هستند و با هر تراکنش جدیدی که روی یک مجموعه داده برگشت پذیر انجام می شود یک RDDجدید ساخته می شود و محاسبات با این مجموعه جدید ادامه پیدا می کند. دو نوع کار می توان روی این مجموعه داده ها انجام داد:
تبدیلات (Transformations): عمل تبدیل یک RDD به یک RDDجدید انجام می دهد. مانند فیلتر کردن و انجام یک تابع سراسری روی تک تک عناصر (Map)
عملیات (Actions): منظور از عملیات، توابعی است که روی یک RDD اعمال می شود و یک مقدار را بر می گرداند. مثلا شمارش عناصر، بیشینه یا کمینه عناصر
نکته مهم در مورد اسپارک این است که هر RDD اشاره گری به مجموعه داده پدر خود به همراه عمل انجام گرفته برای تبدیل را داراست و برگشت پذیر بودن این مجموعه ها هم دقیقاً به همین روال اشاره دارد. چون با داشتن مجموعه داده اولیه و مجموعه تبدیلات انجام گرفته روی آن، می توان به راحتی یک مجموعه را از پایه دوباره ساخت و اگر سیستم به هر دلیلی مجموعه داده فعلی خود را از دست دهد ، به راحتی آنرا با پیمایش زنجیره تبدیلات از اولین مجموعه تا الان، می تواند بازیابی کند. بنابراین RDDها برگشت پذیر هستند.
نکته دیگر درباره RDDها تا عملیاتی روی این مجموعه ها صورت نگیرد یعنی (توابع عملیاتی صدا زده نشوند) عملا تبدیلی هم انجام نمی شود یعنی تبدیلها زمانی انجام می شوند و مجموعه های جدید را تولید می کنند که یکی از توابع عملیاتی روی آنها صدا زده شوند. تبدیلات شامل توابعی همچون map, filter, join و عملیات یا اکشن ها شامل count, collect, save است.
کتابخانه یادگیری ماشین آپاچی اسپارک
اسپارک چهار جزء اصلی را به عنوان کتابخانه درون خود دارد. هر کدام از این اجزا از موتور Fault-Tolerant (تحمل خطا)اسپارک مجزا است که در آن، ما از APIها برای نوشتن برنامههای اسپارک استفاده میکنیم و اسپارک آن را تبدیل به DAG کرده و موتور اصلی آن را اجرا میکند. پس کدهایی که با استفاده از APIهای Java, R, Scala, Python نوشته شدهاند تبدیل به بایتکدهای فشردهای میشوند که در JVMهای Workerها در Cluster اجرا میشوند.
کتابخانه MLlib
MLlib که در بالای اسپارک ساخته شده است، یک کتابخانه یادگیری ماشینی مقیاسپذیر است که از الگوریتمها و ابزارهای یادگیری رایج، از جمله طبقهبندی، رگرسیون، خوشهبندی، فیلتر مشارکتی، کاهش ابعاد، و اصول اولیه بهینهسازی تشکیل شده است. این کتابخانه از قابلیتهایی مثل ارزیابی مدل و ورود دادهها پشتیبانی میکند. همچنین ساختارهای سطح پایین یادگیری ماشین مثل الگوریتم بهینهسازی گرادیان نزولی را فراهم میآورد. تمام این روشها با منظور اجرا کردن این برنامهها در سطح کلاستر اسپارک طراحی شدهاند. در واقع هدف MLlib، مقیاسپذیری و در دسترس قرار دادن یادگیری ماشین است.
Spark SQL
این ماژول برای کار کردن با دادههای ساخت یافته و دارای ساختار می باشد. در واقع اسپارک از این چارچوب برای جمعآوری اطلاعات و چگونگی پردازش دادهها استفاده میکند. این ماژول از ساختار دادههای Parquet, CSV و JSONپشتیبانی میکند.
Spark Core
هسته اصلی و به عبارتی موتور اصلی اجرای پلت فرم اسپارک ماژول Spark Coreاست که همه عملیات ها بر اساس آن ساخته می شوند . عملیاتهایی مانند تقسیم و زمانبدی وظایف ، مواجهه با خطا ، تعامل با سیستم ذخیرهسازی و غیره را انجام می دهد. همچنین Spark Core محل توسعه APIهایی میباشد کهRDDها را تعریف میکنند و RDDها مفهوم اصلی برنامهنویسی اسپارک هستند.
Spark Streaming
مولفه پردازش دادههای جریانی اسپارک اجازه می دهد تا داده های در حال جریان در زمان واقعی پردازش شوند. این جریان داده ها میتوانند فایلهای لاگ ایجاد شده توسط سرورهای وب یا مجموعه داده هایی که حاوی به روز رسانی وضعیت ارسال شده توسط کاربران یک وب سرویس یا ارسال کردن یک پست در شبکههای اجتماعی باشند. همچنین داده ها را می توان از منابع زیادی مانند Kafka ، Flume و HDFS دریافت نموده و سپس آنها را با استفاده از الگوریتم های پیچیده، پردازش و به سیستم فایل ها، پایگاه های داده و داشبوردهای زنده انتقال داد. این بخش، APIهایی را برای تغییر جریانهای داده که با APIهای مربوط به RDDهای موجود در هسته اسپارک همخوانی دارد، ارائه میدهد و این امر موجب تسهیل توسعه برنامه برای توسعهدهندگان و سوییچ بین برنامههایی که دادهها را در حافظه اصلی، بر روی دیسک یا در زمان واقعی پردازش میکنند، میشود.
GraphX
این مولفه یک کتابخانه برای پردازش گرافها و انجام پردازشهای موازی بر روی دادههای گراف میباشد. این ماژول ، RDDها را توسعه داده و ما را قادر میسازد تا گرافهای جهتدار با نسبت دادن مشخصات به هر گره و یال ایجاد کنیم.همچنین GraphX *فرآیند ETL ، تجزیه و تحلیل اکتشافی و محاسبه نمودار تکراری را در یک سیستم واحد به صورت یکپارچه انجام می دهد.
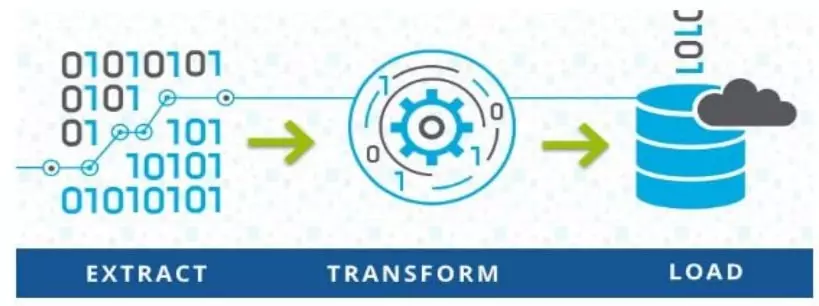
*فرایند ETL چیست؟
این فرایند از سه کلمه Extract به معنای استخراج ، Transform به معنای تبدیل و Load به معنای بارگذاری تشکیل شده است. پس می توان گفت ETL فرآیند جمع آوری داده از منابع داده ای مختلف(Extract)، سازماندهی و یکپارچه سازی آن ها در کنار یکدیگر که این مرحله از عملگرهای مختلفی مانند فیلتر، مرتب سازی (Sorting)، تجمیع (Aggregate)، اتصال(joining)، پاکسازی داده (Cleaning Data)، حذف دادههای یکسان (Deduplicating) و اعتبارسنجی داده ها (Data Validation) استفاده می شود است و در نهایت در یک منبع داده واحد ذخیره میشوند. (Load)
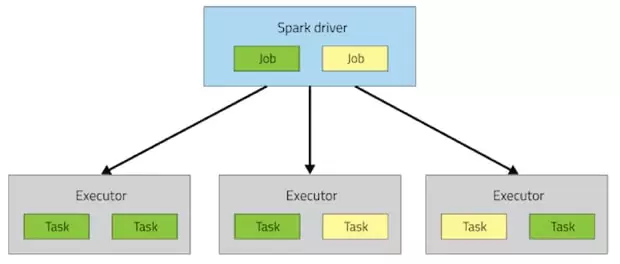
نمونه مثال برای یک job
SparkContext
اولین کاری که یک برنامه اسپارک انجام می دهد ایجاد یک آبجکت از SparkContext است که به Spark می گوید چگونه به یک خوشه دسترسی پیدا کند.
در پوسته اسکالا و پایتون، این متغیر sc نام دارد که به صورت خودکار ایجاد می گردد.
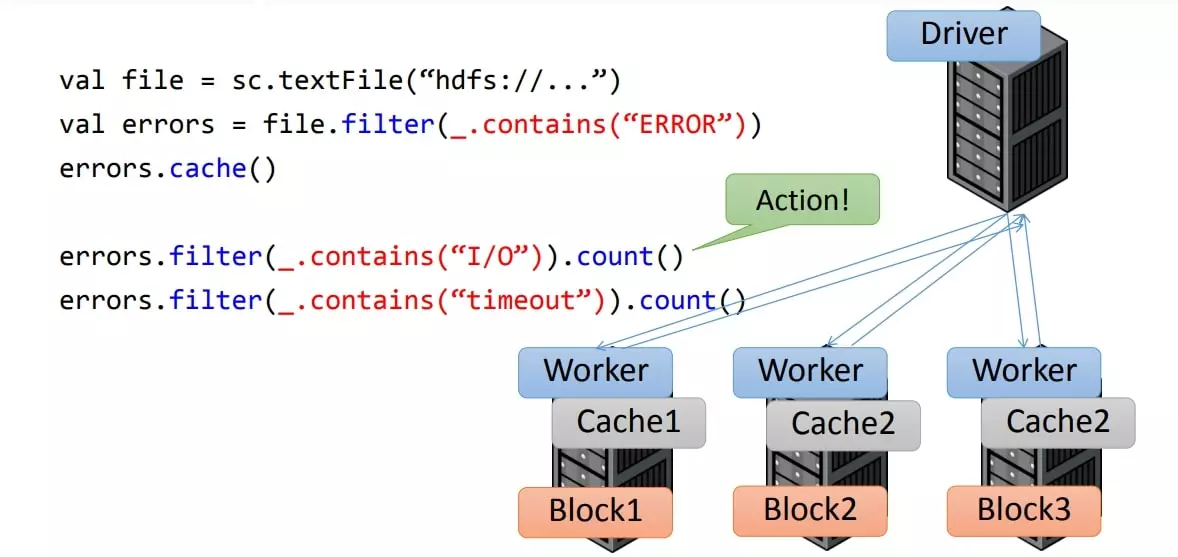
یک نمونه کد اسپارک با پایتون (WordCount)
text_file = sc . textFile(“hdfs://…”)
errors = text_file . filter(lambda line: “ERROR” in line)
# Count all the errors errors . count()
# Count errors mentioning MySQL errors . filter(lambda line: “MySQL” in line).count()
# Fetch the MySQL errors as an array of strings
errors . filter(lambda line: “MySQL” in line).collect()
توضیح کد
در خط اول به کمک کتابخانه اصلی اسپارک اولین RDD با خواندن یک فایل متن در حافظه ایجاد می شود. .خط دوم ، روی RDD اول خطوطی را می یابد که در آنها کلمه ERROR بکار رفته است . با این توصیف، متغیر errors یک RDD جدید است . در دستور سوم، یک عملیات روی errors صورت می گیرد و تعداد این کلمات شمرده می شود. در دستور چهارم ، در مجموعه برگشت پذیر errors خطوطی جدا می شوند که کلمه MySQL در آن به کار رفته باشد و یک RDD بی نام جدید شکل می گیرد که در انتهای دستور، تابع شمارش روی آن صدا زده می شود و خروجی یک عدد خواهد بود و یک RDD بی نام جدید شکل می گیرد که در انتهای دستور، تابع شمارش روی آن صدا زده می شود و خروجی یک عدد خواهد بود. در خط چهارم هم مجدداً RDD مرحله قبل تولید شده و تابع عملیاتی collect روی آن صدا زده می شود و تمام خطاها به صورت یک رشته به کاربر برگشت داده می شود.
PySpark چیست؟
آپاچی اسپارک به زبان برنامه نویسی اسکالا نوشته شده است. PySpark یک رابط برای Apache Spark در پایتون است. با PySpark، می توانید دستورات Python و SQL بنویسید تا داده ها را در یک محیط پردازش توزیع شده دستکاری و تجزیه و تحلیل کنید. علاوه بر این، PySpark به شما کمک می کند تا با مجموعه داده های توزیع شده انعطاف پذیر (RDD) در زبان برنامه نویسی Apache Spark و Python ارتباط برقرار کنید. PySpark از ویژگی های Spark مانند Spark SQL، DataFrame، Streaming، MLlib و Spark Core پشتیبانی می کند.